ע�ͣ�
����ģ�ͻ���⽣̬ѧ������������⼀����֪�Ļ�ָ���ķֲ���������������ݵ�ijЩԪ�ر��ֲ��䣬��������Ԫ������仯��⽣�µ���ϡ��������⽬���Dz�⽣⼀����ȱ���ض�⽣̬���Ƶ������Ԥ�ڵĸ�֡���
��������������ټ����ķ�չΪ������������ؽ��ṩ��Խ��Խ��ϸ����Ϣ�������ŷ��������Ľ�����ʹ���ϸ��������������ṹ����Ҫ����������Ϊ���ܡ���ģ����һ�����Ĺ��ߣ�������ѡ���Եر�������������ض��ܹ����ԣ�ͬʱϵͳ������������������Ը���Ȥ�����Ĵ��ڻ��С����ͳ�ƻ����ԡ�����������������������ģ�͵�����ʵ�ֺͽ��͡������˹��������������������ɷ�������������������ͳ�����������緽���ķ��ࡣ����ǿ������ģ�͵ķ�Χ�����ӿ��������������Ե�����ģ�͵�������������Ķ�����Ե��Ƚ�ģ��������Щģ��ʹ�����ܹ�ʵʩ�Ͳ��Թ��ڴ�������ṹ���ܵ���ϸ���衣���ǻع�����ģ����������ѧӦ���е����˳����������ռ�Ƕ�����硢ע�����������������硣������ǿ�������ģ�͵ľ����ԣ��Լ�Ŀǰ�������δ�����⡣
������ѧ�����ѽ��ص�ת�Ƶ����������Ϊһ������ͼ���ϵͳ�������á����ڣ��˽���Ե�����ԭ���Ƕ���о������ڿ��������ƻ�����ҪĿ�ꡣ��һ�о��ĺ����Ǵ��Խṹ���ܵ�ͼģ�ͣ�������Ԫ�أ�����Ԫ����ԪȺ����������ʾ�ڵ㣬����֮������ӻ�����ñ�ʾ�ߡ�����ϵͳ����Ϊͼ��ʹ�����ܹ������Ͳ����Դ��Թ�����Ҫ�Ľṹ������
���������������������ݹ����ķ�չΪ�����ṩ��ǰ��δ�е��꾡�����������ϵͳ�Ļ��ᡣ�ڹ�ȥ��15������Զ�����֡��ؽ������Ϳռ�߶ȵ���ͬ����ָ����һ��ɸ��Ƶĺ���������������Щ����������������������ԣ���β�ȷֲ�����һС�����������õ�hub�ڵ�ͽ������ӵ�����ģ�顣�ܵ���˵���о���������Щ���������ٽ��˹��ܷ��������֮���ƽ�⡣
�������֤�����������������żȻԤ�ڸ�ͻ��?������������ǻ����������������������ĸ���Ʒ?��һ�������������Թ�����һ���ض������ɻ�����?�ִ���ѧ�Ը���ϵͳ�ķ���Խ��Խ�����ڸ��ӵ�ͳ���ƶϷ�����������Ҫ�ĺͲ���Ҫ�����������۱����õ���ģ����--ӵ��ijЩ��������ӵ�����������Ĵ�����������ʵ�֡�����ʵ������������ϵͳ�Ƚ�ʹ�о���Ա�ܹ�������Ȥ����֮���������ϵ������ʾ��Ȥ�����Ĵ��ڻ��С�ڶ��̶�������������������ġ�Ȼ���µķ��ֱ��������ۣ���ʹ���е���ģ�͵��ġ�ͨ���������ϸ����ģ�����������۵Ĺ��̣��������ܹ��л��ش�ϸ�����۽Ƕ�������Щ��ͳ�������벻���ģ����ڴ��������п��ܾ�����Ҫ���ܵ�������
�ڱ����У����Dz�����������ѧ����ģ�͵����������������������˹������������������ʵ�ֹ��̡�Ȼ�����ǿ�����һ������ͳ���ƶϷ�������緽���������û��ĽǶȽ��������ۡ�����ǿ����ģ���ǶԸ��㷺�Ŀ�������ռ���в����Ĺ��̣������ճ�Ϊ�Ը���Ȥ���ض�����ͳ���ϵ������Խ��л����ԵĹ��ߡ�������ǿ�����ν�������Ŀ��Ӧ���ڷDZ��������ͺ�������������⣬�������ص������ע�����硣���ķ�����Nature Reviews Neuroscience��־��(�������ź�siyingyxf��18983979082��ȡԭ�ģ���˼Ӱ�ṩ����������ط�������ҪҲ�����Ӵ��ź���Ⱥ��ԭ��Ҳ����Ⱥ���)��
˼Ӱ����������������������½��������Ķ����������⣬��л��ת֧�֣�ֱ�ӵ����������������ź�siyingyxf��18983979082��ȡԭ�ļ�������ϣ���
�طţ�Ĭ��ģʽ����ͼ���ļ���ϵͳ���������hubs
Nature Neuroscience��������ѧ
PNAS����ʳ�ɵ�����������������ȶ���
������ֵ�ͼ�Ȩ�Խṹ�������Ӱ��
���Ӵ�������Ľṹ����
���Ե����������Ľڵ�ٽ������������ģ�黯
����״̬���ع�����֪��Ϊ֮���ӳ��
������һ��ʲô��������?
��߶ȹ�������֯�ṹ��6����Ҫԭ��
���������������
ͼ�۷����ڴ��������е�Ӧ��
��������ṹ�����ܺͿ��Ƶ�����ѧ
�������о��е�ͼ��ָ�����
�Ӻ�۳߶�������ĽǶȿ��ṹ--���ܹ�ϵ
ͼ���ھ�Ϣ̬�Ͷ�̬�����������е�Ӧ�ã�����������ķ���
��������֯�ľ�����
��ͯ����֪����Ķ�̬��������
��̬�������ӣ�ǰ��������ͽ���
Nature reviews Neuroscience����֪�ӹ���ص�Ĭ������
�Ա�֢�о��е�Ĭ������
Ĭ�����磺���µĽ��ʡ������о������о���չ�����е��¹۵�
DMN:���Ե�Ĭ������
��������Ľڵ�ķ���
����֢����Ӱ��ѧ��������ѧ
�ض�����֢��������ĵķ����������־��
Biological Psychiatry�����ֻ��ߴ��Ե���֯����仯��������
Neuron���Ӽ�ӳ�䵽��ά����
�������ӽ��µľ������֢
��������������ѧ������֢״ӳ����������
���������ϰ��п��Լ����������ִ��������ۣ����������еĶ���ѧ����
ͼ����ʶ������������ͨ��ģʽ�е�Ӧ��
������ѧ��ģ�͵����ʺ�ʹ��
��̬�������봴����
�������ģ��
�����������һ���µ����磬��������һ����ǰδ���о��������ֵĴ��ԣ�������һ���ѱ�����о������ֵĴ��ԣ�������ǰ��δ�е�ϸ�ڶ�������ؽ���ʹ�������ѧ�ķ��������Լ�����������ͳ����Ϣ����������·�����ȣ����нڵ��֮�����·����ƽ��ֵ���������ϵ����һ������ڽӵ�֮������ӵij̶ȣ�����ᷢ�ָ������·������Ϊ2.5������ϵ��Ϊ0.3����Щ�������Զ�����������������ĺ��ض�����?���ǵ������dz������ϵĴ���С?���ǻ��ֻ�����ɷ�����һ����С���Ƶ��������������?
