���Է���������Ϣ���Զ����о�����Engemann������Brain��־�Ϸ��ģ������˲�ͬ��EEG���á�EEG�����ǡ�����ģ���ڱ����ʶ�ϰ�����ʱ�����ܲ��죬�������������ڵ�һ�����ǣ����ǿ����Ļ��ڶ��������ǵ�DOC-Forestģ���ڲ�ͬEEG�����¾��и�ǿ��³���ԣ������EEG�������У���theta��alphaƵ����̬������صı��Ӱ�����
ȷ����ʶ�ϰ����ߵ���ʶ״̬��һ��������ս�Ե�ʵ�����������⡣������о������������EEG����ȡ�Ĵ��Ի�Ķ��ֱ���������Ϊ���Ե���ʶ״̬��ָ�ꡣ���⣬���ٴ�ʵ���У����Ƿ������û���ѧϰ�������������ֲ�ͬ����ʶ״̬��Ȼ��������ʵ��ʹ����������EEG���á�EEGʵ�����ͺ����Բ�ͬ���ĵ����ֵIJ�ͬ����ЩEEG���������źű���ʱ�Ŀɿ����в������
Ϊ�ˣ����Է�����ParietalС���Engemann������Brain�����о������⣬�������о��У������������������о�����(Paris Pitie -Salpe trie are��Lie 'ge)��õ�327�ݹ�����ʶ�ϰ�����(148����Ӧ�ٶ۵ľ����ۺ�֢[unresponsive wakefulness syndrome]��179�������ʶ״̬����[minimally conscious state])��66�ݽ���������ļ�¼��
���ǵ��о���һ�α��������ڷDz����������ľ������ṩ��³������������֣�Ԥ��������µ����(AUC)Ϊ0.77������ʹ�ò�ͬ��EEG����(��ͬ������λ�õĵ缫���ֶ�������ƽ��AUC = 0.750 �� 0.014)ʱ����һԤ��ֻ�ﵽ��Ե�������ڵڶ����У����ǹ۲��˻��ڶ���͵���EEG�����ķ��������������Բ�ͬ����Ⱥ��EEGʵ�����ͺͲ�ͬ���ĵļ�¼���ݡ�Ȼ������ģ̬�ı�����ã���Paris 1��Paris 2���ݼ���Ԥ��AUCΪ0.73����Paris��Liege���ݼ���Ԥ��AUCΪ0.78��ͨ������ģ�⣬�������֤��������EEG�����ȶ��ԵĽ��ͣ���ͬ��EEG��������������ȡ����Ϊ����������������ģʽ����ȵ�����������о����Ե��������������⣬���ǻ���������ʹ�ߴ�20%����ϱ�ǩ������Ʒ�����Paris��Liege�ķ���������Ȼ�����ȶ�����������������һ�£�ͨ�������Ƿ�������ѧϰ���߹���ķ��������Ƿ�����theta��alphaƵ����̬������صı�Ǿ��ж�������Ϣ��Ӱ����������ǵ��о�����������ڲ�ͬ���ٴ���ϰ�û����У�EEG��ʶ�������Ա�����ѧϰ�����ɿ������ú��Զ���ʶ��
�ؼ�����EEG;��ʶ�ϰ�;�����־��;����ѧϰ;���
Abbreviations��
AUC = areaunder the curve���������;
DOC = disorders of consciousness��ʶ�ϰ�;
MCS = minimally conscious state�����ʶ״̬;
MVPA =multivariate pattern analysis�����ģʽ����;
