�����о�ʹ�ø��������źż����������(MWL)��֤����Ч����Ŀǰ�о�ͨ��ֻʹ��һ��ģ̬������MWL�����о���Ŀ����ʹ����ģ̬���������(DNN)�Ը�֪��������(PMWL)���з�����������ģ̬�������������ʵ�������������ģ��MWL���������ɣ�������������Ѷȼ��������˳����֡������������ܵ�1��7���Ѷȵȼ���7������Ѷȡ�����ʹ��LabStreamingLayer(LSL)ͬʱ�ɼ�Ƥ���練Ӧ����������ͼ�������Խ�������Ѫ������������˶�������ʱ��mark��ϢҲ���䵽LSL������ʹ����������ģ̬�����һ������PMWL����֪��������������������м��ں϶�ģʽDNN����������֡�ָ��DNN��Ƶ�������Ҫ���ǣ�ģ�黯��ͨ���ԡ�����ģ�Ϳ�ʵ���ߵȼ�PMWL��ȷ����(0.985���ȼ�)��������Ƶ�ģ�黯���ʣ�ģ�ͼܹ�������������/ɾ��ģ̬������Խṹ�����ش�Ӱ�졣���⣬������ʾ������������ö�ģʽʱ�ı��ָ��á�������ʹ�õ����ݼ��ʹ��빫�����á����ķ�����Frontiers in Human Neuroscience��־��(�������ź�siyingyxf��18983979082��ȡԭ�ģ���˼Ӱ�ṩ����������ط�������ҪҲ�����Ӵ��ź���Ⱥ��ԭ��Ҳ����Ⱥ���)��
�ɽ����������ѧϰ��������Ķ����������⣬��л��ת֧�֣�ֱ�ӵ����������������ź�siyingyxf��18983979082��ȡԭ�ļ�������ϣ���
�������ѧϰ���Ե�ͼ����
����EEG�ź����沿�������������ʶ��
EEGNet��һ��С�͵ľ��������磬���ڻ����Ե���Ի��ӿ�
BRAIN����Ϣ̬�Ե�ͼ��ʾ�˼�ή���Լ������Ӳ��֢����������
���շ���Ӧ�н��붯̬��ģʽ
EEG�Ի��ӿ��㷨
�Ե��źŴ����Ļ���ѧϰ
�Ե��źŽ���Ϳ��ӻ�����Ⱦ���������
����M/EEG�������־��Ԥ��MCI�Ͱ����ĺ�Ĭ��
����EEG�źŵ�����ʶ��
���ڻ���ѧϰ���Ե粡��ѧ���
�߽�ͳ������EEG�źŴ����е�Ӧ��
EEG����ʵ��block��Ƶ�Σ��������
Current Biology���Ӿ�������Ӿ���֪����AlphaƵ���е���
�����Ե���ͨ�������;������������������
�Ե��о���ͨ������Ӿ������Ķ�ģ̬ѧϰ
JAMA Psychiatry��ʹ�û���ѧϰ�ķ���̽�����Ǻʹ�������
Nature neuroscience������encoder-decoderģ��ʵ��Ƥ���
ANNALS of Neurology���з�ָ��������Ի��ӿڿɴٽ��˶�
Nature Biotechnology: EEG����Ԥ���ض�����֢�Ŀ�����ҩ��Ӧ
BMC Medicine���Ա�֢��ϵ�ϰ���Ϣ̬EEG�źŵĶ����ݹ�
SCIENCE ROBOTICS��������ʽ�������ǿ��������
Lancet Neurology��һ�ֹ���̱֫������ʹ��ӲĤ�������Ի�
Lancet���䣺ֲ������ʶ״̬�Ĵ����
NATURE�ӿ���������һ�������EEGpower��ʶ��¶�֢��
EEG����ѧϰ�������������ٴ���Ӧ������
STROKE:���������з综���˶������Ķ���������Ľ�����-��
PNAS:�����Ե������������ڻ��ѳ̶ȿ��Ը��Ƹ���
����ɭ����֪ͼ��EEG����ѧϰ
BRAIN������ѧϰ������EEG�Ŀ����ġ��緽������ʶ
�Ի��ӿ�ѵ���ɳ־õػ����з粡�˵���֫�˶�����
����fNIRS���Ӷ�����������Ա�IJ����(�Զ�vs�ֶ���ʻ��½)
1.����
��������(mental workload,MWL)����ѧ������ѧ�������ܹ�ע��MWL����������Ӱ�죺
1��������֪��Դ��ȡ�����������֪ʶ�������������飬�߶ȸ��廯��
2��������֪��Դ��ȡ���������Ѷȡ���Csikszentmihalyi����������״̬�£����ǻ���ȫ�����������У�������֪��Դ��������֪��Դ�ı���(��)����0.8��1.2֮�䡣��֪��������(PMWL)�DZ��Է�Ӧ��MWL��PMWL�����ұ���ͨ��ʹ��NASA����ָ��(NASA-TLX)����������������������ص���������Դ�����������۱������Ӱ��ʵ��Ŀ��ԣ��һ������Ե�����״̬��������������������������ķ���������һ����ʽ��������(���������״̬)�����Կۡ�ʵʱ�ػ�ȡ���ݣ��������ɱ��Ա��档 ��ǰ�о���ʹ�ö��������ź��ڵ�ģ̬�����·���PMWL�����繦���Խ�������Ѫ������(fNIRS)��Ƥ���練Ӧ(GSR)������(HR)�������źŶ�������Ч��������PMWL�����о���ϵ�ģ̬���ģ̬��Ϣ����PMWL��ȷ����Щ�����ź��ṩ����Ϣ�Է����м�ֵ�����ǻ��ƶ������ѧϰ��ģ̬�źŷ��ೡ���µ����ԭ��ԭ��������ƶ��м��ں϶�ģ̬����(intermediate fusion multimodal network,IFMMoN)��
2.�����뷽��
���Ļ��ڶ�ģ̬������ʹ�����������(DNN)��PMWL���з��ࡣ��ƶ�ģ̬�Ի��ӿ�ʱ���˵��˹ܵ������ԭ����ģ�黯��ͨ����(modularity and generalisability, MG)��Ϊʵ��ģ�黯�����豸Ӧ�������ӣ����ݲɼ���������ܵ�ƥ�䣬�ṹӰ����С������ʹ��������������ģ�黯�Ŀ⣺1.LabStreamingLayer (LSL)��2.TensorFlow��LSL������������ר�����豸����������TensorFlow API����ʵ�����ѧϰģ��ģ�黯��ͨ������ζ�Ÿ���ģʽ�л�õ������ܹ���߷���ȷ�ԣ�Ϊ���ͨ���Ժ�Ӧ���ԣ��ܵ���Ӧ��PMWL���������������Ҳ�����ñ��֡�ͨ���ԣ�MG��Ҫ�����ǵķ��������ܶ����ڻ������豸��ͨ�����ݲɼ�������(��)�Զ�����������Ϊ������ĿӦ�õ����з�������ƶ�����MG���ƶ���ִ�С�
3.����о�
���ǹ��������ģ̬����PMWL: �����Խ�������Ѫ������[fNIRS������������(����)����Ѫ�쵰�ı仯]��Ƥ���練Ӧ(GSR)������(HR)[ʹ�ù�����仯���ͼ��(PPG)����]���۶���(ET)��
3.1.�����Խ�������Ѫ������
fNIRS���Բ�������������/����Ѫ�쵰��Ũ�ȵ���Ա仯�����Թ��ܼ����ڼ䣬������ʹ�õ���Ѫ�쵰�ֲ������仯�����ֱ仯�����ý�����������Ȼ������֯�ض�����ļ��������Ŀǰ����MWL�����fNIRS�������ѧϰ����ѷ�������û����ȷ��ʶ��
����о��ɷ�Ϊ�����ࣺ
1.����֪��(MLP)���ɼ����ܼ����ӵIJ���ɣ�
2.����������(CNN)��
�ݹ�������(RNN) Ҳ�б�ʹ�ã�����Ŀǰ����������MLP�о��ڶ�Ԫ�Լ������������ϱ��ֳ��ܸߵ�ȷ�ԣ����о�����63%���û�ʶ��ȷ��(n=30)���Լ���91%�����㡢��Ϣ��Ԫ���࣬����ǰ�ߵ�ȷ�ʽϵͣ������������������Ȼ���
Tanveer����ʹ��������ģ�ͣ�һ����������ȫ�����ܼ����DNN������������Beer-Lambert�⼫�ܶȣ�һ���Ǿ������������㡢�����ܼ����CNN�����ڸ�ͨ���ļ����ͼ���۲��Ԫ��������ʧ�����DZ����Ԫ�����ȷ��Ϊ99.3%��CNN��Ч����ѡ�Daegazany���˽�MLP����5-class�˶����ﵽ80%���ϵ�ȷ�ȣ���������ĺô���û�ж����ݽ����κ�Ԥ/��������˸÷���Ҳ����������ע�����ķ��࣬��Ϊ��ʱ���������ݲɼ�����(Ԥ)������������Ϊ��ʵ����һ�㣬����ʹ��������ȫ���Ӳ㣬ÿ����10,000����Ԫ�������൱���ӡ�
3.2.������仯���ͼ����Ƥ���練Ӧ
PPG��һ�ֲ���Ѫ����֯Ѫ�����仯�Ĺ�ѧ������Ѫ�����仯������ֱ����أ����PPG�����ڲ���HR��HR�����ԡ���������Ȳ���ֵ��Biswas������HR���������дﵽ95%���ϵ�ȷ�ʣ�����ʹ�����������㡢���������ڼ���(LSTM)�㡢һ���ܼ�����㡣
GSR���뽻����ϵͳ��֧����ص�Ƥ���練Ӧ��ͨ�����ڲ�����С���֪���ѡ�Sun����ʹ��LSTM-CNN�������ʶ�������������ﵽ�ߴ�74%��ȷ�ʡ�
PPG��GSR��������ȡ���������ڷ��࣬��ô���ĺô��Ǽ������������ˣ���������Ҳȥ���˿���������DNN����ģ̬�ںϵ�������������������ȡ��PPG��GSR����״Ҳ����ʹ��ȫ���Ӳ���������
3.3.�۶���
ET�ɻ�ȡһ�������κ�ʱ��鿴��λ����Ϣ�������������������Ӿ�����ʾ��ص���Ϣ������ET���ݵ�ѵ���������߶�������ʹ�õ�������˱��ڲ���������о���ȷ�ȡ�Louedec����ʹ��CNNԤ�����������Ϸ������ͼ��ʹ��ģ�ͻ���VGG16��������������������ںϲ㡣Krafka����Ҳʹ�þ����㲢��ȫ���Ӳ��ϣ����Ǹ���������沿����(�����沿λ�á��������Լ�ȫ��)�������ӡ�ET����ͨ��ʹ�þ�������࣬������Ŀ�꣬��Ϊ���Ƕ����ݵĿռ���������Ȥ��
3.4.��ģ̬�ں�
�����������߶�������ʹ�õ�����ģʽDNN�����Ҳ���ǡ�Ramachandram��Taylor����ȶ�ģ̬ѧϰ�ع����ƶ��˶�ģ̬���ѧϰ�ļ����ؼ����أ�
1.��ʱ�ں���Щģ̬��
(1)�����ں�/���ݼ��ںϣ�����������ԭʼ���ݣ����������������硣
(2)�м��ںϣ�ʹ�ø��ֲ㽫����ӳ�䵽�ϵ�ά�ȣ�������������֮���ij���ط������ںϡ�
(3)�����ںϣ���������С����Ķ���������
��Karpathy������֤���ں�ʱ���ѡ�������ģ����Ҷ�ģ�ͱ����о�Ӱ�졣
2.�ں���Щģ̬��
�����������ݶ������ڷ��࣬������Ч�ij̶�Ҳ��ͬ��
3.��δ���ȱʧ��ģ̬�����ݡ�
����ȱʧ���ܴ������ص����⣬������ʵʱ�����С�
�����ںϲ�����MG������Ϊ����Ҫ�������������������һ��һЩԭ��ᵼ��Ӧ�ó�����ֶ�����⣺1.��ͬģ̬����ʹ�ò�ͬ�����ʣ�2.�豸��ά�ȿ��ܲ�ͬ��ʱ��/�ռ�ά�ȵ��������ܶ�ʧ��3.�����ںϽ������������͵�ͬһ������ȴ����������������ģ̬�������ݲ��������仯ʱ����������ڲ����״��Ҫ���µ�����
�����ںϷ���ģ�黯��Ҫ��������ͨ���Ե�Ҫ�������ں�����/ɾ��ģ̬����(modality network, MNet)���迼������MNet�������������Ҳ����������ͬʱʵ�ֶ�ģʽѧϰ����Ϊģ̬֮��û����Ϣ������
�м��ں������������ģ�黯MNet����ЩMNet�ڸ��Ե��������ã�����/ɾ��ģ̬Ҳ�ܼ��м��ں������MG����
3.�̼�����
ʵ��Ҫ���Խ����������(zebra puzzle)�������������������⣬��ʾ�Ļ����Ͻ��������������������Ѷ��ɸ�������ʾ���������ƽ����ʾ��������ͼ1ʾ����������⣬�����Ѷȴ����dz����������dz�������������������Brainzilla���о����ش�ÿ�������Ҫ������Ϣ���ɣ�����������Ϊ�������Ѷȣ����ִ�1��7��7������Ѷȡ���Щ��������ѵ���ڼ�������ǩ�����������˳����ȫ������̼����ֹ�����LSL���ɼ����ݣ�����ÿ�β���ʱ��mark�����Բ���Ϊ(ȡ��)ѡ����ʾ��(ȡ��)ѡ��𰸣���¼����ID������ʱ��㡢�������͡�����ID������״̬(��ȷ������ȷ���Ѽ��)������ʱ����������ݷֶΡ�
ͼ1.�������⣬�����·���һЩ���������������������ԺͶ���(boy)��һ��ʾ����������Joshua��ijһ��Ԫ��ѡ������һ������������Ԫ��ļ�ͷ�������õ�Ԫ�������ѡ�
[��: ����1962�꡶������ʵ�һ����������]
1.���嶰���ӡ�
2.Ӣ����ס�ں췿���
3.��������������
4.�̷�������˺ȿ��ȡ�
5.�ڿ����˺Ȳ衣
6.�̷��ӽ���������ɫ���ӵ��ұߡ�
7.��Old Gold�����̵�������ţ��
8.�Ʒ�������˳�Kools�����̡�
9.�м�ķ�������˺�ţ�̡�
10.Ų����ס�ڵ�һ�䷿�ӡ�
11.��Chesterfields�����̵���ס����������˵ĸ��ڡ�
12.��Kools�����̵���ס���������˵ĸ��ڡ�
13.��Lucky Strike�����̵��˺ȳ�֭��
14.�ձ��˳�Parliaments�����̡�
15.Ų����ס����ɫ���ӵĸ��ڡ�
ͨ�������ɵ�:
4.����
��ļ23�����ԣ�11�����ԣ�12��Ů�ԣ�ƽ������24.7��(20-57�꣬SD=9.8)��һ��������Ϊ����������ų�������ʹ��Sonaϵͳ��ļ���ԣ����������ش�ѧ�ı����ƹ���������ͬʱ����Ҳͨ���罻���������ļ��ʵ��õ������ش�ѧBMSѧԺ����ίԱ����������б���ǩ������֪��ͬ���顣
5.���ݲɼ���ͬ��
����������ͬһ���ò����ıʼDZ���������ʽ����ͼ�¼����ģ̬���ݲɼ�ʹ�ã�1��Shimmer3 GSR+������GSR��PPG��2��TobiiPro X3-120������ET��3��Brite24������fNIRS���ݡ��豸�ɼ�����ʵʱ���͵�LSL��ʹ��LabRecorder�����ݼ�¼��ÿ�����Ե�XDF�ļ��У�Ȼ��ʹ��PyXDF�����ݵ���Python��PyXDF���Զ����ָ��������յ��IJ����ʣ���Ҫʱ��������ȥ�������������ǻ��ֶ����������ͬ�������ȷ����ģʽ������¼�ƹ����ж��롣����ѡ���������л������˼���ͬ����飬��6.1.����ѡ��
����ʹ��Thales HBAʵ���ұ�д��Ӧ�ó���ԭʼGSR��PPG��Shimmer3 GSR+��ʽ���䵽LSL�����ݲ�����Ϊ256Hz��TobiiPro X3�C120������ʹ��Tobii Pro SDK��PyLSL�������Զ���pythonӦ�ó�����ʽ���䡣ET������120Hz�IJ����ʴ��䣬����˫�۵�x��y���ꡣfNIRS����ʹ��Oxysoft 3.2.51.4 �� 64��Brite24������ͨ��27����������10Hz������756��853nm��ͨ������Beer-Lambert��O2Hb��HHb���ݴ�Oxysoftӳ�䵽LSL���⼫ģ���ͼ2�����ݴ����ͼ3��
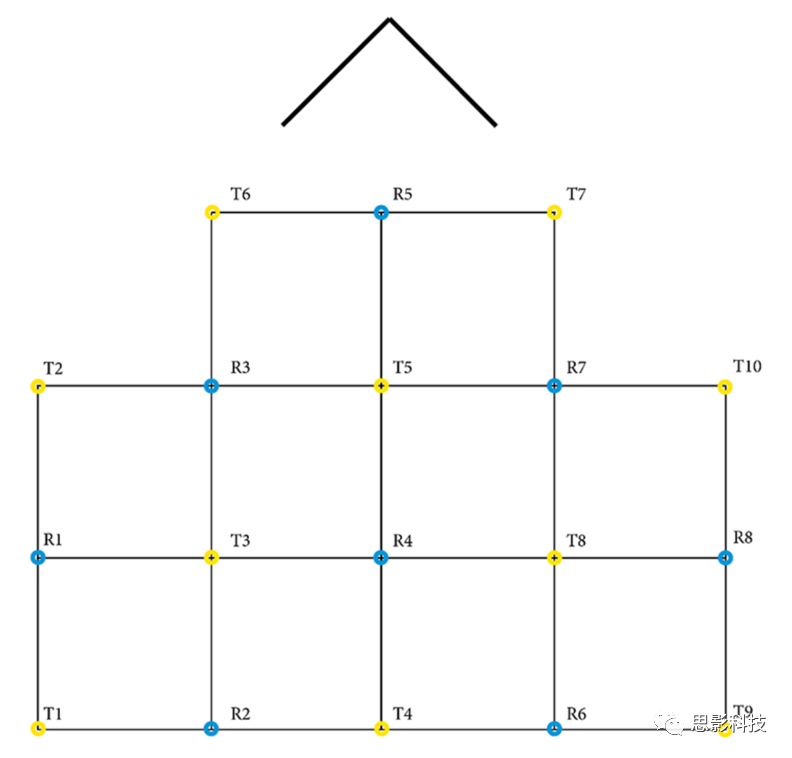
ͼ2.fNIRS�⼫�ֲ���ÿ��������(T)�ͽ�����(R)���γ�һ��ͨ��������10����������8����������27��ͨ������ͷ�������Եı��ӡ�
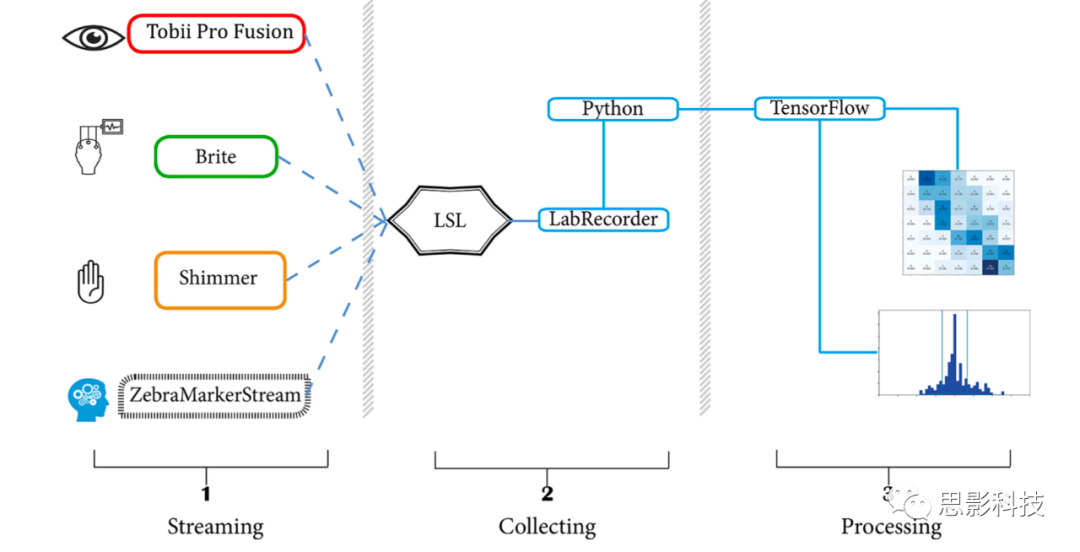
ͼ3.ʵ�����ã����Ϊ������������Tobii�۶������ݡ�Brite fNIRS���ݡ�Shimmer GSR��PPG���ݡ����������mark�����߱�ʾ��LSL����ʽ���ӣ��м䲿�ֵ�LabRecorder��XDF��ʽ��¼���ݣ��Ҳಿ����ʾ�Ѵ������ݵ����ʾ����
6.ģ���Ż�
6.1.����ѡ��
���ݸ��ݰ���������������markѡ������ѡ���������Ҫע�⣺
1.���Կ�������ѡ������ʱ��mark���ܿ��úܽ���������Щmarkѡ������ݻᲿ���ص���
2.��������ᵼ�²�������ȱʧ��
Ϊ�˽����Щ���⣬����ʹ�ò���������ȷ�����õ�mark������ȥ��ʱ�����ȫ��ͬ��mark(���������豸ʱ���Ư�ƺ�/�����ݶ�ʧ)�������������ļ�ͳ������(���ֵ��������ֵ����Сֵ��)���鿴�ֶ����ݵ�����������������������������Ǹ�������ʵ��������ݣ�����û���Ƴ���Щ������
ȷ��mark��ѡ��markǰ8�������(ѪҺ����ѧ��������Ԫ���ʼ5-8s����ַ�ֵ�����Եij�˼������֪��/ѡ����ȷ��֮ǰ)��ÿ�������½�һ����������mark��CSV�ļ��������ĸ�ͬ�����ݣ�fNIRS��GSR��PPG��ET��������ǩΪ����������Ѷȡ���Щ���������ӵ�TFRecord�ļ��У����ļ������������(���ϴ���������Ͳ��)ͬʱӦ�����������ݡ����ݼ�����doi: 10.4121/12932801�ҵ���
6.2.ģ��
ģ��ѡ���м��ںϣ��������������ģ�͵�Ӧ���ԣ�������ģ̬��������������ͬʱ����MG�����м��ںϵ�ģ�ͼܹ���ÿ��ģ̬��һ����������/MNet��һ��Head���缯������MNet�����������ַ���ʵ��MNet��Head���磺1.�������ף�2.�������ܼ����Ӳ㡣
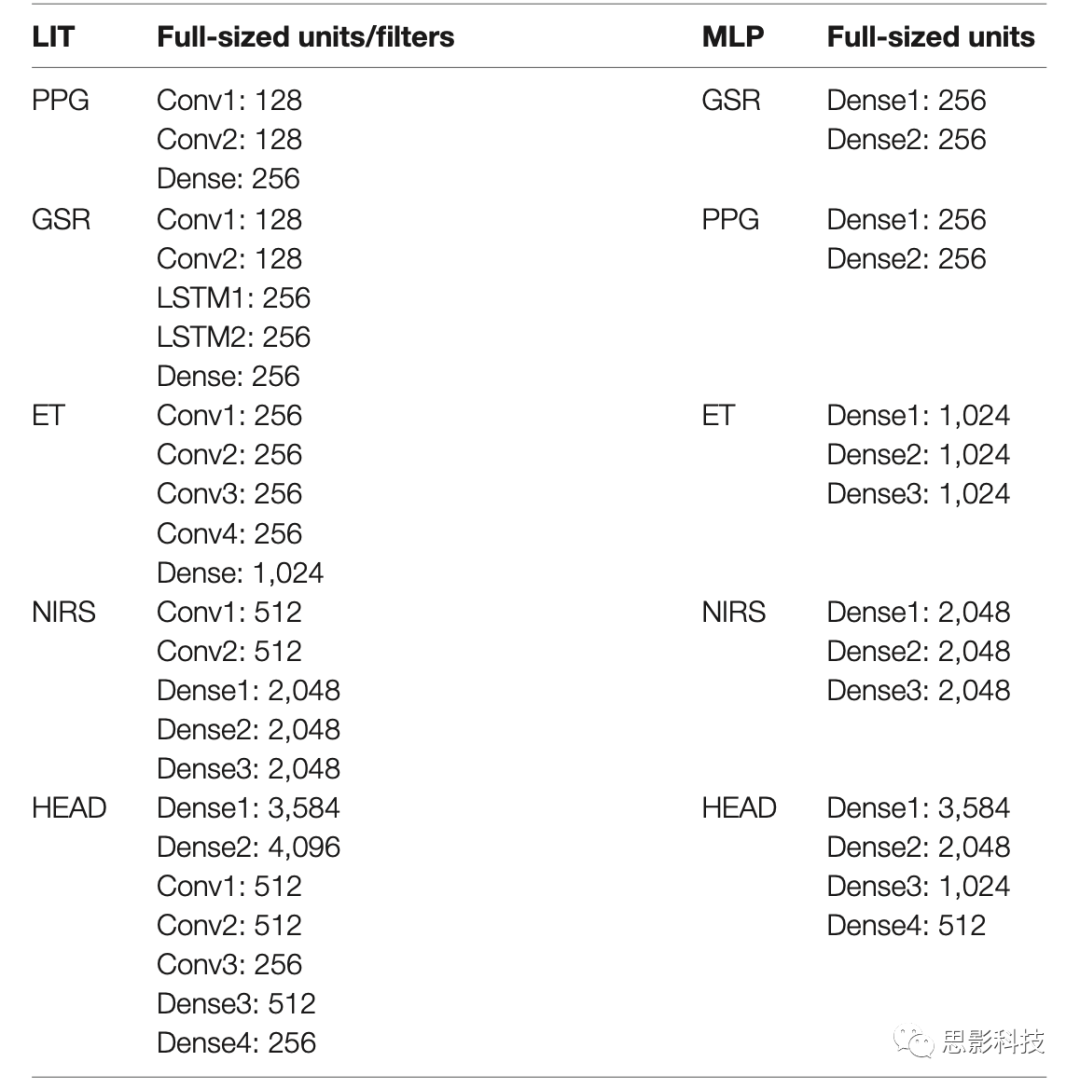
�����������õ�ģ�����ĸ��Զ���MNet��ÿ��ģ̬һ������һ���Զ���Head���硣PPG MNet��������������ɣ�GSR MNet�����������������LSTM����ɣ�ET MNet���ĸ���������ɣ�fNIRS MNet������������������ܼ�����ɡ���Head�ں�֮ǰ������MNet��ͨ�����Ե��ܼ����Ӳ��ڵ�ά�ռ��б�ʾ���������ס��ܼ�����ģ�͵Ľṹ�Ͳ��ͼ4��5��ģ�͵IJ��ÿ��ĵ�Ԫ/��������������1��ͨ���������������ػ�ʹ��������ȶ�������ģ�Ͷ�������һ����С�����ģ�ͣ�ÿһ�����һ��ĵ�Ԫ���������Դ˹۲���������С��Ч�����ɴˣ����ǹ����ĸ�ģ�ͣ�MLP(���ܼ�)��S_MLP(С�ͣ����ܼ�)��LIT(����)�� S_LIT(С�ͣ�����)������ģ����ͬһ�����ݼ�ѵ����
����ʹ�����ֲ�ͬ�ı�ǩ��
1.�����Ա���������Ѷ������类��1��������3���Ѷ�Ϊ6����ô����3���������������ϱ���1������6�ı�ǩ��ʹ�ù�ʽ������ת��Ϊ0��1֮���ֵ������/7������1��Ӧ�ڱ�ǩ��0��������2��Ӧ�ڱ�ǩ��0.1667���ȡ�����ģ��ʹ�þ���Sigmoid������ĵ��������Ԫ��Ԥ���ǩ����0��1֮�䡣Ϊ��֤�ּ�ȷ������Ԥ���ǩ����ʵ��ǩ֮���ƽ������������0.1667������Ԥ���ǩΪԤ��Ĺ������ɵȼ�(level of workload, LoW)
2.���Ա����ƽ���Ѷȣ�ÿ������һ����ǩ����ʽת��ͬ�ϡ����ֱ�ǩ���ڶԱȸ�����Ⱥ���ǩ�ķ���ȷ�ȡ�ģ��ͬ��ʹ�þ���Sigmoid������ĵ��������Ԫ��Ԥ���ǩ����0��1֮�䡣Ԥ�����ͨ��ֱ��ͼ���ӻ������ֲ���������Ӧ���㸽����խ��˹�ֲ���
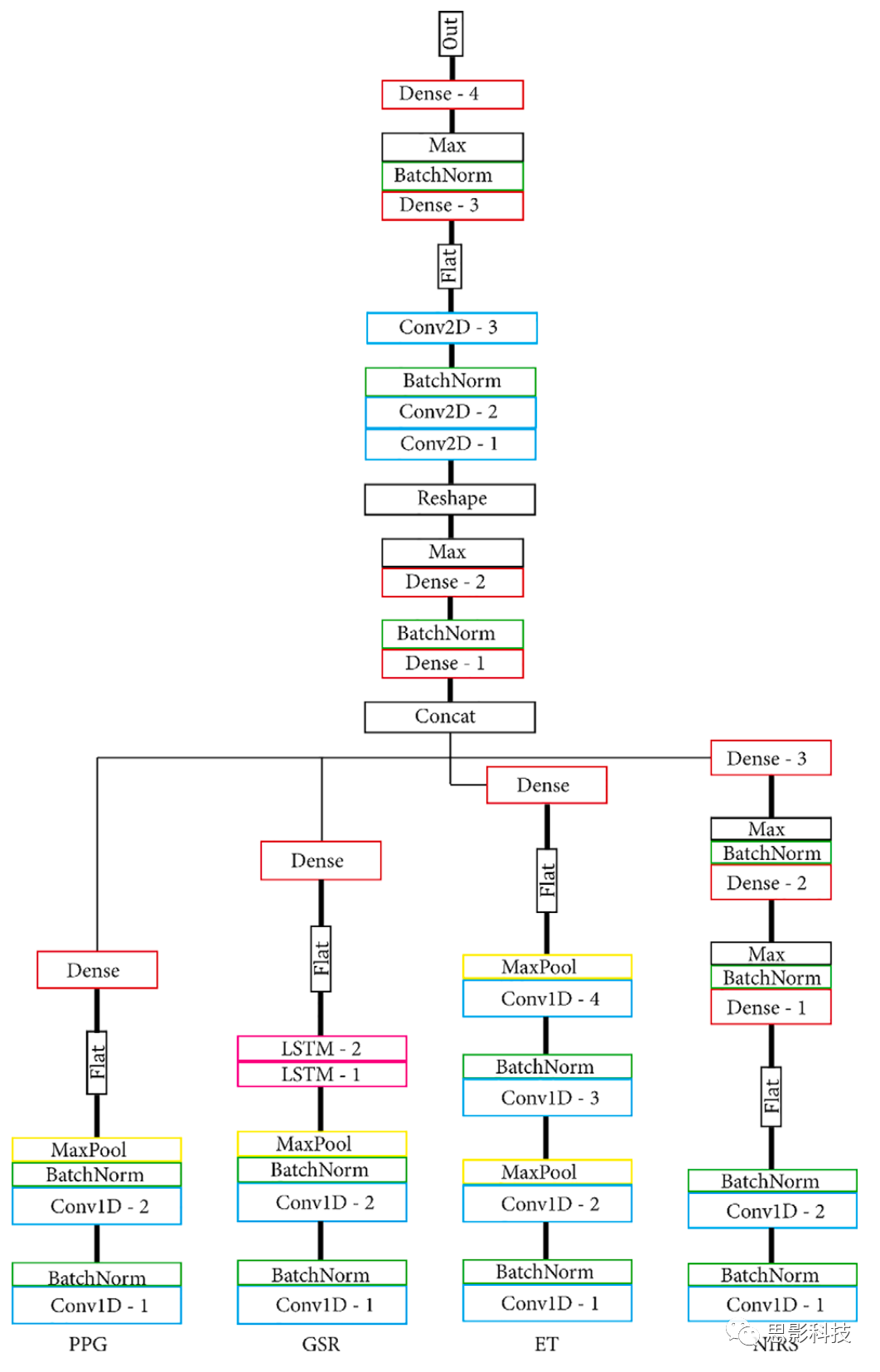
ͼ4.(S_)LITģ�͡�����MNet����һ��Head���磬Head�����ں�֮ǰMNet�ڵ����ܼ����Ӳ㱻չƽ���ڵ�ά�ռ��б�ʾ��
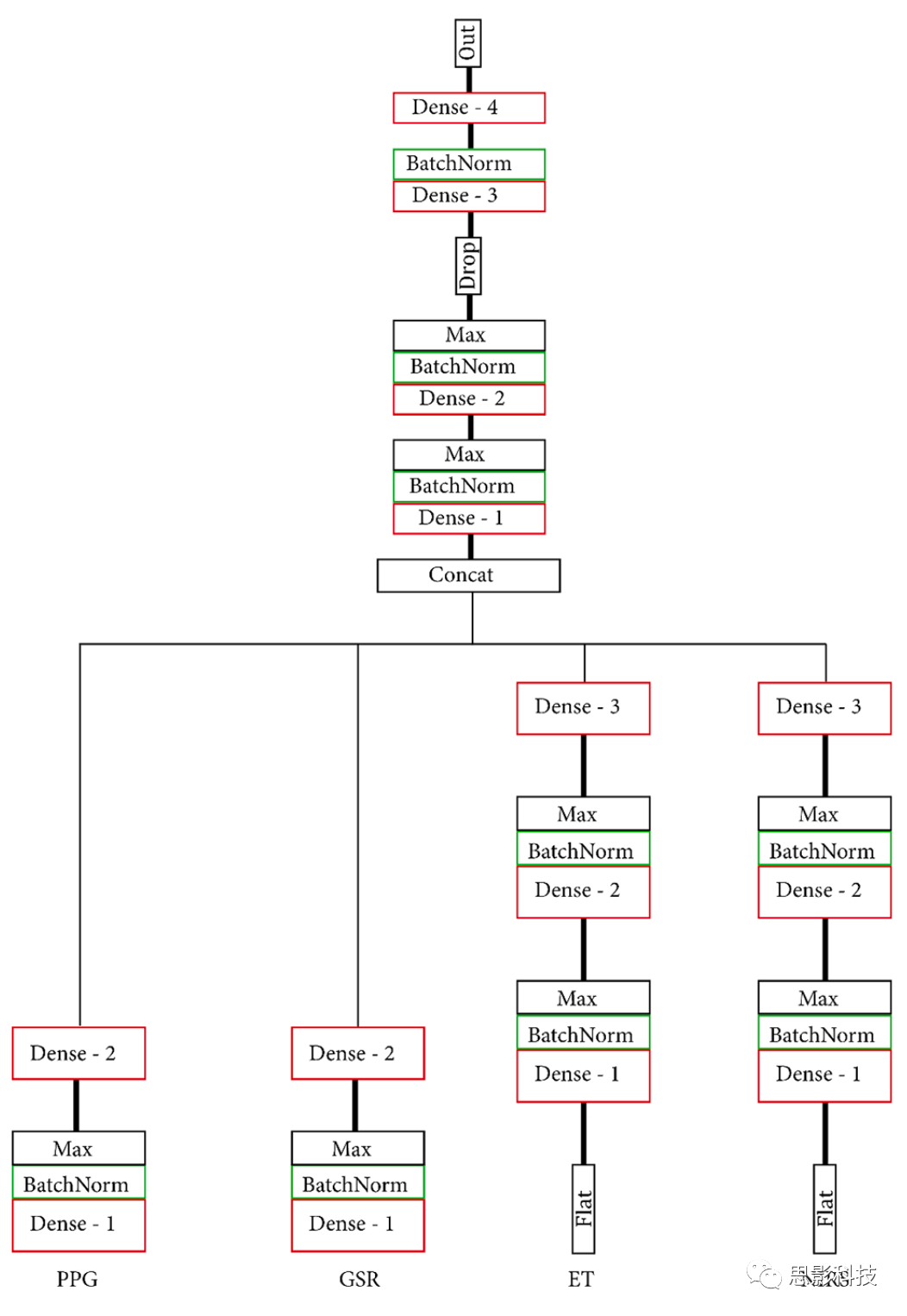
ͼ5.(S_)MLPģ�͡�����MNet����һ��Head���硣MNet��Head�����ܼ����ӵIJ���ɡ�
��1.ģ�͡����Լ�ÿ��ĵ�Ԫ/������������LITָ��������ģ�ͣ�MLPָ�������ܼ����Ӳ��ģ�ͣ�������ʾȫ�ߴ�ģ�͵���Ϣ����ߴ�ģ��ÿ�㵥Ԫ/�������������롣