������ѧ�����ٵ���ս�Ǻ���һ������������ͳ���ϵ�Ԥ��֮��̶ȡ������������������ڸ������������ڵ�������������С�������ܴ��ڵıߵı����������ܶȣ���ÿ���ڵ��Ϲ����ıߵ������������У��������塢��Ⱥ��ʵ������֮������˲�����ܱ���Щ���������ϵ�С�������ڸǻ�����ԡ�ͨ������ģ�ͱȽϵó���ȷ��һ������Ȥ��������·�����Ȼ���ࣩ����Ҫ�����������������ǵ��������˽ṹ���������������������ܶȣ���
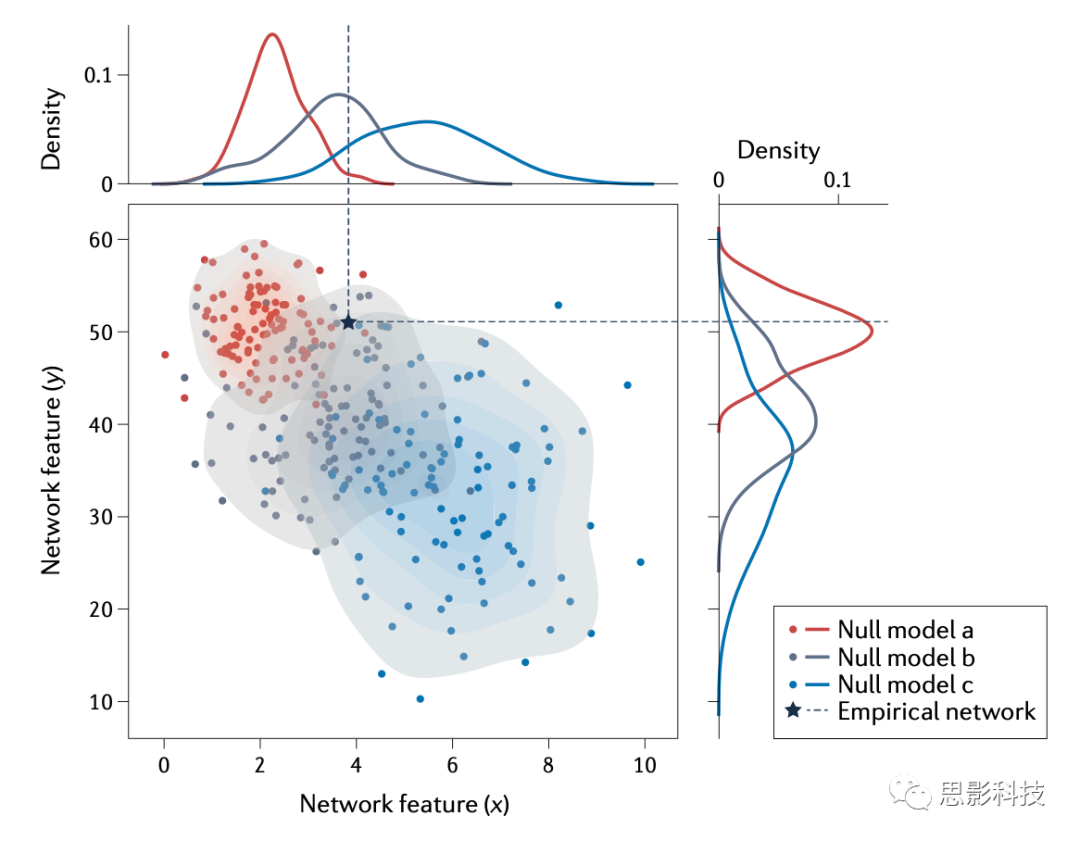
ͼ1������ͼԭ�������Ĺ��̡�����������x����·�����Ȼ����ϵ���������ڹ۲����磨��ɫ���ϼ��㡣Ϊ��������������ͳ�����壬����������һ�������磨��ɫ�������DZ����˹۲������һЩ���ԣ��ڱ�����Ϊ�ܶȣ���ϵͳ���ƻ����������ԣ��ڱ�����Ϊ���˽ṹ����Ȼ������Ϊÿ�������������ͬ�����������������������������ܶȶ��������˽ṹ����������£���������x��xp���ķֲ����������Ȥ������x�ڹ۲��������������ڻ�С�������磬���֤��������x��������������û�б��������������͡����磬������Ƿ��ֹ۲�����ʼ�ձȾ���������˽ṹ�������ܶȵĿ�������ʾ������ľ��࣬���ǾͿ�����Ϊ���۲������еľ������������˽ṹ����ģ��������ܶ�����ġ�pֵΪ�ֲ�xp���ڻ����x�ĵĸ��ʡ�
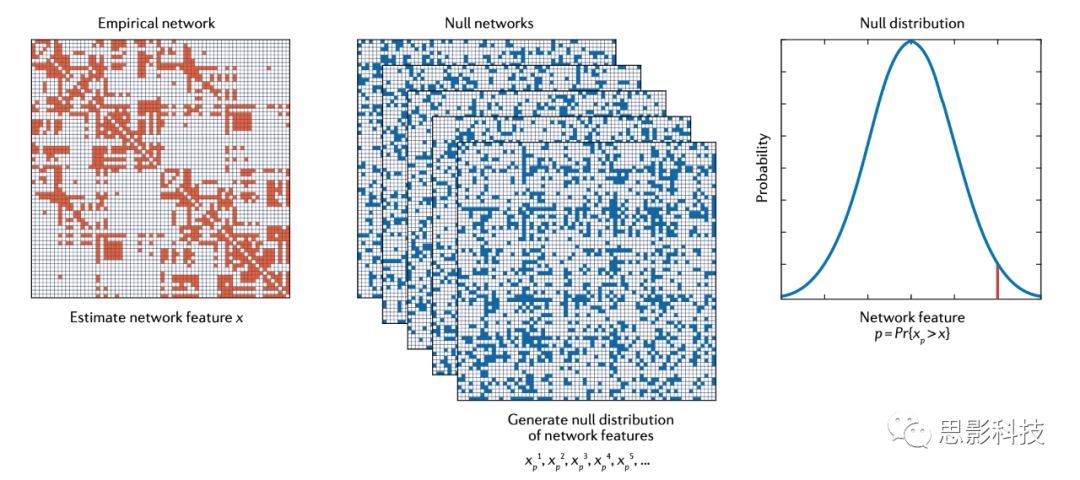
ͼ1 ����������������ֲ�
�Թ۲������ͼ�۷�������ɫ�����Եõ����������x����·�����ȡ������ģ�黯�������еĺ�ɫԪ�ر�ʾ�������ӣ���ɫԪ�ر�ʾû�����ӡ�Ϊ��ȷ����������ͳ��ѧ���Ƿ�������ϣ���������һ�������磨��ɫ�����������˱�ʾԭ����H0�Ĺ۲������һЩ��������(���ܶ�)����������˱�ʾ����H1����������(�����˽ṹ)����ÿ�����������¼�����ͬ������x��ʹ�����ܹ���������¹�������xp�ķֲ���������x�Ĵ�С�ǹ����ڱ������������ԣ������ǹ�����������ԡ�Ȼ��ͨ������xp��x����ĸ���Pr������pֵ����ͼ��ʹ�ù�������ɢMRI����MRI���ݼ����ɵģ�������70���������ԡ�
��ģ�͵��ձ���
��ģ�������������Ļ��������������DZ���Ч�ع������������������Ķ����С����磬�����������ࣨC����·�����ȣ�L�����ʵ�С����ϵ�������������ļ��㷽���Ǹ���һ��������磨Cr��Lr���е�ƽ��ֵ��ÿ���������й�һ����

����һ��ʾ���У�ģ�黯ͳ������Q����������ijЩ������c�������������ӣ�Ai,j����������Ԥ��֮���������ˣ�ͳ�����������һ����ģ�������壬��ģ�����������������ӵ������ܶȣ�Pij����
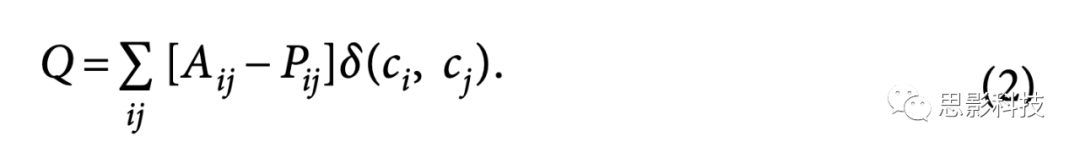
���ܴ������������ʽ���������ȵ�ģ��ͨ��������ģ�ͣ������������������������硣
��Ϊ���һ�����ӣ�rich clubϵ�������������и߶Ƚڵ�֮������ӱ�żȻԤ�ڵĸ����ܵ����ơ���һ��ϵ��(��norm)����Ϊ�����и߶Ƚڵ�֮��������ܶ�(��)����б���������(��rand)��������������и߶Ƚڵ�֮��������ܶ�֮�ȣ�

�ܵ���˵��С���硢ģ�黯��rich club��Щ��������֤������������ѧ�У���ģ���Ƕ�ô����ٹ̡����ǻ���������ģ�Ͳ����������ڲ��Ժ;ܾ�����衣�෴�����ǿ��Ա����㷺�����ڹ�һ�������������������أ�����һЩ���Ա����ƻ�����ͼͳ���������仰˵����ģ�Ͳ�����ֻ��������pֵ�����������ڼ���zͳ������������������仰˵����ģ�Ͳ���Ҫר���������� p ֵ�����������ڼ��� z ͳ�������������������Ҫ�Ƚϲ�ͬ��С���ܶȵ�ͼ�ε�����£��������ȡ�������ڲ�ͬ�Ŀռ�߶Ȼ��ø��Ի��ָ��ؽ�����������ʹ�ò�ͬ�����ؽ���ģʽ����֮��ıȽϷ�����
���������ģ��
��������ѧ�Լ����㷺�������ѧ�У��������ֲ�ͬ�ķ��������������硣���е���ģ�Ͷ�ͨ������۲쵽���������ԣ������˽ṹ��������һ������裬ͬʱ�����������ԣ����ܶȺͶȡ�ģ�͵IJ�֮ͬ�������������ʵ����Щ��˵��ͼ2����
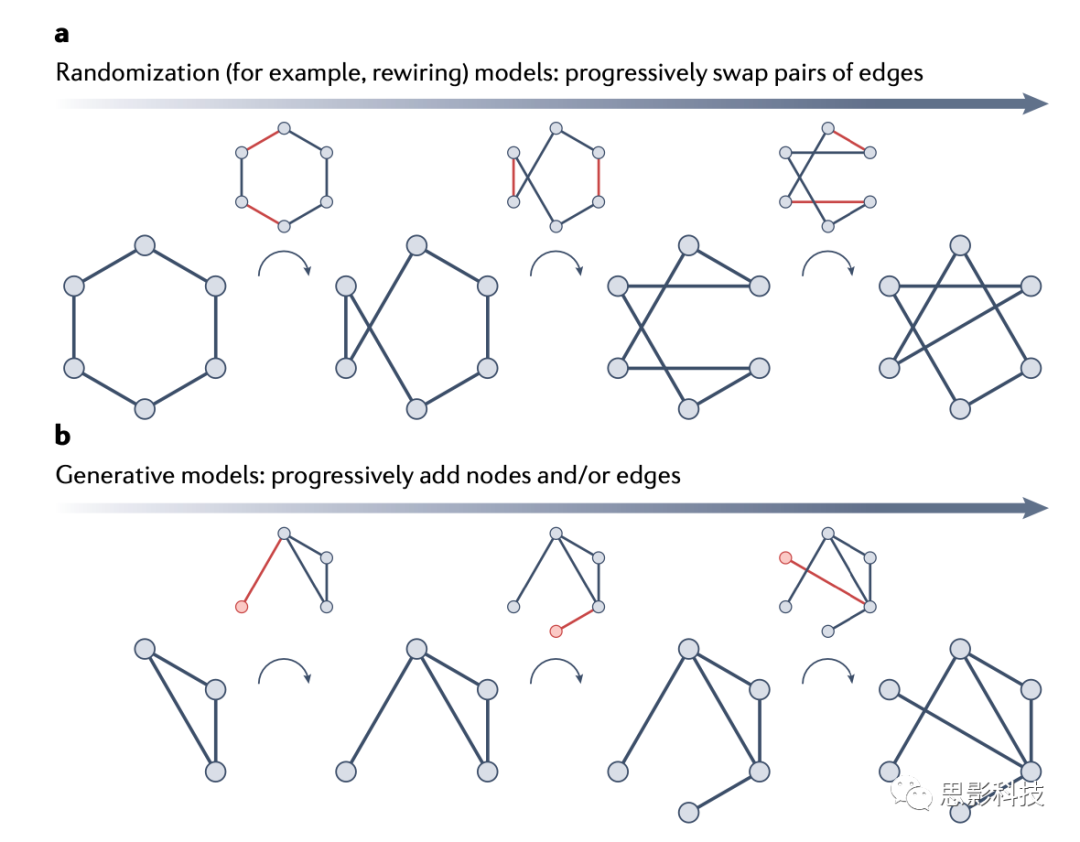
ͼ2 ���������ģ�͵ĶԱ�
Ҳ�����������������������ز������ز���ģ��ͨ������ز��߹۲����磬�����ؿ���������һ�ࡣ���ѡ��һ�Աߣ�ͼ2a����Ȼ��������ÿ����������һ��"��"�ڵ��һ��"��"�ڵ㡣���磬�������ѡ��������A-B��C-D���������ܵ����µı�A-C��B-D����Ŀ��������һ��������磬������Ľڵ�ͱߵ�������۲�������ͬ���Ӷ������ܶ���ͬ����Ҫ���ǣ����ڱ��ǻ����������ƶ�����˽ڵ�ߵ���������䡣��ˣ�ÿ���ڵ�Ķȱ������������ز��ߵ����类��Ϊ������ԭʼ������ͬ�ȵ����С��������͵�null��ʱ����Ϊ"����ģ��"��Maslov-Sneppen�ز��ߡ�������������һ�������۵ģ��ز��ߵ���ģ�Ϳ���ͨ��������Լ�������½��б��������ֹ۲�����ĸ������ԣ�����ɱ��������ԡ�ģ���ģ�ڱߵı��ʺͱ�Ȩ�ء�
