昨天,小芳(隔壁村的)问笔者:为什么我输出不了超过256个大脑区域?
乍一看,非常绕口。
今天的内容如果直接回答,恐怕绝大多数人要崩溃了,让我一步步给大家讲解,让你来回答这个问题。来,老铁们,双击666,送我上热搜。
宏观来讲,普通玩家对脑影像分析处理的步骤无非: 读取 -> 分析处理 -> 输出(写入保存)。这三个步骤会变的也就是中间这个步骤:分析处理。结合自己的问题来找到自己特定的分析处理方法。但是今天的重点主要是前、后两个步骤――数据读取与结果保存。通过MATLAB底层函数读取一个功能磁共振影像或者结构磁共振影像。
这些功能在基础的软件包里面已经集成了,但是对于喜欢脑 (no )洞 (zuo )大 (no )开( die )的我们来说,普通的软件包点点点已经不够了,这时候就需要一些深入底层的操作。从内部剖析磁共振数据了。
从磁共振机器里面拿出来的数据分成两个部分:头+脑影像。如下图:
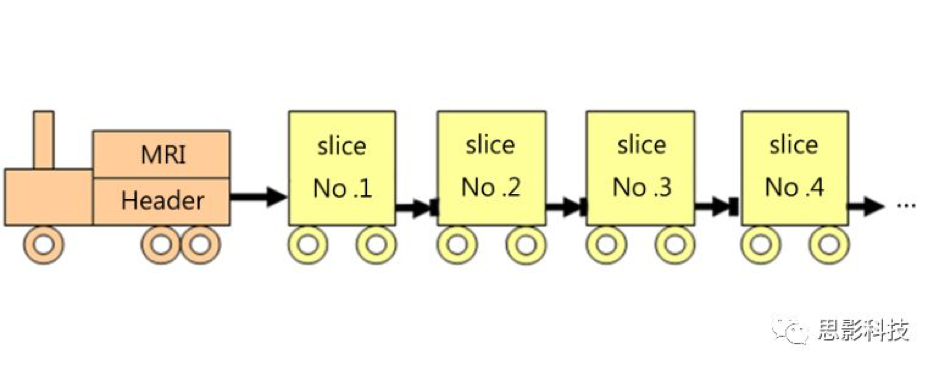
图1:磁共振脑影像数据结构图
可以用下图来理解:一个火车头,火车头里面装载着这个图像的信息,这些信息包含着层厚,层数,体素大小等等描述后面数据的各个信息。而每一层的脑影像就存放在后面的多个车厢里面。换句话说,那个火车头就像目录,而后面的车厢存放的是每一层大脑切片的信息。如图2所示:在计算机里面,每一层(大脑切片)的信息就是一张二维的图片,而数字的图片在计算机里面用离散的数值进行储存。每一个数值代表着当前切片颜色的深浅。