UWS = unresponsive wakefulness syndrome��Ӧ�ٶ۵ľ����ۺ�֢;
wSMI = weighted symbolic mutual information��Ȩ���Ż���Ϣ
1����
������ʶ�ϰ�(disorders of consciousness��DOC)�Ļ���֤������ȱ����ʶ��Ϊ֤�ݵ�����£����������ǿ��ܵġ�����Ϊ�ﵽ��ʶ��������������Ŭ������Ŀǰ����ϳ������������������ã���˺����׳�������������ٴ�ҽ�����ж϶�û�б�������Ϊ������DOC���ߵ�����̶ȿ��ܳ���40%����ʹ��ʹ��������Իָ���������(Coma Recovery Scale-Revised��CRS-R)����Ϲ���ʱ����������ڶ�ʱ����û�з�����������������Ȼ�ܸߡ����⣬��ijЩ����£���Щ���ߴ�����ʶ�ӹ���֤��ֻ��ͨ�������������ã�����������£�������ʱ����ֳ�������Ի��������ڡ���Щ���߱���Ϊ������ʶ��covert awareness������֪�˶�����(cognitive motor dissociation��CMD)���ߡ�
��DOC�У����ǿ������ֻ���״̬����Ӧ�ٶ۵�ʧ���ۺ�֢(UWS��ǰ����˵��ֲ����״̬)�������ʶ״̬(MCS)�������۾�����������UWS���ߺͻ��Ի��ߡ����⣬MCS����UWS������ʾ����ʶ�ļ���(��MCS�е��Ӿ��ٺ�MCS+�е�������ѭ)����δ��ʾ�����ԵĹ�ͨ������ʹ�á�Ȼ��������������Щ�����в��ֵغͲ����Ķ��Լ�����Χ��������֪�����Ҹ��п��ܿ�������ǿ���˿ɿ�����Ϲ��ߵ���Ҫ�ԡ�
�ڹ�ȥ��20������������Գ����Ѿ������˼����ʶ����Ϊ���������ȵ�˯���о�����ѧ������ʾ����delta (2�C4 Hz), theta (4�C8 Hz) ��alpha (8�C12 Hz)Ƶ������ʾ�����ȸı��EEG�����PET�о���ʾ���뽡����������ȣ�DOC���ߵ���������ȡ�����������½���һЩ�����Ժ˴Ź����о���ʾ��DOC���߲�ͬƤ���º���Ƥ��ͨ·�Ĺ��������жϡ������Ժ���֪��ѧ�Ľ���ʹ�������ܹ���Խ��Խ��ϸ�Ĵ��Իģʽ���ƶϳ���ʶ����ˣ�����Ƥ������֮��������Ի������Լ����ԶԴ̼���Ӧ����̬�����ԣ�������ʶ״̬�йأ��������ʶ����������ּ����Եı�ǡ�
���������Ӱ��ѧ�ķ�չ���ƣ�Խ��Խ�����ʶ��ǿ��ܵ���õķ����Ƕ����ģʽ����(MVPA)����ʵ�ϣ�����ѧϰ�㷨����ͨ��ѵ������δ֪����������������õ�Ԥ�ⵥ�����˵�ҽ��״����ͨ������£�����������ݴ����������Ż������ٴ���ǩ��Ȼ��ͨ������������Ԥ����ʵ����Ͻ��бȽ��������������ܡ���ȱ���������ݼ�������£�ͨ��������ϸ��Ϊѵ�����Ͳ��Լ������Բ��Լ��÷ֽ���ƽ�������н�����֤�Թ�������������ܡ�Ȼ����ֵ��ע����ǣ�����������Сʱ��������֤���������ֹۣ�ʹ�����൱��������Ӱ��ѧ�о��У������ֵ�Ľ�������Ч�ġ�MVPA����DOC�����о������Ӱ���������Ϣ״̬FC��ģʽ��ָ�����Ƶ����Ӧ�Լ����Դ�л�������ı�֢���ߺ�UWS��
�ڴ˱����£�EEG�ر���Ȥ����Ϊ����������ѧ������������֪�����ķḻ��ʱ����Ϣ��Ŀǰ�����ģ��������EEG���ݵ���ս�������Զ�����EEG���������������Ȼ��������֪���ۺ�EEG������ƫ���ڸ���ʵ����֮���Dz�һ�µģ��⼫����谭�˴���������Դ�Ŀ�������Щ������Դ�dz��ʺ��ڸ߱������ѧϰ������Ϊֹ�����ֵ�EEG�����ɷ�Ϊ�ĸ�������塣�շ�����Evoked markers���ǻ��ڶ���֪ʵ���ʱ�������¼���ط����������������������ʵ�����͵ı�ǣ��������ô������罻�������ӱ�ǡ�����ʱ��������Ϣ���Ե���Ϣ�۱�Ǻ�������Ԫ������������Ķ�̬Ƶ�ױ�ǡ�Ȼ��������DOC��ӳ�˼�����֪����ϵͳ�ijɷ֣������ǵ�һ��ά�ȣ��Ӷ������˴�ҶԱ�ǽ��в�д��˼����ʹ�������ø��Ӹ��ӡ��������һ���о��У�Sitt����(2014)ʹ��֧��������(SVM)��������������150����߾���EEG��¼�еļ�ʮ��EEG������Ȥ���ǣ����������ЭͬЧ�����ڵ�������ͬ���ģ�Chennu����(2017)����ͼ�۶�alphaƵ�������ӽ����ܽ�����������һ�ֻ���SVM�ķ�������104�����������˻���(89����������DOC����)���ݽ�����ѵ���ͽ�����֤��
������ˣ��������˻�����ʶ״̬�Ľ���Ԥ��Ĺ㷺�Ĵ��ģ������Ȼȱʧ�����Ҽ���ʵ�ʵ�������Ȼû�лش𣺵���EEG��¼����ѳ���ʱ���Ƕ���?����Ӧ�ý�����Щ����?Ӧ��ʹ�ö��ٸ��缫������Ӧ�÷�������?һ����һ�Ļ���ѧϰ�㷨�ܶ����Բ�ͬ�ٴ����ĵ����ݽ��з�����?���ڵ�ǰEEG��ǵ��ģ���Ƿ�Զ�������ʵ��ǰհ���ƹ�?��һ����Ƿ��㹻ǿ��?��Ԫ��������ʱ���ṩ�����Ե����ƣ�
Ϊ�˽����Щ���⣬�����ϸ��̽������ʶ��EEG������³���Ժ���Ч�ԡ�ʹ��³���Եļ���������㷨(Geurts et al., 2006, ET��Extra-Trees��Extremely randomized trees�����������������PierreGeurts������2006����������㷨�����ɭ���㷨ʮ�����ƣ�������������������ɡ�)������һ��������������UWS��MCS����(���dz�֮ΪDOC-Forest)���÷�����ʹ��������ParisҽԺ��249�����ߺ�����Lie`ge��ѧҽԺ��78�����ߵ��ܹ�28��DZ�ڵ���ʶ��EEG��������ѵ���Ͳ��ԡ���������չʾ�˲�ͬ��EEG����(�缫������λ�úͷֶ�����)��EEGʵ������(�����̼���Ϣ״̬)��EEG�����ķֲ��������϶��������IJ�����Ȼ�������Ƿ��֣�ͨ�����ÿɿ���EEG��������ݵ���Ϣ��DOC-Forest�����ֱ���������ߡ��������չʾ�������������ݼ��������ⷺ������������Paris��107������EEG��¼(֮ǰû�з�����)������Lie`ge��ѧҽԺ��78�ݾ�Ϣ״̬��EEG��¼�����⣬���ǻ�֤����DOC-Forest�ķ��������������ڵ�������ǡ����ͨ���о������Ƕ�DOC-Forest���ߵ�Ӱ�죬���Ƿ���alpha-Ƶ��������theta-Ƶ�������Ӻ�ʱ�����и��Ӷ�Я���˹�����ʶ״̬�Ļ�������Ϣ��
2�����뷽��
2.1����
�����о���������327������������ר�����ĵ�268����ͬ���ߵ��Ե�ͼ��¼(��1)�����߱�����Ϊ��ͬ�̶ȵ�(����ʱ��)�ӳ�(�����˺���Ǽ��Ի����Խ�)������ȷ��ʶ��ʵ��״̬���ٴ�����������Paris���ݼ��н������Σ���Liege���ݼ��н�����Σ����в����ڲ�ͬ��������ѵ�����ص��ٴ�ҽ�����У���ϵͳ�ذ���CRS-R��CRS-R������0��23���ȣ���ӳ�˸������������Ӿ����˶����Ӿ��˶��������ͻ��ѹ��ܵIJ�ͬ�ȼ�����IJ�����Ŀ���Ƿ��з�Ӧ��������õ�������ÿ�����˶�����ϳ�����UWS��MCS�����������ģ����ݲɼ�Э���������ٴ�����������һ��EEG��¼������һЩ���ˣ���һЩEEG��¼�����Ǻ�����ͳ��ģ�ͽ����˽��͡���ͬ���ݼ��ļ�¼��������ܴ�Ȼ����MCS��UWS���ߵı�������ƽ�����������ݼ������Ի��߶���Ů�Ի��ߡ�����ֲ����ƣ�Ȼ�������ھ�Ϣ̬���ݼ���˵���ӳ����Ը��ߡ�ͬ������Ϣ״̬���ݼ��IJ���ֲ�Ҳ��ͬ��������������һ�¡�
��1. �������ݼ��IJ�����Ϣ
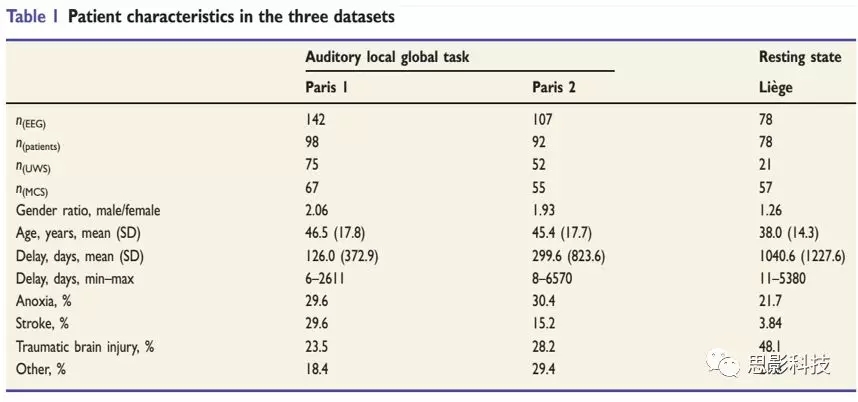
2.1ʵ�鷶ʽ
�ּ�����oddball����(Paris 1 & 2���ݼ�)��������ص��Ե�ͼ�ź���Դ�ڡ�Local-Global��Э�飬ּ���о�����ʶ������ʶ�������ӹ�����Ӧ�أ����Զ��������͵������¼��ķ�Ӧ����¼�������Զ�������ʱ�䷶Χ��Υ���ͳ�ʱ�䷶Χ��Υ�������ǵ�ʶ����������ȷ�Ĺ�������Ŭ����Ϊ�˻����ѵ���֪���֣���������ֹͣ������24Сʱ���м�¼�����ܸı��Ե�ͼ��ҩ����缡���Ե��Ϳ����ҩ��û�еõ����ơ���ÿ�μ�¼��ʼʱ�����Ե�ͼ�ź�������������������۲쵽�������������Կ�ʶ����쳣�����ֹͣ��¼���Ե�ͼ��¼�ɼ���250HZ��ʹ��256���缫(EGI)������ο�����ͨ����(��0.5��45Hzʹ��6��8��FFT-based������˹�˲���)��Ȼ������ڵ�һ�������ij��֣����ݷֶ�Ϊ-200ms--1336ms���ο�Engemann����(2015)�У���������Ӧ�쳣ֵ���ķֶα��������ʹ��ƽ���ο�������У����
��Ϣ̬(Liege dataset): ���ݱ��ֶγ�1536ms��ƥ���������̬���ݵij��ȣ�������ƥ������������Դμ�������⣬������ͬ�����ݲɼ�Ԥ����������
2.3��ʶ�Ŀ��ܵ��Ե�ͼ������ѡ�������
������ϸ��ȡ��Sitt���ˣ�2014���ٶ���28���Ե�ͼ�����־������ɷ�Ϊ��Ϣ�ۡ���ͨ�ԡ�Ƶ���շ���Ӧ������ĸ������壨��2������Sitt����(2014)�������ļ�����ͨ�Զ����У�����ֻ������thetaƵ���еļ�Ȩ���Ż���Ϣ(weighted symbolic mutual information��wSMI)��������֮ǰ���о��������������Ͻ�������ʶ��ص�Զ������ģʽ���ܱ�����������Ƚ���ȷ��������ע�⣬���ھ�Ϣ״̬�Ե�ͼ�ķ���������û��ʹ���շ���Ӧmarkers����Ϊ��Щmarkersֻ����Paris���ݼ���ʹ�õ�����
��2. DZ�ڵ���ʶEEG ������

�ٴ���ѧ�г��õı����ͨ������һ��ˮƽ�϶���ģ������ڶ���缫��ʱ����Ƶ���Ϲ۲쵽��Ϊ�������ͼ����ԣ����Ǵ�ÿ������м������ĸ�����ͳ����Ϣ(ͼ1)��Ϊ���ֶܷΣ�����Ҫô����80%��β��ֵ��Ҫô�������(SD)��Ȼ���þ�ֵ��������ܽ�缫���ܹ��õ�������ϣ�ͼ1A�������ǰ���Щ��������ͳ�Ϊ��mean,mean��,��std,mean��,��mean,std��and��std,std������ͼ�У���дΪ��m,m��, ��s,m��,��m,s��,��s,s�����йص������б�����д����μ���2��
ʹ��ָ����Python��������м��㣬ʵ����Sitt����(2014)��biomarker��ȡ���ܡ���ȡ�ı����ο����ݼ���ԭʼֵ�ͷ���������ƥ�䣬���Ե��ظ���
2.4ͳ�Ʒ���
2.4.1�Ե�ͼ��������ʶ�ϰ��ķ���
���õ������Ͷ��������ѧϰ���ԣ������Ե�ͼ��������Ͻ��з��ࡣΪ�˱��ڿ��о����бȽϣ����ǻ������˵�������ϵ���ģ��ʱ�ı��֣���Sitt����(2014)��ʹ�����������(AUC)�������ܣ�see Supplementary material��Area underthe curve metric��section�����Զ�����͵�����ģʽ����������ѡ���˼���������㷨�����ķDz������������³���Է��ࡣΪ�˲������Ե���������ļ��⣬���Ǹ������ʵ�������Extra-Trees����ȡ����ν�ı�����Ҫ�ԵĶ���������ǿ�ɽ����ԡ���ˣ����ǵı�����Ҫ�Ե÷ַ�ӳ�˱��������֮��Ļ���Ϣ��ͬʱ��Լ�����������йز�����ģ�͵��ŵı�����Ϣ��������Ϣ��see Supplementary material��Multivariatepattern classification��section����Ϊ���ڱȽϵ�������ǺͶ������ǵ�����ʱʹ��ͳһ��������ʹ����DOC-Forest��ͬ�ķ�������ʹ�����ܹ�ʹ��������������ͬ�Ŀ�ܣ��ӵ��������Ԥ��DOC��ϵĸ��ʡ�
2.4.2ͳ���ƶ�
����ʹ�ðٷ�λ����bootstrap(�������)�����ӻ���չ����������С�Ϊ�����������ⷺ��������ʹ�������ֻ����ķ���:�Զ������ݵı�����֤(�µ�Ⱥ�塢��ͬ��Э��[ʵ������]��ʵ����)�ͽ�����֤(�������)��
2.4.3����
�������ݶ�ʹ��Python������Խ��д�����Ϊ�˼���ѧϰ��Ԥ������������ȡ�����ǿ�����һ��ָ����������(available at https://github.com/nice-tools/nice)�������ڿ�Դ������MNE֮�ϵĺͻ���ѧϰ�㷨�⡣DOC-Forest�����ǹ�����(https://github.com/nicetools/nice)����������һ��Ŭ������������ʶ״̬��Ԥ��ģ�͡�����ʹ�õ��ٴ����ݿ����ں�����Ҫ�����ṩ���������漰���ߵ��ٴ���Ϣ�������ԣ�����Э�鲻�����������ݹ�����
3���
3.1���Ե�ͼ��������ʶ״̬��³�����
3.1.1 UWS��MCS�Ķ����������EEG��������³���Ե�
DOC-Forest������ƽ������ΪAUC = 0.75(SD = 0.014)��������������Ǹ�����ȣ����ǵı��ָ��ã�Ҳ��³��(Fig. 2A, B, Supplementary Figs 1 and 2)�����⣬���ŵ缫���������ӣ���ʶ������Ҳ�������(Fig. 2B),����16���缫��5%�ķֶ�����ʱ���������Ѿ��ֺ��ˡ���Ҫ���ǣ�ʹ��ȫ���Ե�ͼ���ã���������Sitt����(2014)֮ǰ����Ľ���dz����ƣ����������κ����������(Supplementary Fig. 2)����Щ����������ڲ�ͬ���Ե�ͼ�����£�DOC-Forest���ȸ�����һЩ������³����Ǵ��ݵ���Ϣ��������������ֵ�EEG���á�
ʹ�����������ã�������������˲�ͬ������Ͳ�ͬ�̶ȵ����Լ����ķ���ɹ���һ����(Supplementary material��Consistencyof classification results in diagnostic subgroups��section)�������Բ��飨delay>30 days���ͼ��Բ���(delay<=30 days) �����˱Ƚϡ���������ķ������ܾ�����(����ȱ�����з缰������)��Ȼ�����ڴ����������˻����У������Եͣ��������һ���������ʹ����ѷ��ࡣ�ڵ�����Ǻ�DOC-Forest֮����еĶ������ϸ�Ƚϣ���������ϣ�Detailed comparison between individual markers andDOC-Forest����
3.1.2 theta-��alphaƵ������ƫ�÷�����
��Ȼ�����ǵ�DOC-forest�е�2000���������������������������㣬����������Ȼ����ͨ�����DZ�����Ҫ���������Ե�ͼ��ǶԷ������ܵ���Թ��ס�������������������һ����Ǻ����֮��Ļ���Ϣ��ͬʱ����������ǵĹ��ס����ۺ�ʱ������־��֮�乲����Ϣ��ģ��ʶ��������Խ���ЧӦʱ��������Ҫ�Ի�ϵͳ��ƫ�뵥����AUC���ڼ����36�����õ�����DOC-forest�����������Ƿ��֣�ƽ�����ԣ��������ı�����ڲ�ͬ�ĸ�����壨ͼ2C����������˵����thetaƵ����alphaƵ�������ϵ��û��غͳ�����ͨ���ڵ�����ʶ��ͱ�����Ҫ�Է���������������֮�£��շ���λ�ı�ǵ�ƽ��ֵͨ������0.89%��������б�Ǿ���ͬ��Ӱ����ʱ������ڵ�Ԥ��ֵ�����ǹ۲쵽ƽ��AUC��ƽ��������Ҫ��֮��������ķ����Թ�ϵ�����Կ������������Թ������ԣ���������ı���ڱ����ϱ�Ԥ�ڵĸ���Ҫ��ͼ2C����
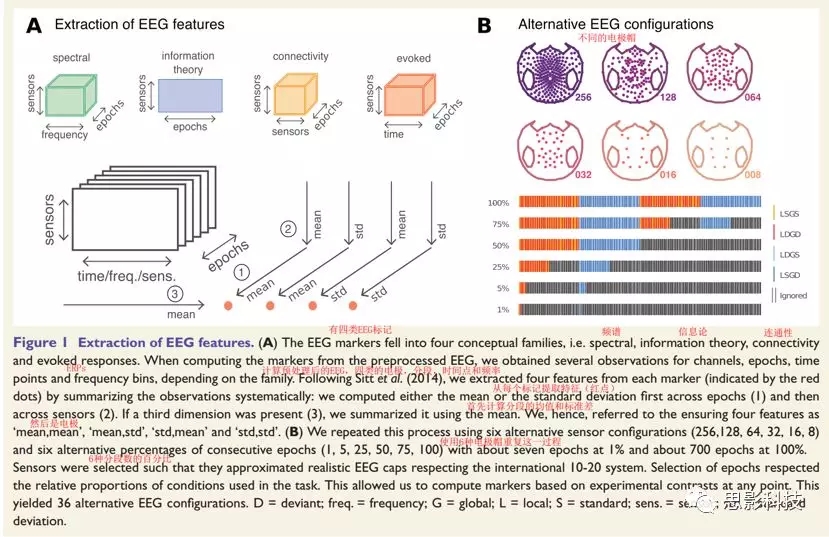
ͼ1. EEG��������ȡ
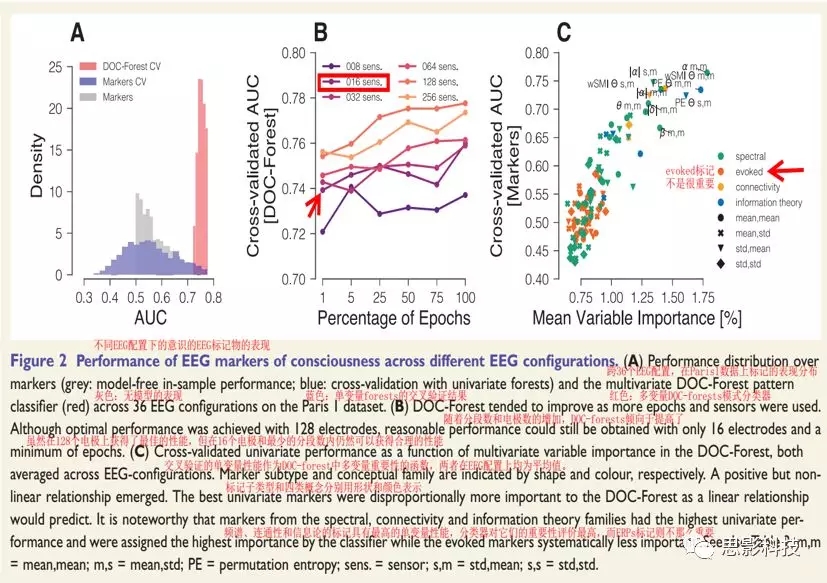
ͼ2.��ͬEEG�����µĸ���EEG�����ǵ�����
3.2 ������ʶ�IJ����Ե�ͼ�������з���
3.2.1 ���������������ݡ�ʵ����ƺ�����
�������ǿ�����������������Ⱥ������Paris��Paris2����107������̬���ݣ��Լ�����һ�������о�С���78����Ϣ̬����( ��Table 2)������Paris 1���ݼ���ѵ��DOC-Forest������Paris 2���ݼ��ϲ����㷨ʱ��ÿ��ʹ��������EEG����ʱ�����ǹ۲쵽��AUCԼΪ0.73������£���������������ͼ3A����ͬ���أ�������������Paris�Ŀ������ݽ���ѵ��ʱ(Paris 1 and Paris 2)������ѵ��ERPs���ʱ����1��ͼ1A������Lie`ge��Ϣ̬���ݵIJ����ϣ�DOC-Forest��AUC��0.78��
������������������ڰ������ݼ���ѵ���ķ������ķ����̶ȣ�������UWS��MCS������66������ʶ���Ƶ����ݼ�������������DOC-Forest��94%�Ŀ��Ʊ��Է���Ϊ(Paris local-global paradigm: 34 of 36, Lie`geresting state: 28 of 30)MCS����һ���������������������UWS��MCS���ߵ�ģʽ�������Ƶ����������顣
���⣬���ǻ���Liege���ݼ��з�����������֪-�˶����뻼�ߡ���Щ��������������ǵ���Ϊ������UWS�ı�ǩ����ʹ�ú˴Ź������ʽ��������������ʶ�ӹ�������������DOC-forest����ΪMCS��
3.2.2 ʹ�õ�������ǽ��з���
������ͨ�ԡ���Ϣ�ۺ�Ƶ�ױ�ǵĵ�����ɭ�֣��佻����֤������ѵ��������ߡ����е�����ģ�͵ķ�������(0.04 ~ 0.14 AUC��)������DOC-Forest��ֻ��alphaƵ���������ķ��������������������������ͼ3���м䣩����������Ҫ����ÿ����ǵ����������ܽ��бȽϣ����������ķ����Թ������������������������ģ����AUCֵ����0.70������±��ֳ������ķ������ܣ���ͼ3����
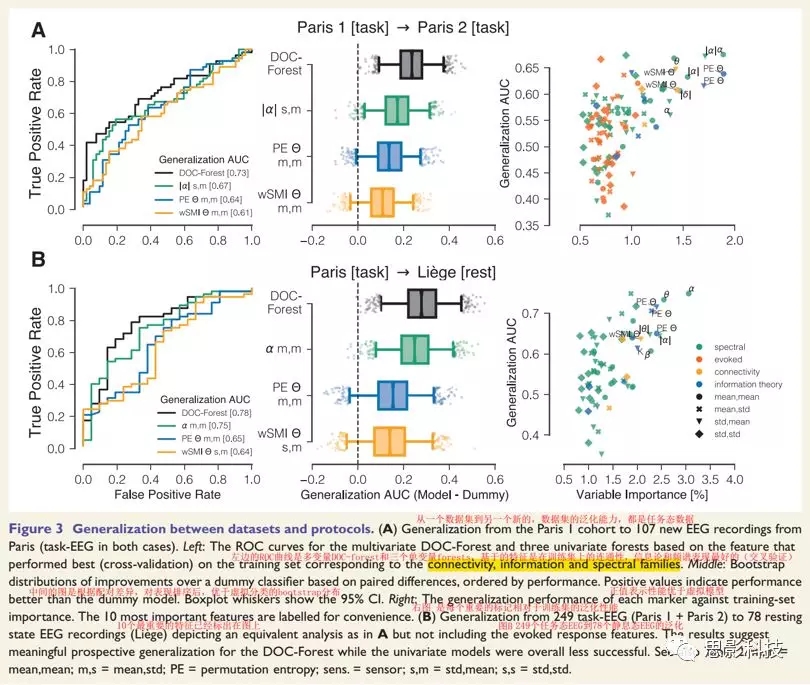
ͼ3. ��ͬ���ݼ��ͷ����µķ�������
����עĿ���ǣ�����ͬ���Ե�ͼ���������һ��ʱ�������dzɹ��ģ�����100%�ķֶκ�32���缫����ѵ����50%�ķֶκ�8���缫���в��ԣ����������ѵ���Ͳ��Լ�֮��Ľ�����졣ƽ�����ԣ�DOC-Forest�ı������Ը���������Ӧ�ĵ�����ɭ���е��κ�һ������3�����Խ������÷���ģʽ�ļ����ʾ�����ܵı仯����������ģ����������ַ��������ⶼ֧���˷ֶκ͵缫�Ķ��ص���ͬ����ϡ�
��3. ��ͬEEG�����µ�ƽ����������

3.2.2 ��������³����
����DOC-Forest�ƺ��Բ�ƥ���EEG�����е��ԣ�����ͨ������Լ��еı����������������Ӧ�����ԣ�stress-test����ֱ������ʧЧ��ͼ5A�����������⣬�������������ܿ��ʧЧ�ˣ���DOC-Forest�����˺ܾò�ʧЧ����һ���������Ʒ������ܵ������������Ϣ���������ڵڶ���ѹ�������У�����ʵ֤�������������Խ��Խ��ȷ�����ѵ����ǩʱ����Paris��Lie`ge�������ȶ��ԣ�ͼ5B����ͨ����ƣ�����ģ����ʹDOC-Forest���������ղ���ϵͳ�����Ԥ�⡣Ȼ������������Ȼ�ṩ�˺�����Ԥ�⣬��ʹ�ߴ�30%����ϱ�ǩ���Ʒ������⣬���ڱ��о���ʹ�õ�CRS-R�ظ�3 -5�Σ�������Ԥ�����6%-17%��������������ڵ��Է�����Χ����Щ���������DOC-Forest�������е���������ϱ�ǩ�е��������н�ǿ��³���ԡ�
4 �ܽ�
ʹ�ü���������㷨������28�����ϵ��Ե�ͼ��ʶ�����־������˶Բ�ͬ�Ե�ͼ���ú͵������������ģʽ��¼������³���ԡ���������֪�����ǵ��о������˻���ѧϰ�������UWS��MCS������㷺����֤��
���������UWS��MCS���߿����ö�����������ȶ�����ϳ�������ʹѵ�����Ͳ��Լ���EEG���ò�ͬ��ͼ4����
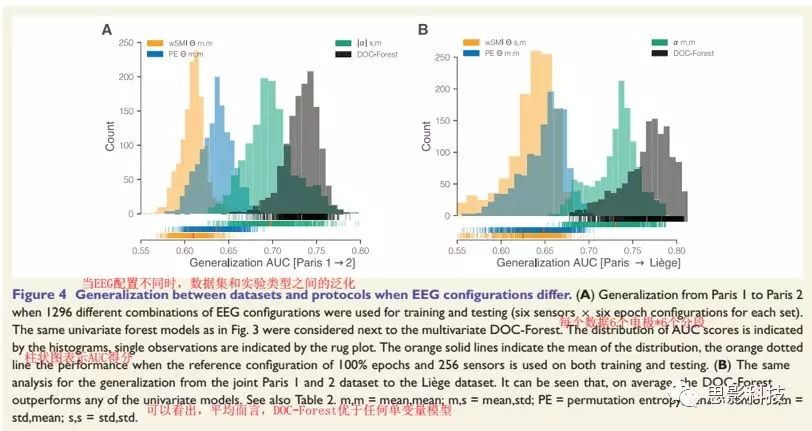
ͼ4. EEG���ñ仯ʱ����ͬ���ݼ��ͷ����ķ�������
Theta��alphaƵ����־����³���ķ������������ڲ�ͬ��ʵ����ƺͻ����п��Է�����Ҳ�Ǵ�����̬����Ϣ̬��������Ҫ��־�
�ο����ף�Engemann D A, Raimondo F, King J R, et al. RobustEEG-based cross-site and cross-protocol classification of states ofconsciousness[J]. Brain, 2018, 141(11): 3179-3192.

��ɨ���ע˼Ӱ�Ƽ�
���������Ӱ�������Ѷ
��ȡԭ�ļ�������ϣ���ע��˼Ӱ�Ƽ������ںţ��ظ���ԭ�ġ�����ѵ������ȡԭ��pdf����������������ӣ�ͬʱ��ӭ������ǵ���ѵ֪ͨ�Լ����ݴ���ҵ����ܡ���ֱ�ӵ�����ɣ���
�������Ե��ź����ݴ�����߰�
����֪ͨ����һ���Դ�ͼ��MEG�����ݴ���ѧϰ��
��ʮ���Ե����ݴ���������
��һ���۶����ݴ�����
���Ľ�������Թ������ݴ�����
��ʮһ�칦�ܴŹ������ݴ���������
���߽�Ź������������ݴ�����
������Ź�����ɢ�����������ݴ�����
���Ľ�Ź�����Ӱ��ṹ��
�ڶ����Թ��ܴŹ�����߰�������̬fMRIר���
������Ź���ASL������������ǣ����ݴ�����
˼Ӱ���ݴ���ҵ��һ�����ܴŹ���fMRI�����ݴ���
˼Ӱ���ݴ���ҵ������ṹ�Ź������(sMRI)
˼Ӱ���ݴ���ҵ������ASL���ݴ���
˼Ӱ���ݴ���ҵ���ģ�EEG/ERP���ݴ���
��Ƹ���棺��Ӱ�����ݴ�������ʦ