�ز���ģ�Ľ��۲����������������磬������ģ�����ͷ��ʼ������������ͼ2b����������ͨ���ýڵ��/��ߵ��Ӽ����г�ʼ����Ȼ���������IJ��ֲ��߹���α����������½ڵ��/��ߡ�ֱ��������Ĵ�С���ܶ���۲�������ͬʱ���������̲���ֹ������IJ��߹�������ж�����ʽ��������ȫ������ã�Erdős�CR��nyi���ͼ��������С��������ܱ߳��ȣ����߳ɱ�������������ȵ���߾��������������Ի������߶����ԵĽڵ�֮���ͬ�����ӡ����㷺����������ģ��Ҳ��������һЩ���ڵ����ӵ������еĻ��ƣ������������ӣ������½ڵ���п������ӵ����и���ȵ����нڵ㡣��������ģ�͵���ҪĿ���ǽ�ʾ��������Ľṹ��������DZ��ԭ������Ҳ���������������ڻ������������ģ�͵ķ�ʽ���м�����顣������������ʱ�����з�������ʱ�����½Ƕ�������������ʹģ���ʺ����ݵĵ���ʵ�֣�����������ģ�ͣ���ͨ��������ƥ���һ���������Բ�����Լ��ʵ�֣����������ģ�ͣ���ͨ�����������۲����������Ķ��ؾ����Լ�����ƣ�����ģ�ͻ����Ա������Լ�����õ�����ģ��ʶ�����磬����ģ���ѱ����ڲ��Դ��������γɵľ�����˵����ģ��A���ߵķ��ý���Ϊ����С�����߳ɱ����������ģ��B���߱������ھ����ص����������Ĵ�������֮�䣩��ģ��C���߱������ھ������ƻ������ģʽ������֮�䣩��Ȼ��ͨ������ÿ����ѡģ�ͣ����ֲ�ͬ�����ɻ��ƣ��Թ۲����������ĸ����̶����Ƚ�ģ�͡����ڸ����������ڽ������������Ϊ��̬ϵͳ��ģ��ʶ�����綯̬�����ģ�����жԶ�̬��·����õ�������Ľ��ͽ����˲��ԣ���ȷ�������ϻ�����ģ�ͣ������������Ϊ��ͬ�Ļ��ƻ�ģ���塣
������ʵ���ϴ��ڲ��죬�����������ģ���γ���һ������ķ������ߣ������ƶ��������й�����ṹ�ļ��衣�����ģ���У�����ϵͳ���������Щ���Ǽ���������о���������������Ҫ�����أ���������Щ���費��Ҫ�����ء�������ģ���У�����ϵͳ���������Ǽ���Ϊ��Ҫ����С���ؼ�������������Ͻ������ģ�ͺ�����ģ��֮��IJ���������ͳ��ѧ�зDz�������Ͳ�������֮��IJ��졣��������ģ�ͣ������ڲ���������һ����������ȷ�������������ɵĹ��̣���������ֲ�������һС��������������ģ�ͣ����ڷDz��������У����Dz���������ֲ��ļ��裬����ʹ��һЩ������̴ӹ۲���������ϳ�һ����ֲ�������ʱ������ƣ����ģ����ø����Ƚ���������������С���跶Χ����Ϊ����ģ���ṩ������Ϣ��
��ĿǰΪֹ���ڱ����У�������Ҫ��ע����ͨ���ز�������ģ�Ͷ��������˽ṹ�����������Ȼ���������繹���ͷ��������������У���ģ��Ҳ�������ڷ����������Ե��������ϵ�������ע�����������������ģ�Ͳ��ֽ���ϸ����չ�����ۡ����磬�ڹ������繹�������У�ʹ�����ϵ���������ɶ�������ʱ������֮��Ĺ�ϵ������ڴ���ȫ���ӵ���Ԫ��ڵ������ڴ����ԣ�������������£��漰ʱ���������������ģ�Ϳ��ܱ������������������ʵ���С����Ƶأ��������ɶԽڵ���ͼ֮��Ĺ�ϵʱ������һ��ͼ�����ڽڵ���������ֱ���������ͬʱ����ijЩ���ԣ�����ռ�����أ����������ڱ����������������ӵײ����硣
����IJ����ռ�
����������ɹ�ѡ�����ģ�ͣ��������ѡ���ʵ���ģ����Ϊ�۲�����IJο�����أ�ͼ3չʾ��һ���۲����磬�Լ�����������������������IJ�ͬ��ģ�͡���һ����ģ����һ�����ͼ��ֻ�����ܶȡ��ڶ�����ģ����Maslov-Sneppen�ز�����ģ�ͣ��������ܶȺͶ����С�ע�⣬��������ռ���ȣ��ز��ߵ���ռ����������ˮƽ�ʹ�ֱ���ƣ�����۲������е��������ƣ���Ϊ�ڹ۲���������Ϊhubs�Ľڵ����ز��ߵ���������Ȼ��hubs����������ģ�ͣ�������������ܶȡ��Ⱥ��ܵIJ��߳ɱ�����ʾ����۲��������ƵĽṹ�����仰˵�������Ӷ���ģ�͵�Լ��ʱ�����ǽ������������ԭʼͼ����ʵ��ʾ���Ӷ�����һ�����Ƚ�����ģ��������˸��ϸ�IJ��ԣ���ʶ���ϸ���ȵ�Ӱ�죬����Խ���ԭʼ�����з�������١��������˵������ģ�͵�������Ҫ���ԡ����ȣ���ģ�ʹ�����һ����Χ�ڣ���Χ�Ӳ�ȷ�����㵽�Ƚ����㣬��ȡ����ʩ�ӵ�Լ������Σ���ģ����һ��ϵͳ�ضԸ����DZ������ռ���в����ķ����������۲�������������ռ��С�
��ĿǰΪֹ�������Ѿ�������������ӲԼ����Ҳ����˵����������ȷ�ر�����������������Ķ����С�Ȼ��������������"��"Լ�������е���ģ�ͣ���ЩԼ��ֻ�ܽ������㡣һ������������ν�����Maslov-Sneppen���ز���Ӧ���ڼ�Ȩ���磬�Խ��Ʊ���ÿ���ڵ��Ϲ����ߵ�Ȩֵ֮�ͣ�ǿ�����У����䡣������̵�һ���DZ��������е��ز��ߣ��ڶ�����Ȩ�ػ������ڸò��У����ڱ�Ȩ���ɲ�����ȫ����������ֵ��ɣ����Ժ��Ѵﵽȷ������������ÿ�������������ж�û����ȫ����Լ����������ƽ�����ԣ�������������ļ����У���Щ�����ǵõ�����ġ�
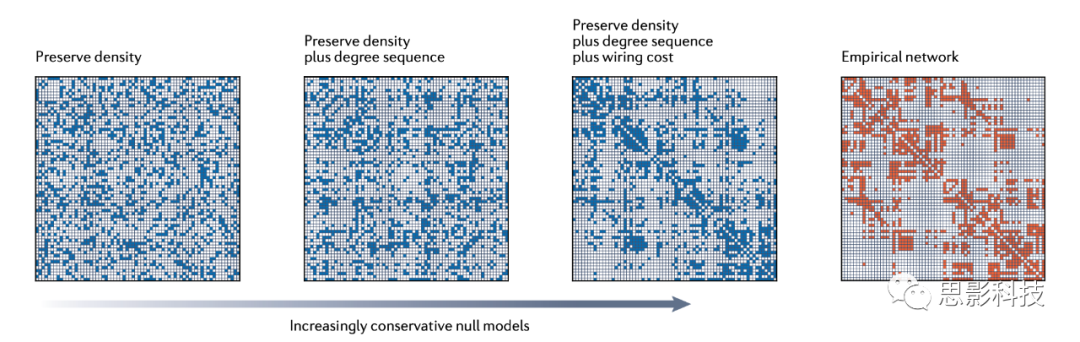
ͼ3 һϵ����ģ��
��һ���˵��������ģ�͵Ĺ��̿�����Ϊ�ǴӾ�����������ĸ��㷺�Ŀ������ռ��н��в�����ͼ4���������ά������̬�ռ��ɴ����ض��������ԵĻ��������ɡ�����ռ��е�ÿ�����λ�ö������Ų�ͬ��������̬������һЩ����������Լ��������ʵ�֣�����һЩ���ܡ��ÿռ��е��ڽ��Է�ӳ��������̬֮��������ԡ���ģ��Լ�����������ϸ�̶Ⱦ����˸ÿռ��н�����ģ��ʵ�������IJ��֣����磬�ϸ��ģ�ͽ�λ�ھ������總�������Ͽ��ɵ�ģ�ͽ�λ�ڸ�Զ�ĵط�����ˣ�������ͨ���ز��������ɻ���ʵ�ֵ���ģ�ͣ����ǴӸ�������̬�ռ�IJ�ͬ���ֽ���ϵͳ������Ϊ������������������ֲ��ķ�����̽������ռ�ʹ�����ܹ�������ͬ��Լ�������ɻ��ƶԹ۲�������ض������Ĺ��ס�
�ɴ����ۣ������ռ�Ĵ�С��Ӱ����ģ��ʵ�ֵĿɱ��ԡ�һ����˵�����и���Լ����ģ����������Ӧ�ñ��ֵĸ����ƣ��Ӷ�������ģ�Ͳ����ռ��һС���֡�ͼ4չʾ����һ�����ģ��a��b��c����������ռ�Խ��Խ������ֲ��ı仯Խ��Խ����һ����Ҫ�ķ����������ǣ���ģ���Ƿ��Ŀ��ռ���о��Ȳ�����ģ�ͱ���һ���������������һ��������һ��ʵ������ζ���������п��ܵĿռ�������꾡�IJ�����������ʵ�������ʵ����ģ��ֱ����أ����ǽ������������ģ�͵����Ʋ����п�����һ�㡣
�����ף���ģ��û�жԴ�֮�֡���ģ��Ӧ�����ض����о��������ȷ�ҿ�֤α�����������֡�����������һ���о��е���Ҫ�Ա�����Ҳ��������һ���о�����Ҫ���Ƶ�Э������������һ���н���ϸ���۵�һ������ʾ���Ǽ���Ƕ��Ͳ��߳ɱ��Դ�������ܹ��Ĺ��ס����㷺����ռ���һ��ǿ��Ĺ��ߣ����ԴӶ���Ƕ�̽��۲����磬��������ͬ���������ԶԸ���Ȥ�����Ĺ�����ͼ4���������������˵��ͬʱʹ�ö��nullֵ�Դ𰸽������Dz��������Ƿ���������ȫ�����Ϣ�����ķ�����
ͼ4 ��ģ�͵ij����ռ䡣
�ռ��������ģ��
�ڷ��������������˽ṹʱ��Ҫ���ǵ�����Ҫ�����������Ǽ�����״��������һ���ռ�Ƕ��ϵͳ���������Ĵ�л��������Դ���ɴ˲�����һ���ձ�Ķ̾������ӣ��������ӿ��ܱȳ��������ӵijɱ����͡�ʵ���ϣ����ֳ���ģʽ���ټ��������������Ԫ�������Ͽ��ø�����������Զ����Ԫ���п�������ӣ�����ʾ���˸�ǿ������Ȩ�ء����ˣ���ͨ�Ժͼ�����״�Ӹ�������������ģ������Ҫ��ģ�����������Ǹ��ԵĹ��ס�
ƽ�����ԣ�ʹ�ñ��ز���ģ�͵���Ҫ�������ڣ�ԭʼ�Ľ����Ὣ�߷���������Զ�Ľڵ�֮�䣬�Ӷ����������磬�䲼�߳ɱ�Զ���ڹ۲����硣һ�ַ�����ʹ�ô��и���Լ���ĵ����ز��ߡ����ڵ��о�������۲�����������;���������ʱ����������ڵ�Ŀռ�λ�á���ѡ��ֻ���ڽ��߷��ڿռ������ڵ��ھ�֮��ʱ�Ż�ִ�н������Ӷ�������״���硣��Ȼ���������ز�������IJ��߳��ȣ������㷨������������������ܶȺͶ������⣬���ܾ�ȷƥ��۲�����ı߳��ֲ���Ȩ��-���ȹ�ϵ����һ�������ģ��ʹ������ν�Ŀռ��ض�λnulls�����нڵ�Ŀռ�λ�ñ��ı䣬�����˽ṹ���䣬ʹ�о���Ա�ܹ������۲�����������Ƿ����ɽڵ�֮��Ŀռ��ϵ�������ģ����������˽ṹ�������ġ�
�ܵ���˵������nullsʹ�����ܹ��������Կռ�Ƕ������˽ṹ�ı��ʡ����磬��С�����߳ɱ��Ĵ�����ģ�Ϳ������ִ�������Ķ�������������hubs�ڵ㡢���������Ժ�ģ�黯����ˣ���Щnullsֵ�����������������еĸ��ӽṹ�Ƿ����ͨ���ض��IJ��߹��������͡��ر��ǣ�����ģ�Ϳ��������κ����˹�������Щ�����У�����ߵIJ��߳ɱ���С���������ǻ����Ż������������ԣ���ͬ���ԣ���ô��Щ�߾ͻᱻ�������Եط��á�����Щģ���У����κ�����Լ����Ӱ�챻������������ʹ�о���Ա�ܹ��ζ�������ÿ��Լ������������ܹ��Ĺ��ס����������ģ���Ѿ���ʼ���Ǽ��Ρ����˺�����ڵ�ľֲ�����ѧע�͵�����Ӱ�죬������������λ��֣�������������һ���п��ǵ����⡣
ע���������ģ��
���Ե�ͼ�α�ʾ������������֮����߶Ȳ��죬�Ӷ�����ͬ�ʽڵ㡣Ȼ����������ѧԽ��Խ��ע����ṹ������ռ��ע֮��Ĺ�ϵ��������Ԫ��̬�������������ס���λ��֡������γɺ����ڶ���ѧ�����͵ıȽϿ����漰�����������ĵ���������������ԣ�������������߶ȱ�ע������ͻ����ƽ����������Ȼ�����ڹ������ϵ����pֵʱ������һ����Ҫ�����⡣�����������������������������Բ���صĶ�Ԫ��̬�ֲ������Dz��������������û�����������������Ԫ���ǿɽ����ġ����ݵ�֮��Ķ�����ʽ��������Υ�������ֶ����Լ��衣���ȣ��������ݵĿռ������ʹ������λ��֮��Ľ��ʺ���������ֵ���ơ���Σ�ͬ�Գ��Ե��´������Ұ�������Ӧλ��֮��IJ������ơ�������Ŀռ�ֱ���������Ƕȵģ���͵���pֵ��ЧӦ��С�������������ǵ�����������ص���������Щ���ƿ���ʹ�ÿ��ƿռ�����ص���ģ��������������ռ��û�����Ͳ���������ģ�͡�
�ռ��û����飬Ҳ��Ϊ��������������ͨ�������ת���Կռ��עͼ���������������������ṹ�Ϳռ��ע֮��Ĺ�ϵ��ͼ5������Щģ������Ƥ�ʱ�����ȡ�����в����������꽫���������Ͷ�䵽һ�������ϡ�������������ת֮��ͨ����ÿ�������������������ת��Ӧ��λ�ö������һ�����塣ͨ��������������Ӧ����ͬ�ģ����������ת���ռ��û�ģ�ͣ���Լ�������˴�����ĶԳ��ԡ����յõ��ı�עͼ����������ṹ�������˱�ע�Ŀռ�������ԣ�������ڵ����ע�Ķ�Ӧ��ϵ������ģ�ͼ5���������������������涥����濪���ģ������չ����������������ֿ����ݡ�ֵ��ע����ǣ��������Ͽռ��û�ģ�͵IJ�ͬʵ�ַ�ʽ���ض��ķ����۾����ϴ��ڷ��磬������δ����ڲ�ڣ����������Ƿ�������η���ע��ֵ��
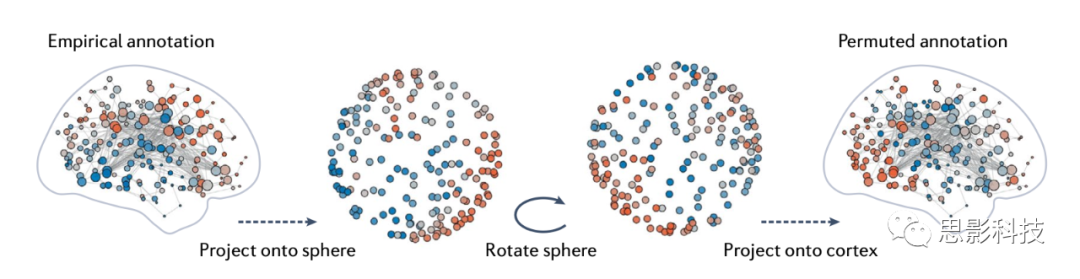
ͼ5 �ռ��û�����
���֮�£�����������ģ�����ɵ������ͼ����Ԥ����Ŀռ����ԣ����뾭�����ݼ���ͬ�Ŀռ�������ԡ�������ģ�Ͳ����������ݵ��������У��෴����Щģ��ʹ����ͼλ��֮��ľ������������е�����ʩ�ӿռ��������������ʹ��һ���Լ�IJ������������������Ѿ�����˼��ֲ������ķ����������ռ��Իع�ģ�͡�ƽ�����ֵ��ƥ�侭����캯����ʹ��Moran��������Ŀռ������ֽ⡣���ڿռ��û��Ͳ���������ģ�͵�ϵͳ�Ƚϣ��ɲο�����49��
�뼸��ģ�����ƣ������ռ�����ص���ģ��ʹ�����ܹ�֪�����������ڶ��̶��ϳ����ڿռ�Ƕ��ı���Ӱ��֮�Ϻ�֮�⡣��ˣ���Щģ�ͺܿ�ͱ�������ڣ����ҿ���Ӧ���ڹ㷺�ķ������⡣����һ��Ӧ��������һ���ض��ڵ�����x������ȣ��Ƿ����ض����Ľڵ��и������������ڲ������ϸ���ṹ����У��������ע�ͣ��ࣩ�Ƿ����������ģ�Ϳ���������������x������̶ȣ�ͬʱ������Ĵ�С�Ϳռ䷶Χ����һ��Ӧ����������������ע�͵Ľڵ��Ƿ���ʾ���˱�Ԥ�ڸ������ͨ�ԡ����������͵ķ����У��������ض�ע�͵Ľڵ�֮���ƽ����ͨ������תע��������ͨ�Ե���ֲ����бȽϡ����㷺��˵����Щ�����Ѿ���չ������ռ�������ڸ�������ѧ�����е�Ӱ�죬���������Ե�ģ̬�ڲ�����Ի������
��������Ӱ�������������ݴ������Թ��ܣ������������ģ̬��Ӱ�����ݴ�������Ȥ�������˼Ӱ�������ӣ�ֱ�ӵ���������������лת��֧�֡�(�������ź�siyingyxf��18983979082��ѯ)��
�Ͼ���
����ʮ����Ź������������ݴ����ࣨ�Ͼ���10.16-21��
�ڶ�ʮ����Ź�����Ӱ��ṹ�ࣨ�Ͼ���10.24-29��
����ʮһ��Ź�����Ӱ������ࣨ�Ͼ���11.12-17��
���죺
�ھŽ����������ݴ�����߰ࣨ���죬10.13-18��
����ʮ��Ź�����Ӱ������ࣨ���죬10.22-27��
�ڶ�ʮ�˽���ɢ�������ݴ����ࣨ���죬11.5-10��
��������ɢ�Ź��������߰ࣨ���죬11.17-22��
�ڶ�ʮ����Ź�����Ӱ��ṹ�ࣨ���죬11.27-12.2��
������
��ʮ�����������ݴ�����߰ࣨ������10.20-25��
��ʮһ��Ź���ASL������������ǣ����ݴ����ࣨ������11.3-6��
����ʮ����Ź�����Ӱ������ࣨ������11.9-14��
������Ӱ����ѧ�ࣨ������11.25-30��
�����R����ͳ�ưࣨ������11.16-20��
�Ϻ���
�ڶ�ʮ�Ľ���Ӱ�����ѧϰ�ࣨ�Ϻ���10.9-14��
����ʮһ��Ź������������ݴ����ࣨ�Ϻ���10.28-11.2��
����ʮ�Ž�Ź�����Ӱ������ࣨ�Ϻ���11.4-9��
���ݴ���ҵ����ܣ�
˼Ӱ�Ƽ����ܴŹ���(fMRI)���ݴ���ҵ��
˼Ӱ�Ƽ���ɢ��Ȩ����DWI/dMRI�����ݴ���
˼Ӱ�Ƽ��Խṹ�Ź����������ݴ���ҵ����T1)
˼Ӱ�Ƽ����������У�QSM)���ݴ���ҵ��
˼Ӱ�Ƽ������ද���С����Ӱ�����ݴ���ҵ��
˼Ӱ�Ƽ��鳤�ද��fMRI����ҵ��
˼Ӱ���ݴ���ҵ������ASL���ݴ���
˼Ӱ�Ƽ���Ӱ�����ѧϰ���ݴ���ҵ�����
˼Ӱ�Ƽ������Ⱥ����ҵ��
��Ƹ����Ʒ��
˼Ӱ�Ƽ���Ƹ���ݴ�������ʦ ���Ϻ����������Ͼ������죩
BIOSEMI�Ե�ϵͳ����
Ŀ��ʽ���ܴŹ���̼�ϵͳ����
������������ģ��
��ͨ��ͨ��������������֮���ͳ��Э���������Ƶģ��������������Ƥ����֮�������ԡ��������������Ӱ����������硢�ṹЭ�������硢��̬���������硢���������硢�����������������ʱ��ֲ����������硣��Щ�����ڹ������Ǽ�Ȩ�ģ�һ�����з��ŵģ���������ڶ���������ˮƽ�����е���ģ�ͣ����ز���ģ�ͣ������Dz�ǡ���ġ��ر��ǣ�ͨ�������Թ�������������ڴ����ԣ��������֪����A-B��A-C��ֵ�����ǾͿ������Ʊ�B-C��ֵ���ز��߿��ܻ��Բ��������ִ����Եķ�ʽ�������������磬A��B֮���Լ�A��C֮�����ǿ����أ���B��C֮�����������ء���ˣ������������жԱߵ������ز��߿��ܻᵼ�²�������Ȼ�����������������硣���仰˵�����������������Ҫ���ǵ������Ժͱ�Ȩ�صı�ѡ��ģ�͡�
����ʹ�ò�ͬ����Ϊ����������Ĵ������紴������ʵ���е���ģ�͡�һ��ѡ���Ǵ�������ؾ���ʹ������Hirschberger-Qi-Steuer�㷨֮��ķ��������㷨�뾭������ƽ��ֵ�ͷ�����ƥ�䣬����ʹ�ñ�������ڵ�ȵ�����ģ�͡�һ�����ϸ�ķ����ǽ��źű�������������磬�ڹ������ӵ�����£�����ͨ��ʹ�ø���Ҷ�任������ʱ������ת����Ƶ��ϴ��λϵ��������ʱ�������任�������������ʱ�����С��ɴ˲��������ʱ�����б����˹����ף����������ʱ�������ԡ���Ҳ������С���任����ɣ�������̱���Ϊ"��������"�����ͼ�źŴ����е����˷������Խ�����Ҷ�任��С���任�Ⱦ����źŴ��������ƹ㵽�����С���Щ��������������źſ��Ա��ֹ۲������ƽ���ȡ�
��������������ʱ������Ҳ���������ɷ��������������磬�Իع�ģ�Ϳ����������ʱ�����У��������������ݵ�ʱ�䣨�ԣ�����ԡ��������ܶȡ����湦�����ܶȺ�����ֲ�����Ȼ��Щ����ģ��ֻ������ʱ�����������������Ļ��ģ��Ҳ�����˿ռ���������Щģ�����ɱ����ռ�����ص����ʱ�����л�ͬʱ�����ռ��ʱ������ص�ʱ�����С����������������֮�⣬���ӵĶ���Ԫ�ŵ��ʼ�¼��ģ�Ϳ���ͬʱ�����ʱ�䡢��Ԫ��ʵ��������Э���
�ڽ���ѧ���Թ������������£�����ѧ�����ɱ�ֱ��������������ڣ�����ʱ�����в�ͬ����ͬ�����ߵĽ���ѧ�������ݵ��Ƕ����ġ�����������϶��ԣ��滻�ز�����bootstrapping��Ҳ����Ӧ���ڻ�������Ե����磬���������������Ŀɿ����������Ǽ�������豾����Box1����ע�⣬ʹ������Э��������ƫ��أ����Ƶ�������ܲ�̫�������ɴ���������ı�Ȩֵ֮���������Ե�Ӱ�졣Ȼ�������ǵ����ǵıߴ����ڵ�����֮���ͳ�ƹ�����һ��ʵ������������ҲӦ��ʹ����ģ����������
| Box1 Bootstrapped������
|
| �����һ�����в�ͬ�IJ��������������ƽṹЭ������������������ʲô���أ��������ڵ�����Բ�ͬ���⽫���Ӱ������У����㷺��˵�����Ƕ������Ի���������ͳ�ƵĹ��Ƶ�������ʲô����������������ز����ķ������ش𣬱���bootstrapping�����������������۵��������������������������������ֲ��ģ���bootstrapping���������������������ij����ֲ����������������䣨��ͼ����ͨ���������������ͼ����һ������������ijЩ���������ķֲ�����ͨ���ⲽ������Pֵ��ͨ��bootstrapping��������ͼ�����������䣬��ʶ������������ݵ㲻���е��ȶ�������Bootstrapping������������滻�۲�ֵ��ɣ��Թ�������ͳ�����ݵĴ������ԣ����磬���³���������A��B��C��D���ܻ����һ���µ�����A��C��D��C����������ѧ��ʹ�õ�����ͳ�Ʒ�������Dz���һ����������û����صķ��������������ơ����磬��һ��������У�������ʲ���������������ĵ�һ�ṹЭ�������硣���������ͨ����ȡͬ�ȴ�С����������������bootstrapping������������������һЩ�����ߵĶ��ʵ���������������߽��ᶪʧ���ظ�����������ʶ����������ض�����ȶ������еı������������ڽṹЭ��������������У�ͨ�����������о�����ͬ����(������)�ıߣ�Bootstrapping�ѱ���������������ƺ�����ͳ�����ݵ��ȶ��ԣ��Լ���ֵ���硣Ƥ�ʷ�����bootstrappingҲ���������ƹ��������ͳ�Ʒ����ʹ�ù���������ָ��ȷʶ����塣�������ڵ��bootstrapping�Ѿ���������Ч�ع��ƺ��������������нڵ������ԡ���������ͳ����еIJ�ȷ���ԡ���ĿǰΪֹ����ЩӦ�ô��������������������磬��������������ѧ�е�Ӧ�û��кܴ��DZ����
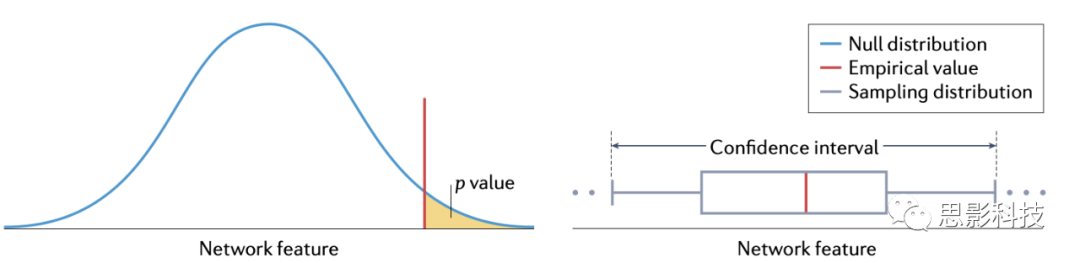
|