6.3.�������Ż�
����������ϼ����Ӱ����ģ�ͱ��֡�����ʹ��Optuna������һ����Դ��define-by-run API���������������ٵ����ò��������ռ䡣����ʹ��Ĭ�ϵ�Tree-structured Parzen Estimator����ѧϰ�ʡ�dropout�Ͷ�����ʹ�þ���������ģ�ͱ��֡����ǹ���20��trial��ÿ��trial����һ��5�۽�����֤�������ݼ��ֳ��ĸ�ѵ������һ�����Լ���ÿһ�۶�����в�ͬ�IJ�֣���ѵ��һ����ģ������ֹ����ѵ����ģ�ͱ�¶���������Ż���Ŀ������С��Ԥ���ǩ����ʵ��ǩ��ƽ�����졣��һ���Ż�ѧϰʹ��Smith��������1Cycle Policy��ѧϰ�ʲ��ԣ���������/���ٽ�������״��ѧϰ������ֹ����ֲ���Сֵ������ʹ���ڳ������Ż��ڼ䷢�ֵij�����ѵ��������ѵ�ģ�ͣ�ѵ���ڼ����ݼ�������Ϊ90-10%��ѵ��-���Լ�������ѵ�����ڵ���NVIDIAGeForce GTX 1080-Ti GPU����ɣ�������ϸ��Ϣ��doi��10.5281/zenodo.4043058��GitHub1�ϵĴ��롣
7.���
7.1.����
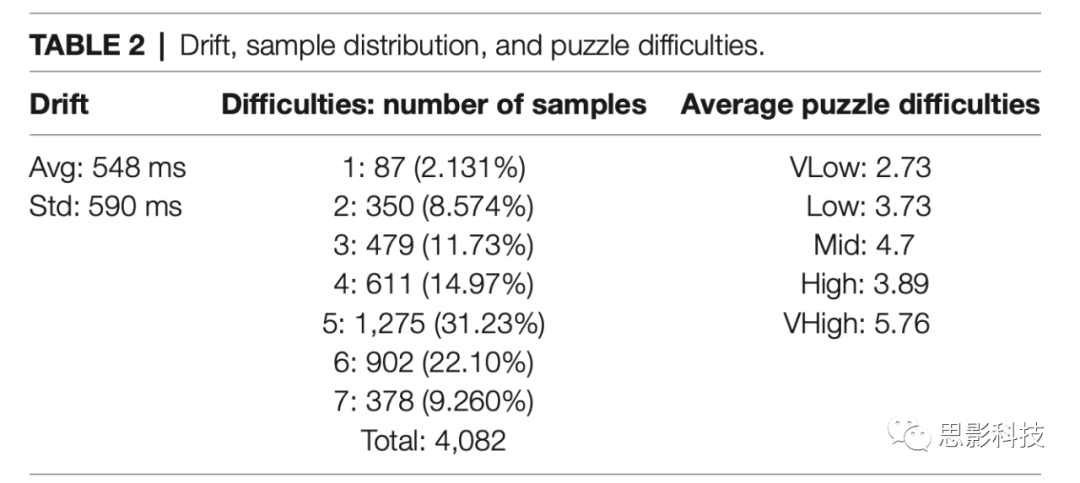
��������Ϊ4082��ƽ��ÿλ����185.5������(77-345��)����2�п��Կ��������Ѷ������ķֲ������������������Ѷ�Ϊ5/7�������6/7�����Ǻ�����Ϊ���������(1/7)������(7/7)�ġ�ʹ��Cronbach's alpha������ǩ��һ���ԣ����������Dz����alphaΪ0.74�����豻�Ա����Dz����alphaΪ0.97��
��2.�����ֲ����ڶ���Ϊ���Ա���7���Ѷȵȼ��и��Ѷȵ�����������������Ϊ��ͬ�Ѷ�������Ѷ����־�ֵ��
7.2.�����ǩģ�ͱ���
����ʹ��Optuna��������������10��trial��һ��ʹ��MLP��LITģ�ͣ�һ��ʹ��S_MLP��S_LITģ�͡����3��ʹ��MLPģ��ʵ�ֵ���ѱ�����Ԥ�����ʵ��ǩ��ƽ�����Բ���Ϊ0.1892(ת��ΪPMWL 7������Ϊ1.13LoW)��5�۽�����֤��ѵ��ʱ��(ÿ��25��epoch)ԼΪ40���ӡ�LITģ�͵���ѽ����0.1978(1.19LoW)��ѵ��ʱ��Լ70���ӡ�S_MLP��0.1642(0.985LoW)����Ҳ�������ռ���ȡ�õ���ý����ѵ��ʱ��Լ25���ӡ�S_LITģ�͵���ѽ����0.1681(1.009LoW)����ѵʱ��Լ43���ӡ�
��3.��trial�����ģ�͡�Ԥ��-��ʵֵ���졢��ӦLoW��ѵ����ʱ
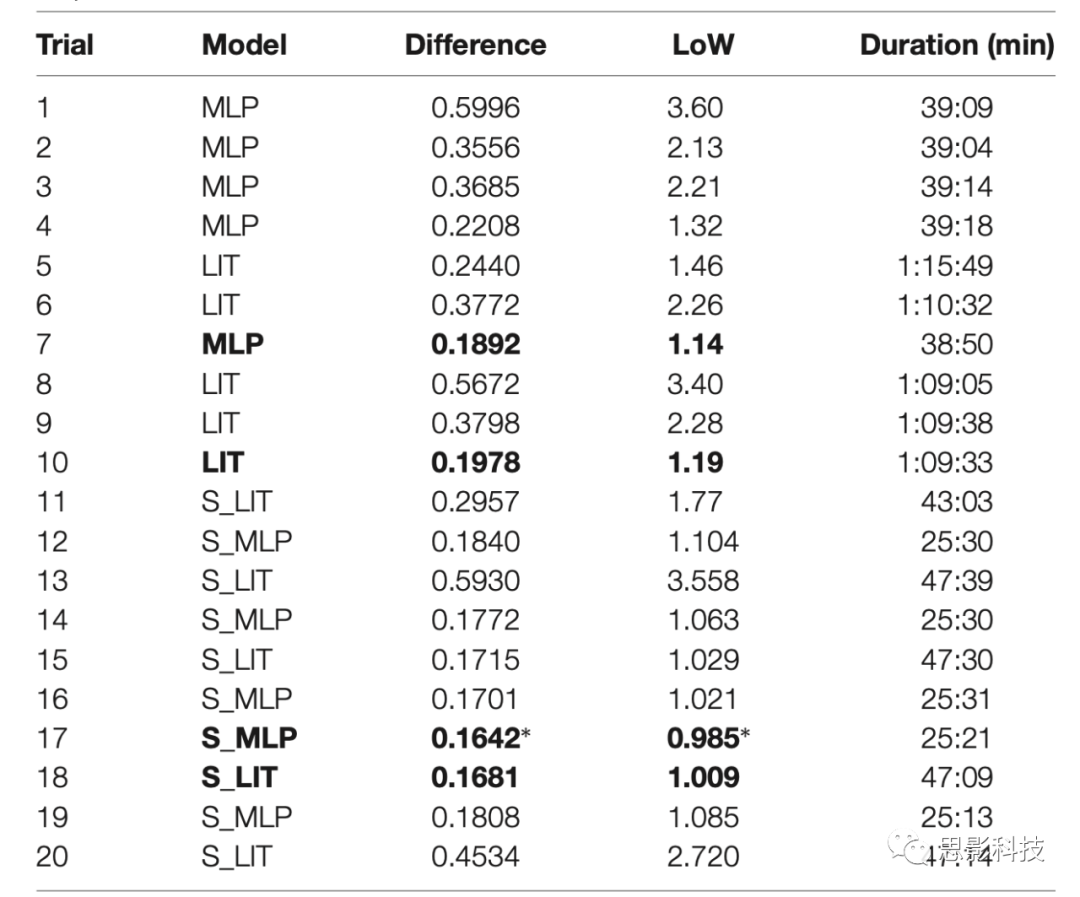
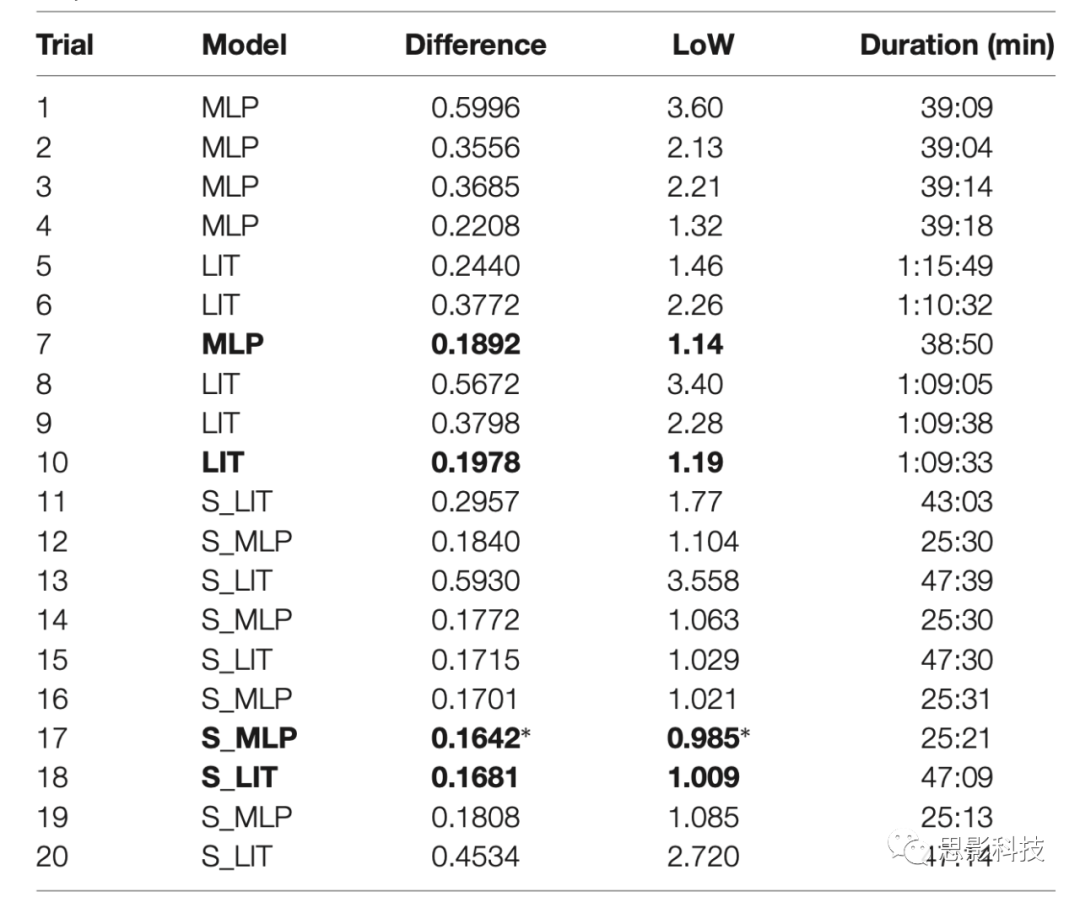
��ͼ6��������õ�ģ��Ԥ���63.6%������1��LoW֮�ڣ�72.7%������1.5��LoW֮�ڣ�Ԥ�����ʵ��ǩ�IJ���ֲ��� = 0.033���� = 0.233���ֲ��ľ�ֵ�Դ����㣬����ζ��ģ�����߹����ԵĹ���������ͼ7������������ʾģ�����ȷ����ı�ǩ��0.6667����������Ӧ�Ѷȵȼ�Ϊ5���ӻ�����������ƶϷ�������ȷ��Ϊ32%�������ڻ���ˮƽ��һ�����7��Ŀ���ǩ���������������ȷ����14%�������������ǩ������ȷ����ô��������ȷ��Ϊ77%������������ı���Ϊ3/7(43%)��
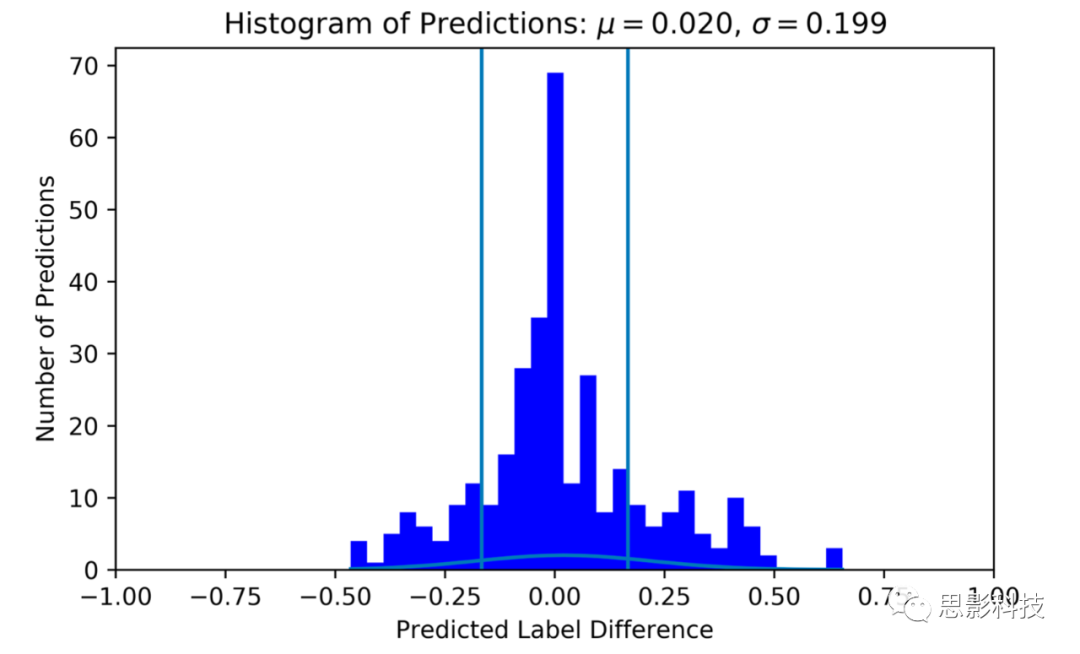
ͼ6.�����ǩ��Ԥ��-��ʵ��ǩ����ֱ��ͼ����ʵ��ǩ����Ϊ0����ֱ�߱�ʾ-1/6��1/6(һ��LoW)��������Χ��Ԥ����Ϊ��ȷ����ֱ��ͼʹ��S_MLP���3��trial17��
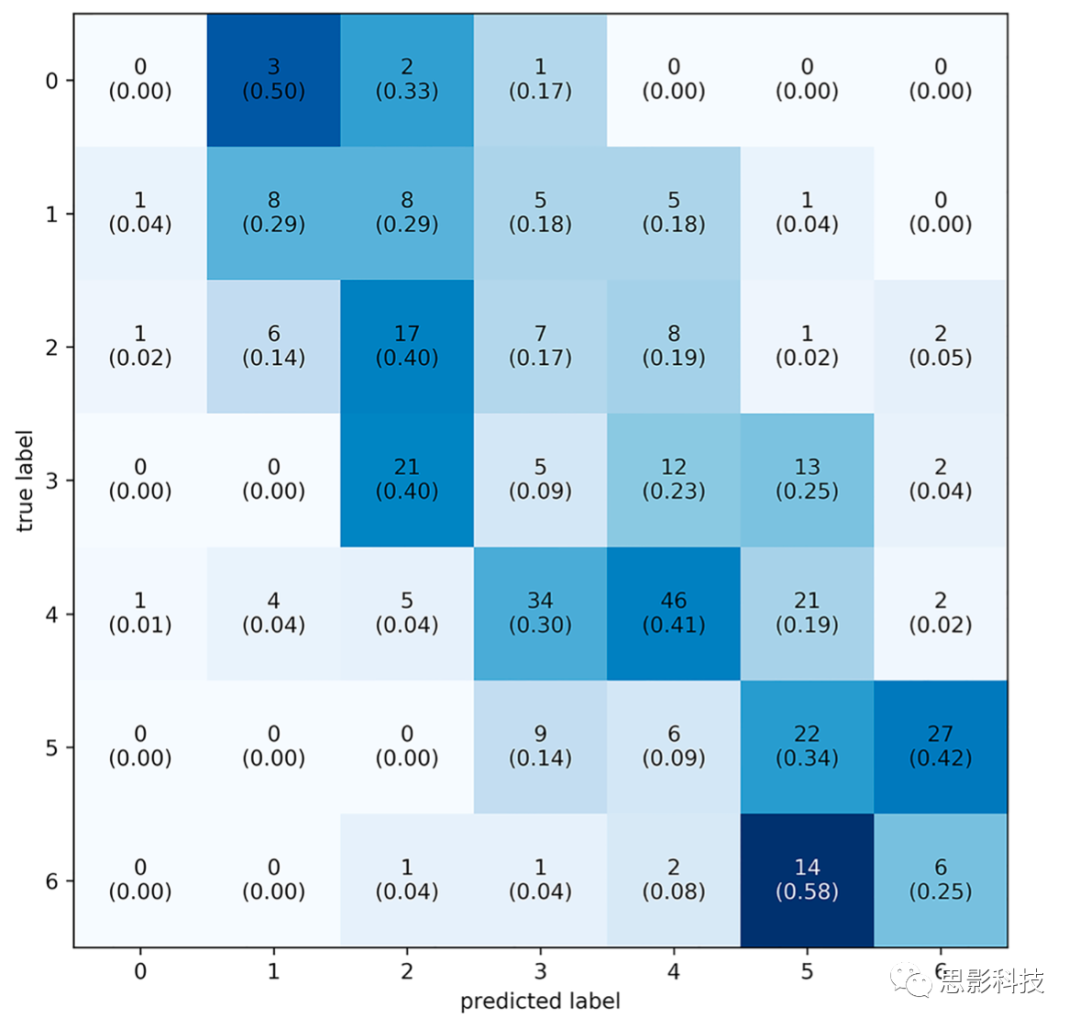
ͼ7.�����ǩ�Ļ�������ǩ��0��6�����߸������LoW��ÿ���������Ԥ���ǩ������Ԥ���ǩռ��(����)�������Ԥ���ǩ�ڶԽ�����Χ��
7.3.���ǩģ�ͱ���
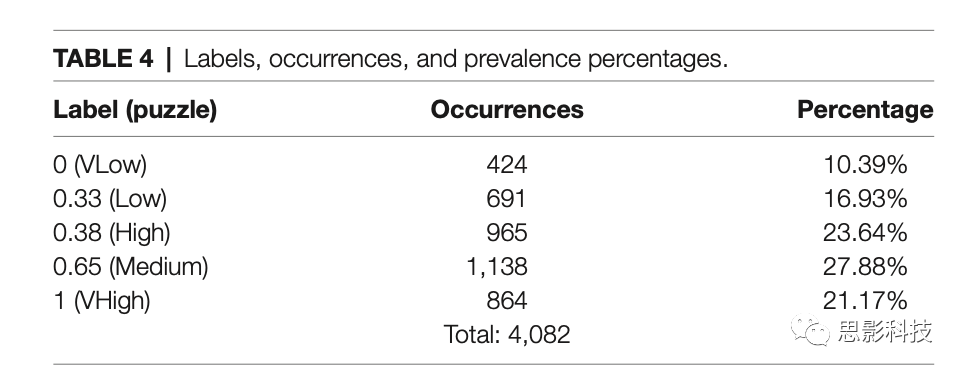
�ڶ������ǩ��Ϊ�弶��ȡ���ڱ��Ե�ƽ�����֣����Ⱦ࣬�ֲ���ռ�ȼ���4��������ǩģ��ѵ�����ƣ�ʹ��Optuna����������˹�20�γ���������trial���������5��S_LITģ�ͻ����ý������ʵ��Ԥ���ǩ֮���ƽ������Ϊ0.2386����ͼ8���ֲ��� = -0.055���� = 0.284����ͼ9������������ʾ������ʵ��ǩ��Σ���ģ��������ݷ��ൽ���ļ��Ѷȡ�����������£���������ȷ��Ϊ27%���Ը��ڻ���ˮƽ(ȷ��20%)�������ǩ��ȷ������������72%��ȷ�ʡ���ˣ����ǩ�ή�ͷ������ı��֣�����ԭ���DZ�ǩ�д���������
��4.���ǩ������ռ��
��5.��trial�����ģ�͡�Ԥ��-��ʵֵ���졢ѵ����ʱ
ͼ8.���ǩ��Ԥ��-��ʵ��ǩ����ֱ��ͼ����ֱ������ԭʼ�߽�1��LoW����ֱ��ͼʹ��S_LIT���5��trial16��
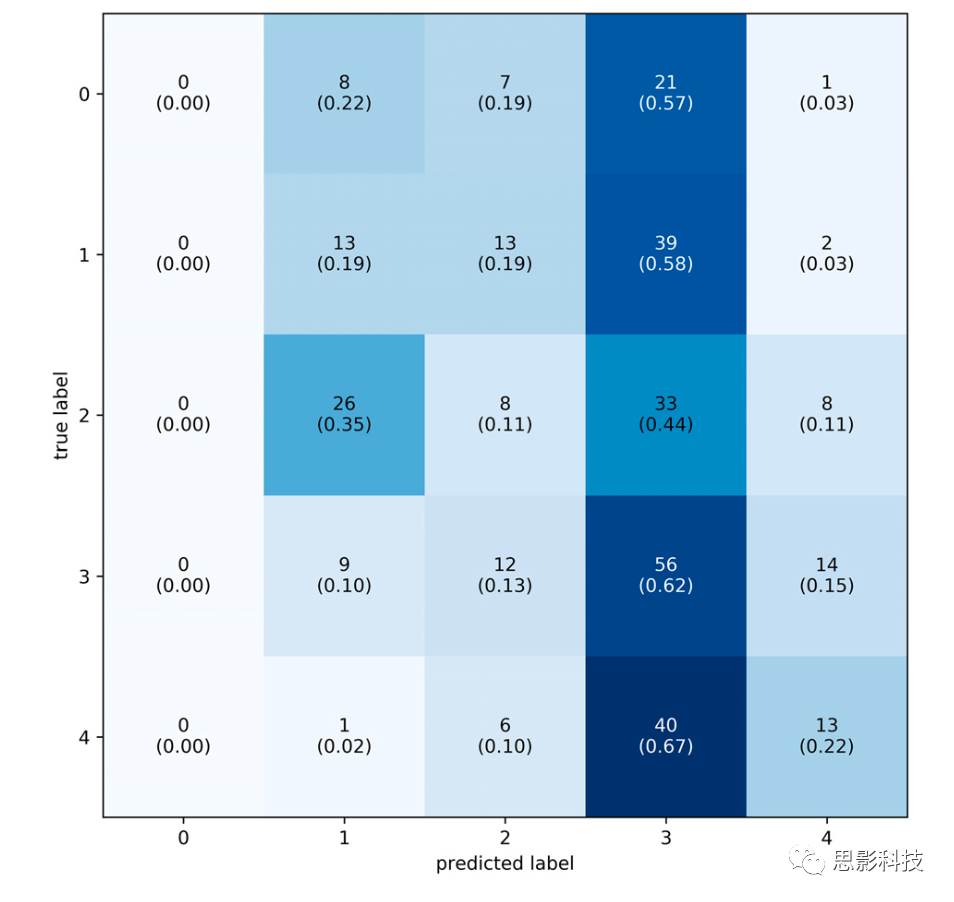
ͼ9.���ǩ�Ļ�������ǩ��0��4�����������ÿ���������Ԥ���ǩ������Ԥ���ǩռ��(����)�������Ԥ���ǩ�ڵ��ļ��Ѷ�(���Ѷ�)��
7.4.��ģ̬�ı���
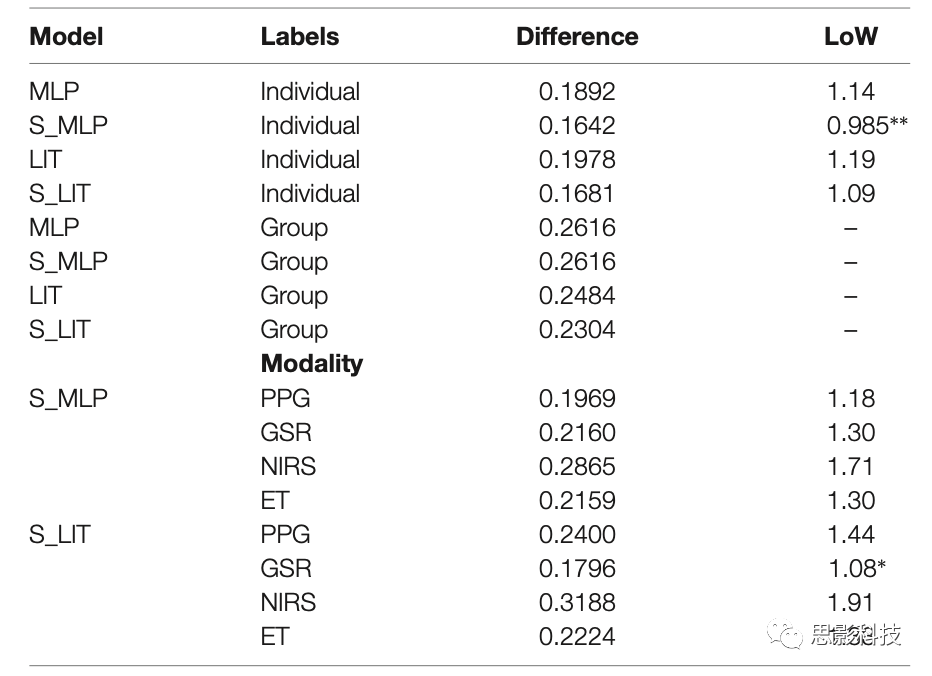
Ϊ���о�����ģʽ�ļ�ֵ�����ǻ�������ģʽ�ı��֡�����ģ��ʹ����֤����Ŀ��ģ̬����Ч�ij���������ѵ����ʹ�ø����ǩ�����Խ������6��S_MLPģ����PPG������ѣ�Ԥ������ʵ��ǩ֮���ƽ������Ϊ0.1969(1.18LoW)��GSR��S_LITģ��ʵ�ֵ�ģ̬�����������֣�����Ϊ0.1796(1.08LoW)��fNIRSģ̬������ģ���ϵı�����S_MLP��S_LIT�Ľ���ֱ�Ϊ0.2865(1.71LoW)��0.3188(1.91LoW)��
��6.�����ǩ�Ľ��
8.����8.1.����
����PMWLʱ��ʹ�ø����ǩѵ����ģ�ͱ��ִﵽ7���ȼ��ľ��ȣ���֤����IFMMoN�ڸó����µ���Ч�ԡ�ֱ��ͼ��ʾ����̬�ֲ��о��������λ���㸽����������Ԥ���ǩ�ӽ���ʵ��ǩ������������ʾIFMMoN��ƽ��Ԥ��ת��ֵ�Ը�����ʵ��ǩ�����Կɹ۲쵽�Խ������ơ���ģ���ڵ��弶���������ã�����ǵ����͵�������Ҳ�������ƣ��������еı�ǩ���ָ���(�ڶ�������)�����⣬��������Ȼ�����������������������������������ֲ�����Դ����Բ���ļ�������µı��ֺ������������ֲַ������³������Ż��ڼ���ֵľ�仯����Ϊ���ݼ���ÿһ�۵Ļ�ϴ��ʽ��ͬ�����һЩ�۵������˲��Լ��д����Բ������Ľ϶�������
���ǩ�ķ���û�������Խ������ƣ����۱�ǩ�ǺΣ�IFMMoN����������������ڵ���������Ҳ�����ձ�ı�ǩ����ζ��IFMMoN���ڴ���С����ʧ������ԭ������PMWL��ֵ���ܺܺõش������Եĸ���PMWL�����������ͱ�ǩ֮�����ϵ��������IFMMoN�����ڸ��������ǩ�������ѧϰ���������������������ǩ�Բ�ͬ����������ͨ�ã��Ϳ����������ݼ��н��и�����δ���������Թ�ע��������Ӱ�죬ģ�͵����(model affectivity)�Լ�������ֿ������˶��죬��������˽���Щ����������IFMMoN��Ӧ���ԡ�
������ģ̬��ijЩģ̬�ı���������������ģ̬�����ܱ���û��ֱ�۱��棬��ģ̬������ʾ�������ǩ���Ƶ����ƣ����з��༯����һ����ǩ���⽵���˵�ģ̬����Ŀ��ŶȺͼ�ֵ��fNIRSģ̬�ı������䲻�ѣ��������ζ�����ݲ������м�ֵ���źţ������źŴ�������֡�ģ̬���ֲ��ѵ���һ�������������ڴ̼����֣�fNIRSģ̬ͨ��ʹ��block��ƣ�������MRI(fMRI)�о�Ҳ���ǣ�������ģ̬�����ϲ���������ͬ���źš�
Ȼ���������о��еĴ̼����ֲ�û����ѭblock��ƣ��෴ʹ���˸���Ȼ�Ĵ̼����̼�������ʵ����(������ʵ����)ʹ�����ܹ�����fNIRS�ڷ�ʵ���ҳ����µ���Ч�ԣ���ҲӰ��������(��ǩ)�Ŀ������ԡ�����û�����ÿ����ģ̬���г������Ż�������ʹ������Ӧ�������Ѳ�������˵�ģ̬�ı��ֿ��ܲ�����ѵġ�
������֤����ģ̬��������Խ�ԣ�������Ҫ�ڲ�ͬ�������ɷ�ʽ�Ͻ�����֤������N-back���Ӿ���Ϣ���ء����⣬��Ҫһ�����Ƶ�ͳ�Ʒ�����֤�������ԣ������ɶ�β��Ե��µ�α������У����ijЩ������������е�ģʽ�������ģʽ�����ı����൱�����������ģ����������˱��ĵ��о���Χ������������MG������ģ�黯��ƣ�����IFMMoN�����ÿ��١��������ģ�黯�ı��õ����㣬�����о�������ʵ�á����������ܹ�ʹ������ģ̬��ø��õı��֣����ͨ���Եı�Ҳ�õ����㡣IFMMoN�ƺ����Ը��õظ������������Դ�����ݣ����������ΪMG��ʵ�����м�ֵ��
8.2.����
1.Ӳ�����ƣ����ڼ���豸ͬ����ʱ�����ԡ���¼���������ݵ�ƽ��Ư��Ϊ548ms(SD=590ms, 58-2827ms)�����������Ե�Ư�ƴ���1s������������ԭ����¼�ƽ���ǰ�����������豸�رա�����������ԭ���в��������ijЩģ̬(��ET)��ƽ����¼��548msƯ��Ӱ���൱������fNIRS����ô���С��������ϵͳ���Ư�����е�ģ̬һ��ʹ�ã����Ե�ͼ(EEG)������Ҫ���нϴ�Ľ���һ�ַ������ڹ��ܸ�ǿ��ļ�����ϲɼ����ݣ������ö�̨������ɼ����ݡ�Ϊÿ���豸�����������CPU����ʹ������á��ض��豸��Ӳ������Ҳ���ܵ�����������Ư�ơ���һ���о�Ư��ʱҲ���Բ鿴��¼����ʹ�õ�������
2.�����������ޡ����ģ�ͱ��ֵ�һ�ֳ��������Dzɼ��������ݡ������ܹ���ļ22�����ԣ��ɼ�4082�������������ݼ��ĽǶ����������õĴ���ͼ�����ݿ�ImageNet�г���1400����ͼ��Ȼ���ɼ���������Ҫ��ʱ���࣬������ʹ�ö���豸��
3.ģ̬��ѡ��Ŀǰ������о���ʹ����������(˫�۵�X��Y����)��Duchowski����֤��ͫ�������֪������Ч����ͫ���������뱾�о����ܵ��²�ͬ�Ľ�������Բ���Ҳ����ˡ�fNIRS���ڲ�����/����Ѫ�쵰����Ա仯��EEGҲ������Ԥ����֪���ɣ���ij�̶ֳ��ϣ�ͬ�����о�����ʹ�ò�ͬģ̬����ý�Ȼ��ͬ�Ľ����
4.ģ�ͼܹ����Ż���Ŀǰ������ʹ��������IFMMoN��ÿ�ֶ�������С�����汾��С�汾���ֳ����õķ�����֣�Ҳ����Ч�����������Ϊ���ݼ��Ĺ�ģ��С������û�н�һ��̽��ģ�ͱ�������ģ����븴���Եļ�С����ߵĽ�ֹ�㡣���⣬�������Ż�����Զ�����ѧϰ�ʺ�dropout�����ı����ز㡢��Ԫ������Ҳ������߱��֡���һ���棬����е�ģ�ͱ��ֹ��ƿ��ܽ�Ϊ�ֹۣ���ΪӦ�õij������Ż����������ݼ��ϣ�����Ƕ������֤(���ڽ�����֤�ж�ÿ�۶�Ӧ�ó������Ż�)��
����mark������ѡ��Ҳ�������ģ̬�ġ����磬��ET������ȣ����fNIRS���ݿ���������ͬ����Ϊ�������˶���ȣ�Ѫ������ѧ��Ӧ�dz����������mark֮������ݿ��ܰ�����ijЩģ̬�м�ֵ����Ϣ��ֵ��ע����ǣ����ݼ�/ģ̬�ĸ�����Ҫ����ѵ�����磬�������������Ż������������ģ̬������Ҫ����ѵ������ģ̬��Ӧ��Head�������硣���ɾ����һ��ģ̬����ֻ��Ҫ����ѵ��Head���硣���о�û�в�������ͬģ̬�����������Ƿ���Ҫ��ѵ(�����ϲ���Ҫ)����������������Ա���Ϊ7ά������ÿ�����������Ӧ��ǩ�ĸ��ʣ�����0��1֮��ĵ������֡�
5.���ݲɼ��ͼ���ʱ������һЩ�������⡣����������������豸�����Բ����3��8��13��16�����ݱ������ų�������6��9��15��21ż��չʾ�������˶�/��ɫͷ���йص�α����������Щ����Ҳ�����������ݼ��У�Ŀ������ϵͳ��¶��һ���̶ȵġ�Ҳ����������ʵ����������С�
8.3.��ǩ
���Զ���ͬ��PMWL�������ͬ������������ȫ���ۣ����ȶ������⣬һ�����ھ����߹�����ʱ���ܸе����ź�ƽ��������һ���˿��ܻ��ھ���������ʱ�е���ѹ������ˣ�����PMWL����ص��������ʱ��Ӧ��Ԥ�ڿ����߶ȵ����Ͳ��졣���ڱ��о�ϵͳ������Ŀ��������Ȼ������ʵʱ����PMWL���������һ��ʼ��ʹ����Ȼ�̼����ȽϷ�������ʹ�����ֱ�ǩ�����߶�Ӱ���������ǽ���ʹ�ø����ǩѵ��IFMMoN��
9.����
���о���Ŀ����ʹ�ö�ģ̬DNN������PMWL�������Խ����������ʱ��ʹ��LSLͬʱ�ռ�GSR��PPGF��fNIRS��ET���ݡ��������һ����ӱ��IFMMoN����õ�ģ���ܹ���7�ȼ�����0.985��LoW��ȷ�ȷ���PMWL�����ڴˣ�������ΪIFMMoN����ʹ����������ģ̬����PMWL��MG�����о�����(���ݲɼ�������ѡ��ģ�����)����ָ�����塣�����Ը�(ģ̬)Ӧ�ó����������ʽ���䵽һ���ɼ������У�ʹ�����뵽һ��Head�����MNet�м��ں�������ģ�黯�������Ӷ���ģ̬ʱ�Ľ�ģ�ͱ���������ͨ���Ա���Сģ���ڷ���������ȡ���˸��õĽ����
10.�����
Ŀǰ����ѵ�������ֲ�ͬ��ǩ��1.���˱����Ѷȵȼ���2.���б��Ե�ƽ�������Ѷȵȼ������ͬĿ������Ȥ������һ����֪��ѡ��������һ������������һ���ж����ʵ������������Ԥ���������ش�����һ·����ѵ�������������ݣ��⽫�����˽�ܵ�������ķ���������������ϵͳ������³���ԡ�
���о�����ij���չ���Ǵ���һ������ʵʱ�����û�PMWL�������տ���ͬʱΪ����û����з����ϵͳ��Ȼ����������û�������������Ч�ʣ�����ͨ��������������������״̬������Ҳ����ͨ�����ҵ�������Ӧ�����������Ӿ�������������̼������о�������ģ̬����ȷ����PMWL���Ҳ��õ����ԭ���������������������ģ̬���û������⣬����ijߴ�Ҳ����ʵʱ��⡣��ϵͳ�������Լ��ĸ�������ʹ�ã��������ϵͳ����Ӧ���Լ���Ⱥʹ��ģʽ���������ල���������ġ�
10.1.������չ
���ģ��ȷ�Ե�һ����Ч�������ṩ�������ݣ��Ա�ģ���õط�����Ȼ�����ռ�����ʽ����������ݼȺ�ʱ�ְ���������չ���������µ�/�����������ݣ�������ݶ�ȱ�����⡣������չ�м��ֲ�ͬ��ѡ�������������ռ䡢�����ռ��ѧϰ�����ռ�����ɡ�����ռ����չ�漰���ת��ԭʼ���ݡ���ͼ�������ͨ��������ת�����ŵ���ʽ��������ͼ��������������������������ռ��е�������չ��ͨ����Ҫ����רҵ֪ʶ��ȷ�������ɵ�����ƥ�䣬���ɵ�ģ�ͱ�֤����ִ�д��������ҿ˷���������ģ̬ȱʧ������ʾ���б������ÿ���������ͺ�����ר������µ�������ȡ����չblock��
Vries��Taylor������ѧϰ�����ռ���ִ��������չ���÷�������������ѧϰ�����ݵı�ʾ��Ȼ�����Щ��ʾִ��������չ���������չ�������ݶ����������ݻ����ɸ������ĺϳ����ݡ����ǽ�����seq2seqģ�͵Ļ�����ʹ�������Զ���������Vries��Taylor����ķ���������������չ��������м����ô���1.����ǰ�������ƣ�������չ�ڽ�ά����ɵģ���ʵ����������2.�����������ض������������������ݣ����ƶ���ͨ�õIJ�������չ���ݣ���Щ����Ҳ�����ڳ������Ż�����ˣ��÷��������MG����ֵ����δ�������и�����
����ԭ�ļ��������������˼Ӱ�Ƽ��ţ�siyingyxf��18983979082��ȡ,���˼Ӱ�γ̼��������ȤҲ�ɼӴ��ź���ѯ����˼Ӱ�ṩ����������ط�������ҪҲ�����Ӵ��ź���Ⱥ��ԭ��Ҳ����Ⱥ�����������ǵĽ���������о��а����������ת��֧���Լ����½ǵ��һ���ڿ����Ƕ�˼Ӱ�Ƽ���֧�֣���л��

��ɨ����߳���ѡ��ʶ���ע˼Ӱ�dz���лת��֧�����Ƽ�
��ӭ���˼Ӱ�����ݴ���ҵ�γ̽��ܡ�����ֱ�ӵ���������ּ������˼Ӱ�Ƽ����еĿγ̣���ӭ�����ź�siyingyxf��18983979082������ѯ�����пγ̾����ű��������������ǻ��һʱ����ϵ���������ѱ���ѧԱ�����
�Ե缰���⡢�۶���
�Ϻ���
�ڶ�ʮ���������Թ������ݴ����ࣨ�Ϻ���10.17-22��
������
����ʮ�Ž��Ե����ݴ����м��ࣨ������10.11-16��
���£���ʮ�����۶����ݴ����ࣨ������10.26-31��
���죺
���Ľ��Ե����ѧϰ���ݴ����ࣨMatlab�汾�����죬9.24-29��
�ڶ�ʮ�߽��Ե����ݴ������Űࣨ���죬10.28-11.2��
�˴ţ��Ϻ���
�ڶ�ʮһ��Ź�����Ӱ��ṹ�ࣨ�Ϻ���9.19-24)
�ڶ�ʮ�Ľ���Ӱ�����ѧϰ�ࣨ�Ϻ���10.9-14��
����ʮһ��Ź������������ݴ����ࣨ�Ϻ���10.28-11.2��
�Ͼ���
����ʮ�߽�Ź�����Ӱ������ࣨ�Ͼ���9.15-20��
�������ɢ�Ź��������߰ࣨ�Ͼ���9.22-27��
����ʮ����Ź������������ݴ����ࣨ�Ͼ���10.16-21��
�ڶ�ʮ����Ź�����Ӱ��ṹ�ࣨ�Ͼ���10.24-29��
������
����ʮ�˽�Ź�����Ӱ������ࣨ������9.21-26��
��ʮ�����������ݴ�����߰ࣨ������10.20-25��
��ʮһ��Ź���ASL������������ǣ����ݴ����ࣨ������11.3-6��
���죺
�ڶ�ʮ�����Ӱ�����ѧϰ�ࣨ���죬9.17-22)
�ھŽ����������ݴ�����߰ࣨ���죬10.13-18��
����ʮ��Ź�����Ӱ������ࣨ���죬10.22-27��
�ڶ�ʮ�˽���ɢ�������ݴ����ࣨ���죬11.5-10��
���ݴ���ҵ����ܣ�
˼Ӱ�Ƽ����ܴŹ���(fMRI)���ݴ���ҵ��
˼Ӱ�Ƽ���ɢ��Ȩ����DWI/dMRI�����ݴ���
˼Ӱ�Ƽ��Խṹ�Ź����������ݴ���ҵ����T1)
˼Ӱ�Ƽ����������У�QSM)���ݴ���ҵ��
˼Ӱ�Ƽ������ද���С����Ӱ�����ݴ���ҵ��
˼Ӱ�Ƽ��鳤�ද��fMRI����ҵ��
˼Ӱ���ݴ���ҵ������ASL���ݴ���
˼Ӱ�Ƽ���Ӱ�����ѧϰ���ݴ���ҵ�����
˼Ӱ�Ƽ������Ⱥ����ҵ��
˼Ӱ�Ƽ�EEG/ERP���ݴ���ҵ��
˼Ӱ�Ƽ��������Թ������ݴ�������
˼Ӱ�Ƽ��Ե����ѧϰ���ݴ���ҵ��
˼Ӱ���ݴ������������Դ�ͼ��MEG�����ݴ���
˼Ӱ�Ƽ��۶����ݴ�������
��Ƹ����Ʒ��
˼Ӱ�Ƽ���Ƹ���ݴ�������ʦ ���Ϻ����������Ͼ������죩
BIOSEMI�Ե�ϵͳ����
Ŀ��ʽ���ܴŹ���̼�ϵͳ����