图2:每一个车厢里面装载的信息
上面的前期铺垫工作已经做好,读到这里,想必各位读者了解了磁共振脑影像在计算机中存储的数据结构形式,接下来进行非常高端非常娴熟的操作。
首先我们在MATLAB下面安装好SPM与 rest软件,基本的rest软件操作想必各位都会。(如果不会,请参考第五届功能磁共振数据处理基础班,广告在这里,意外吗?惊喜吗? )。如果你想从中挖出一些更加炫酷狂拽的东西,可以操作rest软件包里面底层的函数对脑影像进行分析。
1、读取:
比如对于今天我们先读取一个脑影像:运用rest_ReadNiftiImage函数。该函数基本用法如下:
[Data, Head] = rest_ReadNiftiImage(fileName,volumeIndex)或
[Data, Head] = rest_ReadNiftiImage(fileName)
别慌,我来讲解一下。
你可以理解为:
[火车车身,火车头 ] <= 函数名 (文件存放路径)
其中:
文件存放路径:你的C盘下存放一个AAL模板(名字叫aal.nii),如果你用windows系统那么文件路径就是 C:\aal.nii ,如果你是用linux或者mac系统的话,那么就是 /home/[your name]/aal.nii
火车车身:你读取出来的数据(aal模板是3维的数据,你可能看到他的维度是91×109×91的)
火车头:读取出来数据的头文件。(不用管它是什么啦)
2、写入(保存)
我们对这个火车车身的数据进行了一些非常恐怖的操作后(比如高阶相关、换成统计参数值、计算结构协变网络等等,恐怖吗?害怕吗?)要对结果进行保存,该怎么办呢?其实这里很简单,如果是全脑体素水平的操作,仍然把那个冒着黑烟的火车头拿过来,这次拉的货物就不是新鲜的猪肉了,而是已经炖好的猪肉了。换句话说:旧瓶装新酒。
保存方式如下:
rest_WriteNiftiImage(Data,Head,filename)
看见了没有,data已经换成了新的,而Head还是咱们当时读入的火车头,filename 就是我们需要保存的位置与文件名。这个文件名可以自己取,运用这个函数会自动生成。
总结:对于写入和保存,读取文件的时候拉来了一火车的数据,这一火车的数据包含着:火车头,和很多车厢的数据。我们对各个车厢的数据进行处理,处理完毕后继续装回车厢,挂上火车头继续开走。
唱着歌儿,小火车呜呜呜地开,一切都是这么美好!
==============美丽的分割线=============
香烟啤酒饮料瓜子矿泉水八宝粥,脚让一让下~
喝茶,上厕所,听歌
=========两个小时过后==========
咦,谁动了我的数据?
我明明存放的是有小数的,为什么全部变成了整数?
我的数据明明数据范围是0-9999,为什么火车开过来,我拿到手上数据范围变成了0-255?
为什么我的数据结果和你的不一样?
有鬼!
在解答以上问题之前,我问各位一个问题:我们的磁共振脑影像数据大小为什么有的一样,有的不一样?换句话问:数据大小由什么决定的?
图3:不同影像数据,不同大小。
看过网络电视的朋友们肯定知道一点:高清4K和流畅画质是两个截然不同的概念。一般看着超清的视频消耗的流量更多,而看普通标清的画质的视频消耗的流量更少。于此进行类比,画面的分辨率决定着数据的大小。在磁共振这里也是类似――为什么一个3维脑图,T1加权的结构像更加的清晰,而功能像更加的模糊?这个是因为T1像分辨率更加高。
结论1: 分辨率更高的影像数据更大
但是我们的问题仍然没有解决,我明明存放的是有小数的,为什么全部变成了整数?
在这里补充一点计算机的背景知识:
在计算机中用 char 型的数据用1个字节保存,一个字节8位二进制。表示范围2^8=256。换句话说,char型数据只能保存 -128~127 之间的数值,而unsigned char就抹去了负数部分,描述了 0~255范围之间的数值。(绿皮有窗火车)
在计算机中 short 型数据 用2个字节保存,也就是16位二进制 2^16 = 65,536个数值,但是注意,他与char型一样,都只能够描述整数。(普通红皮蓝皮车)
在计算机中 double 型数据 用8个字节保存,自己算算可以表示多少数据。double可以描述小数,但是注意:这个小数是有16位精度限制的。也就是说double是用科学计数法来表述一个数值的。对于一般的应用是足够的。(高铁plus版)
有了以上知识,不用你们猜,我直接公布答案了:因为在不同的磁共振影像数据中需求不一样,所以采用的精度可以是不一样的。比如只想描述脑岛区域,此时只需要一个二值模板就好。也就是说描述一个体素,用1个字节的数据就可以了。如果我想看看范围更高,或者精度更大的高端操作后,此时就需要修改头文件了。不能直接拿着小火车来当高铁来用了。
因为修改文件太复杂而描述脑影像的数据类型过多,在这里就暂时不做详细补充(怕普通玩家智商不够用)。只告诉大家两种方法来解决脑影像数据类型不够的问题:
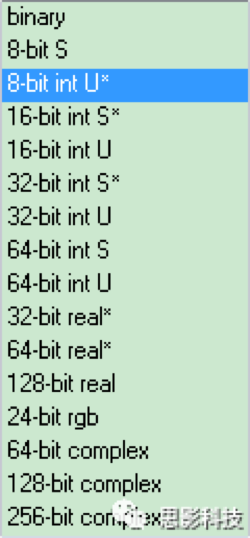
图4 描述脑影像精度大小
方法1:功能像另外读取一个相对较大的文件的头文件,借用那个文件的火车头来写入新的数据。
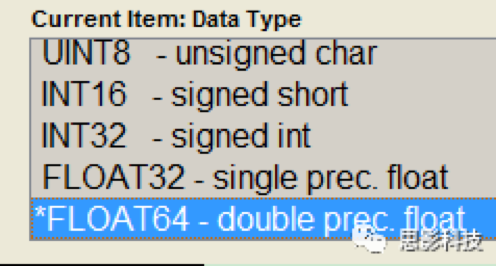
方法2:SPM内的 Batch -> util -> 3D to 4D convertion 选择DataType,选择哪一个?要充分发扬中国人的好大喜多的思维啦(篮框选的虽然大,拿着牛刀不管杀鸡还是杀鸟都是够了的)
最后,对应开头。小芳问笔者:“为什么我输出不了超过256个大脑区域?”现在聪明的你,来帮我回答回答这个问题吧!
最后,让我们来一起缅怀下,我心目中浩气长存,伟大的冯诺依曼,冯老师:

计算机之父――冯・诺依曼(John von Neumann,1903~1957)
不发个广告,总觉得会有些许遗憾与不舍:
第二届磁共振DTI(弥散张量成像)数据处理班来,我们一起TRA起来!
第三届磁共振脑网络数据处理班网络连接你我他,经鉴定,是真爱,没错。

这么优秀的公众号,不关注下,轻则怅然若失,重则抱憾终身