������ԣ���Щ����չʾ��һ����Ҫ�ĵ㣺ijЩ���͵���������ڹ����ͷ����ܵ��IJ�ͬ����ϱ��������ͼ6�����ṹ�����ע���������ģ�������ڶ����籾���ı�ڵ���в�����������������������ģ�ͻ����������繹���������н��в���������˵��ص�����ʱ�����л��������������ͨ��������������Ӧ��������������ݣ������繹�������ڽ�Ӧ����ģ���Կ�������������ͳ�Ƶ����ʵ�������磬����������ʱ�����п����ڹ���һ����ؾ���һ����Ԫ�����һ������ڵ��map��ÿһ��������������ǵľ����Ӧ����������õ��ģ�ͼ6�������⣬������ؾ��������Ķ�Ԫ���˽ṹ��ڵ����ԣ�Ҳ����ֱ���������ͼ6��������Ҫ���ǣ���Щ��ͬ����ģ�Ϳ���ͬʱ�����������Ը�ȫ�����������Ȥ�ľ���������
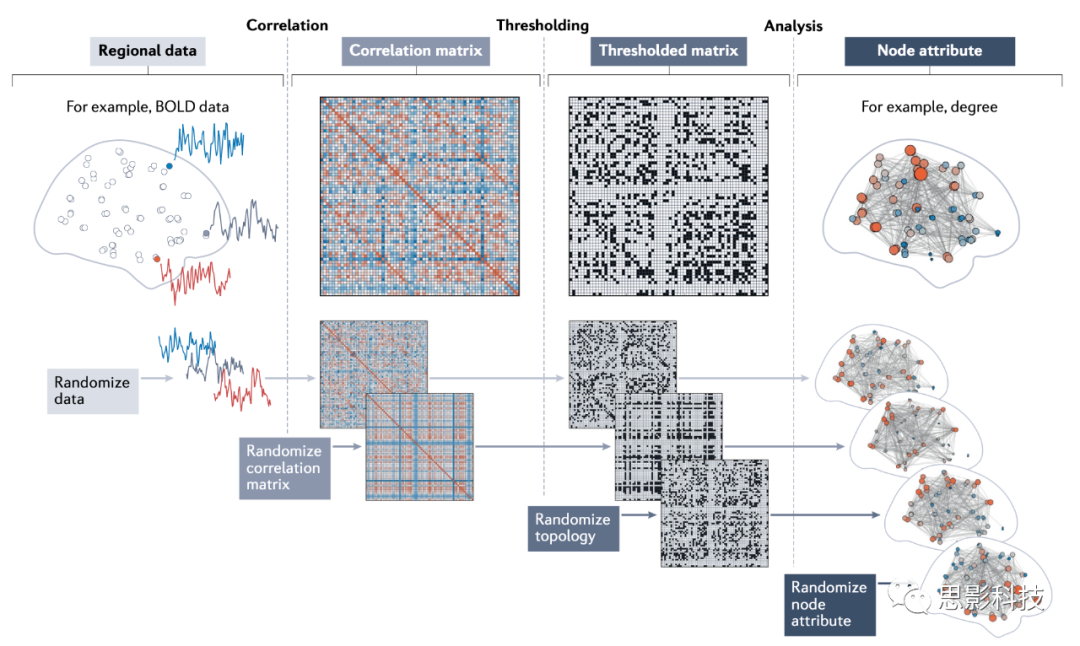
ͼ6 ��ģ�Ϳ���Ӧ�������繹���ͷ����IJ�ͬ��
��ģ�͵ľ�����
������ģ����������ѧ�п�ѧ������֧�����������������Ϻ�ʵ���϶���������Ҫ��ȱ�ݡ���������֮��Ĺ�ϵ����ʹ���������ֶ���������ṹ�Ķ��غ�ͬ���ס�Ҳ����˵��һЩ�����Ĵ��ڿ��ܻ��յ����������Ĵ��ڣ�ʹ���Dz������ڱ������������������������ѡ��һ�����������磬�����ģ��߶����ӵ�hub�ڵ��ͬʱ���ڣ����ܻ��յ��ṹ�Եĸ�������νṹ��rich club����ˣ���ģ�Ͳ���������ȷ�ػָ���������֮�������ṹ��
��Ϊ�ձ���ǣ����ڿ������ɵع�����ģ�͵��ף�����б�Ҫ���ݻ���������ϸ������ؽ�������ڿ��ɵ�ģ�Ϳ�����̫�ٵ��������ԣ��������"������"�۵㣬��Щ�۵�����ױ��ܾ�������ȷʶ�����Ȥ��ЧӦ��Դ���෴�������ϸ����ģ��ͬʱ������̫����������ԣ����տ��ܻ���������ṹ�IJ����ռ䣬�����뾭�������ƥ��ȹ��ߣ������˶��������Ⲣ����ζ����ģ�ͷ�Χ�Ŀ��ɻ��ϸ���������Ȥ�Ļ�Ӧ�ñ�̽�����෴��Ӧ�����ܽ���Щ������������ģ��һ���ǣ���ȫ���������������ԵĹ��ס�
һ����صĿ�������ģ�Ͷ�������ͼ̽���Ŀռ���г�����Ч����Ρ�Ҳ����˵����ģ�Ϳ���ϵͳ�ض�Ŀ��ռ��ijЩλ�ý���Ƿ�Ȳ������������һ����ص�������ע��������������飬��ֻ̽�������ռ�����ص�����ռ����������ͨ����ȷ��������ע�ͣ������������ģ�ͻ����С������������ϴ�����е��ز���������ȣ��������ԵĿ����Ը��͡�������ӻ�ǿ�����������θ�������ģ�Ͳ����ռ�ĸ��ϸ�IJ��֣����ɱȽϵ�����ģ��ʵ����ʾ������Ŀɱ��ԣ�ͬʱ���������������б����˸���Ȥ��������
��ģ�͵Ķ�����Ҳ���û�������ʵ�����⡣��ģ�͵��㷨ʵ��������Ҫ�ض��ļ��裬����ܻ���ɽ�����ڷ��������������磬��ͬ���������������ʶ�����Ȥ��������ģ��Լ��ڿռ������������ӳ�䵽ԭʼ��������ʱ�Ƿ������ظ���ֵ������ڲ��졣ͬһ��ģ�͵IJ�ͬʵʩ����֮������ֲ�����ܻᵼ���ƶϵIJ�ͬ��
��ʹ���ض�����ģ���У��㷨ʵʩ��ϸ��Ҳ����Ҫ��������ͳһ�ض���ģ��ʵ�����г����Ǻ���Ҫ�ģ���ȷ���õ���ͳ�����ݲ�����ƫ����磬�������������ʵ�ּ�ʹ����Χ�ƣ�x,y,z����������ת��Ȼ��������˶�ijЩ��ת�Ĺ���������ͬ�ڻ��ڱ�������ת����QR�ֽ����ƫ����������ת����ֽ�Ϊ��������Q�������Ǿ���R�����������������㷨ʵʩϸ�ڵ����Ӷ��߶Ƚ�ʾ��һ����Ҫ�����⣺�������������ʲô���������Dz����ģ��������ʵʩ���������Ҳ����Ҫ����ǿ���˹���ʵ����ѡ��ģ�͵ײ���룬������������ϸ�ڵ���Ҫ�ԡ�
�������ָ����������ѧ�е�һЩ���ⲻһ����Ҫ����ģ�ͽ��л����ԡ����һ���о���Ŀ��������һ�ִ����������������ֲ�ͬ���壨�综�ߺͶ����飩��Ԥ��ijЩ��Դ����������֢״���س̶ȣ��ĸ�����죬��ô����Ҫ����֤��������Ԥ����δ�������еĸ�����죬������ȷ�ϸ�������ͳ��ѧ���Dz���Ԥ�ϵġ����仰˵���ȽϾ������ݺ���������е������������ṩ�й����ٴ�����ձ��Ԥ��Ч�õ���Ϣ��
չ���ͽ���
����ƪ���۵�������ǿ�����������ѧ����һ������������ͻ�����⡣���Ÿ�����Ӵ��������������ͳ��ת������ɻ��Ƶ����⣬��ģ�ͽ���Ϊ��ȡ��С�����Լ�����Ĺؼ�����Щ�����Լ�����Լ��Եؽ��ʹ�������ı�־����������ϵͳ�������巢�����������룬���κ��ܹ�Լ����������������ģ�͵ļ��ɽ����¸�������ǿ���nulls���Ӷ����Ը�ȷ�ز����۲쵽���������Դ����Щ���ģ�ͽ��������������ʹ���������������ģ�黯��hubs��rich clubs���������Ҫ�ԣ������ղ��������ԵĶ��������븱�������ֿ�������������νṹ����������Ĺؼ��ǽ���һ����ʽ���������ʽ�У���ģ�͵����������һ��������������ϵͳ�ز�����Щ��������Ϊ���������ĸ���������ġ�
һ����Ҫ��δ�����̽���ķ����ǣ��Թ۲�������з����Ŷ���̽���������ྭ�������Ĵ�����������ʵ�֡���������ѧ�У�������ͨ����ͨ����ȫ����������ģ��෴������ģ��ͨ����Ԥ���趨�õġ�Ȼ�������������̶���������ͣ����̽����ģ�Ϳռ��о���������ڽ����Ӷ������˽�������������ڽ�������������������ͻ��������Ϊ����������IJ����Ŷ��ṩ���⡣�����ַ�ʽ��������̶Ƚ��в�����������������ϵͳӳ������ռ䣬����������Լ����α���Ϊ���������ͽṹ��
���㷺��˵����ģ��������ѧ���������������ϵ��ͬ���Ե����빤�ߡ���ʵ�ϣ���Щ�����ܶ����������������������ѧ��ʱ�����з�������̬ѧ��������Ϣѧ��������ѧ�����������ʹ����ģ�ͽ����������顣����Ԥ��ͽ�����֤��Ϊ��Ȼ��ѧ������������������������ܣ�һ����Ҫ�����������ƶ�ģ����Ԥ��δ֪�������ض����������Ĵ��ں���Ҫ�̶ȡ������������˵������������֤������ģ��Ϊ������ѧ��ģ�͵ij�����չ��������ϣ����һ����
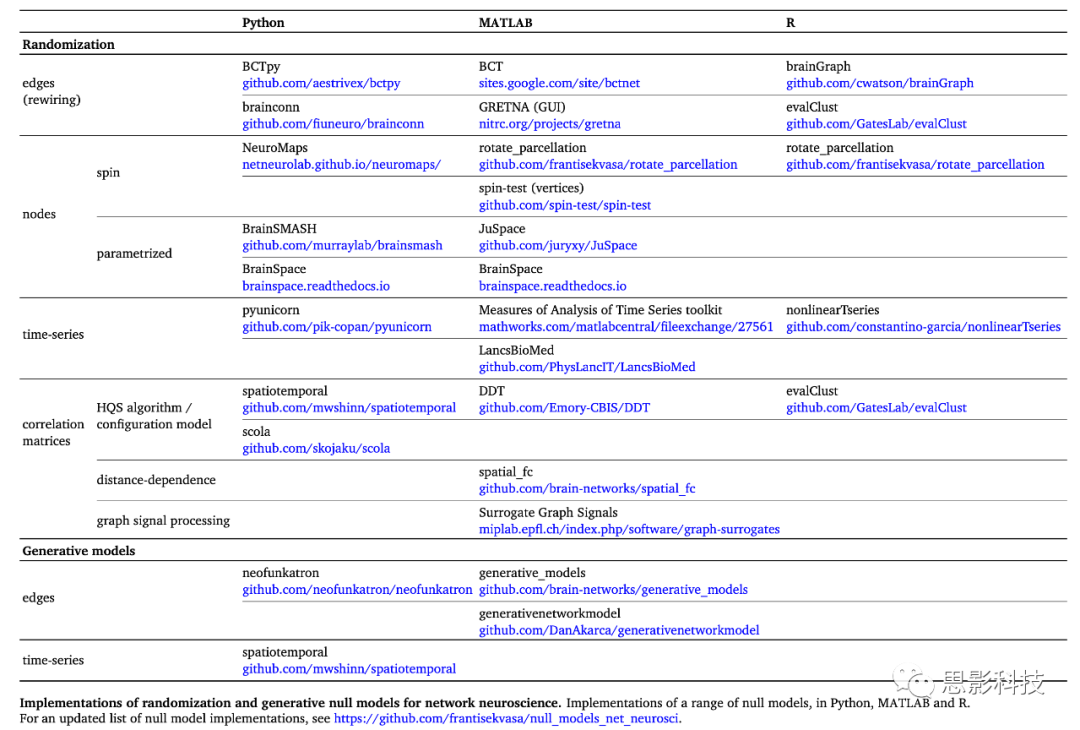
�Ӹ���ʵ�ĽǶ��������Զ����ģ�͵Ľ�����б������潫�ٽ���ȫ��Ŀ�ѧ���������ǹ����������Լ��Ĺ�����̽����Щ�����������1��ʾ��Python��MATLAB��R��������и����������������ģ�͵������о���չ��δ������ģ��Ϊ�����ع���������Э����������ṩ�����еĻ��ᡣ������˵����Ҳ���ٽ���ģ�ͷ����Ĺ㷺ʹ�úͳ�����չ��
����������ѧ��˵������һ���������ĵ�ʱ�̡������۵Ŀ��ٷ�չʹ�����ܹ�����ģ�͵���ʽ��ȷ�����֤α������衣����������ģ����ʹ�����ܹ��������ĺ�Խ��Խ��Ĺ��ڴ�������ṹ�����⡣��ģ�͵ij�����չ�ƶ����·��ֵIJ�������ÿһ��������У����ݶ�Ҫ��Խ��Խ���ӵ���ģ���Ͻ��в��ԣ��Ӷ������µļ��⣬��ʹ���ۺͷ����Ĵ��£����յõ�������Ϣ����������������ģ�͡���������������������ӣ����ǶԴ�������ṹԭ��������Ҳ����֮���
����ԭ�ļ��������������˼Ӱ�Ƽ��ţ�siyingyxf��18983979082��ȡ,���˼Ӱ�γ̼��������ȤҲ�ɼӴ��ź���ѯ����˼Ӱ�ṩ����������ط�������ҪҲ�����Ӵ��ź���Ⱥ��ԭ��Ҳ����Ⱥ�����������ǵĽ���������о��а����������ת��֧���Լ����½ǵ��һ���ڿ����Ƕ�˼Ӱ�Ƽ���֧�֣���л��
��ɨ����߳���ѡ��ʶ���ע˼Ӱ
�dz���лת��֧�����Ƽ�
��ӭ���˼Ӱ�����ݴ���ҵ�γ̽��ܡ�����ֱ�ӵ���������ּ������˼Ӱ�Ƽ����еĿγ̣���ӭ�����ź�siyingyxf��18983979082������ѯ�����пγ̾����ű��������������ǻ��һʱ����ϵ���������ѱ���ѧԱ�����
�˴ţ�
���죺
�ھŽ����������ݴ�����߰ࣨ���죬10.13-18��
����ʮ��Ź�����Ӱ������ࣨ���죬10.22-27��
�ڶ�ʮ�˽���ɢ�������ݴ����ࣨ���죬11.5-10��
��������ɢ�Ź��������߰ࣨ���죬11.17-22��
�ڶ�ʮ����Ź�����Ӱ��ṹ�ࣨ���죬11.27-12.2��
������
��ʮ�����������ݴ�����߰ࣨ������10.20-25��
��ʮһ��Ź���ASL������������ǣ����ݴ����ࣨ������11.3-6��
����ʮ����Ź�����Ӱ������ࣨ������11.9-14��
������Ӱ����ѧ�ࣨ������11.25-30��
�����R����ͳ�ưࣨ������11.16-20��
�Ϻ���
�ڶ�ʮ�Ľ���Ӱ�����ѧϰ�ࣨ�Ϻ���10.9-14��
����ʮһ��Ź������������ݴ����ࣨ�Ϻ���10.28-11.2��
����ʮ�Ž�Ź�����Ӱ������ࣨ�Ϻ���11.4-9��
�Ͼ���
����ʮ����Ź������������ݴ����ࣨ�Ͼ���10.16-21��
�ڶ�ʮ����Ź�����Ӱ��ṹ�ࣨ�Ͼ���10.24-29��
����ʮһ��Ź�����Ӱ������ࣨ�Ͼ���11.12-17��
�Ե缰���⡢�۶���������
����ʮ�Ž��Ե����ݴ����м��ࣨ������10.11-16��
���£���ʮ�����۶����ݴ����ࣨ������10.26-31��
�Ϻ���
�ڶ�ʮ���������Թ������ݴ����ࣨ�Ϻ���10.17-22��
����ʮ�����Ե����ݴ����м��ࣨ�Ϻ���11.13-18��
�ڶ�ʮ�˽��Ե����ݴ������Űࣨ�Ϻ���11.20-25��
�Ͼ���
������Ե����ѧϰ���ݴ����ࣨMatlab�汾���Ͼ���11.3-8��
���죺
�ڶ�ʮ�߽��Ե����ݴ������Űࣨ���죬10.28-11.2��
���ݴ���ҵ����ܣ�
˼Ӱ�Ƽ����ܴŹ���(fMRI)���ݴ���ҵ��
˼Ӱ�Ƽ���ɢ��Ȩ����DWI/dMRI�����ݴ���
˼Ӱ�Ƽ��Խṹ�Ź����������ݴ���ҵ����T1)
˼Ӱ�Ƽ����������У�QSM)���ݴ���ҵ��
˼Ӱ�Ƽ������ද���С����Ӱ�����ݴ���ҵ��
˼Ӱ�Ƽ��鳤�ද��fMRI����ҵ��
˼Ӱ���ݴ���ҵ������ASL���ݴ���
˼Ӱ�Ƽ���Ӱ�����ѧϰ���ݴ���ҵ�����
˼Ӱ�Ƽ������Ⱥ����ҵ��
˼Ӱ�Ƽ�EEG/ERP���ݴ���ҵ��
˼Ӱ�Ƽ��������Թ������ݴ�������
˼Ӱ�Ƽ��Ե����ѧϰ���ݴ���ҵ��
˼Ӱ���ݴ������������Դ�ͼ��MEG�����ݴ���
˼Ӱ�Ƽ��۶����ݴ�������
��Ƹ����Ʒ��
˼Ӱ�Ƽ���Ƹ���ݴ�������ʦ ���Ϻ����������Ͼ������죩
BIOSEMI�Ե�ϵͳ����
Ŀ��ʽ���ܴŹ���̼�ϵͳ����
