摘要:认知症状在帕金森病患者中很常见。对患者认知状况的界定是找出认知恶化预测因子的重要步骤。Nacim Betrouni等人在Movement Disorders杂志发文,该研究旨在利用对静息态定量EEG(quantitative EEG)数据的数据挖掘技术,来发现能够识别帕金森病不同程度认知损害的最佳EEG特征组合(尤其是“认知下降风险”人群,包括可进展为痴呆的MCI患者)。提出了一种基于静息态定量EEG的可以作为筛查方法来确定帕金森病患者认知障碍的严重程度的经济易用的特征模型。
关键词:认知障碍;定量EEG;机器学习;特征模型
材料和方法
临床样本
病人来自欧洲的两个运动障碍中心,所有病人除了PD无任何其他神经疾病,剔除大于80岁的,根据临床痴呆评定量表的测验得分做聚类分析,有5个组:
G1=认知完好患者(25.64%);
G2=认知功能完整,轻度智力减退患者(26.92%);
G3=轻度认知障碍,尤其是执行功能障碍(37.18%);
G4=所有认知领域,尤其是执行功能严重缺陷的患者(3.20%);
G5=所有认知领域都有严重缺陷的患者,尤其是在工作记忆和言语情景记忆的回忆方面(7.05%)。156个病人中有118人参与了EEG记录,人口学信息在表1。
表1患者的人口学和临床特点,根据认知障碍的严重程度而定。

QEEG数据:在病人服用抗帕金森药之后,采用122导采集静息态脑电10分钟,0.1-100HZ带通滤波,512HZ采样率,使用BP分析软件,平均参考,去掉眼动伪迹和其他噪音,分段4s。功率谱分析采用fft,分析频带是delta(2-4 Hz),theta(4-8Hz),alpha1(8-10.5Hz),alpha2(10.5-13Hz),beta1(13-20Hz),beta2(20-30Hz)。计算绝对功率和相对功率(每个频带相对于整个频带[2-30HZ]的比率)。122个电极分为5个兴趣区(ROI:frontal,central, parietal, occipital和temporal),每个ROI内,要分析的电极有两种密度:高(12-20个电极/ROI,对应于10-5系统)和低(2-5个电极、ROI,对应于10-20系统)。对每个ROI和每种密度计算平均的绝对功率和相对功率,最后,测量P3,P4和Oz的峰值频率(某个频率的最大功率)。总之,计算6种不同配置:绝对全脑,绝对低密度,绝对高密度,相对全脑,相对低密度,相对高密度。
统计分析
特征选择:首先,分类模型构建,通过选择最具有区分性的维度来对特征数量进行降维,我们采用了Hall提出的自适应的相关特征选择方法,即选择与患者群体相关程度最高的特征,同时这些特征之间的相关性也最低。对每个配置进行Pearson相关检验,测量EEG数据与病人之间的相关性。只有显著相关的特征才被考虑。当不同的特征显示出紧密的相关性时,选择的方法是保持来自不同频带和ROIs的特征,以便对大脑中的信号变化有一个全局的表示。
分类
为了强调所选特征在区分组别上的效果,采用两种有监督分类器:支持向量机(SVM)和K最近邻(KNN)分类器。
SVM:SVM算法可以同时处理线性和非线性问题。该方法背后的主要思想是找到最优地分隔类的线(高维超平面)。SVM不是测量到所有点的距离,而是只在决策线两边的点之间寻找最大的裕度(margin)。这将是一条线,在这条线中,每一组中离最近的点的距离将是最远的。位于边缘的训练样本称为支持向量,它们也是最难分类的数据点。
SVM使用一种巧妙的技术来拟合非线性数据:核技巧(thekernel trick)。核(kernel)是一个数学结构,它可以“扭曲”数据定义的空间。该算法可以在这个扭曲的空间中找到一个线性边界,使原始空间中的边界非线性。
SVM最初是为二进制分类而设计的。为了解决本研究的多类问题,采用了一对一(one-versus-one)的方法。这种成对分解方法对所有可能的成对分类器进行评估,从而得到k(k-1)/2(本研究中k= 5)单独的二进制分类器。每个分类器根据来自两个类的数据进行训练。
该研究采用基于高斯核函数的支持向量机库,采用z-score方法对特征进行归一化作为预处理。
KNN:KNN算法是一种非线性机器学习方法。其基本思想是将一个新的数据记录与训练集中的类似记录进行比较,从而对其进行分类。相似性是使用通常的度量标准来定义的,比如相关的欧氏距离和马氏距离。
当对新记录进行预测时,算法会找到最近的已知记录并将该类分配给新记录。这将是一个1-最近邻分类器,因为只考虑最近邻。通常使用3、5或9个邻域,并选择其中最常见的类。
该算法通过Matlab分类学习工具箱实现。经过多次测试,保留了9邻域和欧氏距离作为增强性能的配置。
分类流程:支持向量机和KNN需要一定的训练步骤来优化模型的参数。由于训练集对训练模型的质量有影响,每种算法都采用k-fold交叉验证方案。该验证策略将数据集随机分成k个组,前k-1个组用于训练模型,第k个组为测试集。对于数据大小(n= 118),k设为5。全局验证方法包括重复5次5折验证,全局分类精度用均数±SD表示。
为了定义每个算法的最终分类模型,突出分类行为,该研究还进行了二次验证。研究者将118例患者分为两组,训练组100例,测试组18例。
结果
QEEG数据
图1a和图2b描述了这5组在每个频段的相对和绝对功率。随着认知能力下降的加剧,delta和theta频段的功率特别是相对功率增加,而alpha和beta频段的功率特别是相对功率降低。
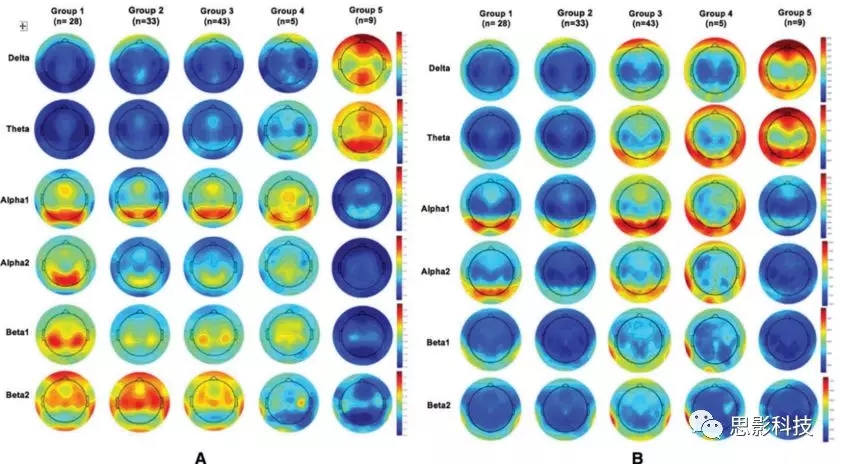
图1:每个频带平均功率得到头皮分布。(A)相对功率;(B)绝对功率。
QEEG特征和病人分组之间的关系
QEEG数据挖掘
表2揭示了病人组和EEG特征的变异分布。6种配置存在显著的交互作用。

QEEG特征与患者组的相关分析表明,峰值频率是与患者组相关程度最高的特征之一。基于完全相关得分,降维策略允许选择最优特征:保留所有构型的峰值频率。最终,theta、alpha1和beta2被保留为绝对全局配置;绝对低强度和高强度的额叶theta、颞叶theta、中央区theta和顶叶theta用于绝对低密度和绝对高密度的配置。
相对功率方面,delta、alpha2和beta1被保留为全局功率,而前额、颞部、中部和顶叶区域的theta和beta1频率作为低密度和高密度的配置。
因此,分类模型的构建结合了人口学数据和EEG特征。在使用5-折交叉验证进行训练和验证之后,两种算法的最好的分类正确率是使用相对、低密度电极,分别是SVM86%±3.5,87%±2.8。
二次验证包括对100例患者数据的模型训练和对其余18例患者的预测,结果分组见表3。结果报告了6种考虑的配置。图2为利用KNN算法得到的相对功率、低电极密度配置下特征的混淆矩阵。
表3为二次验证各配置下两种分类器的分类准确率

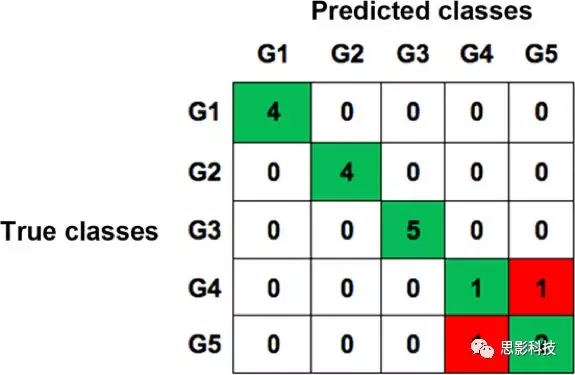
图2.利用KNN算法得到的相对功率、低电极密度配置下特征的混淆矩阵
结论:本研究的目的是探索结合静息态脑电与数据挖掘技术来建立分类模型,这些结果表明,从日常临床实践探索模式可以计算EEG特征,可以方便的作为筛选方法,以确定帕金森病患者的认知损害的严重程度。
原文:Electroencephalography-BasedMachine Learning for Cognitive Profiling in Parkinson’sDisease: Preliminary Results.

欢迎微信扫码关注思影科技公众号
获取最新脑科学研究资讯与相关课程
获取原文:关注“思影科技”公众号,回复“原文”或“培训”,获取原文pdf及补充材料下载链接,同时欢迎浏览我们的培训通知以及数据处理业务介绍。(直接点击下文即可浏览):
第四届脑电信号数据处理提高班(南京,与十三届脑电相邻)
第一届脑电数据处理入门班 (重庆,全界面)
第十二届脑电数据处理班(重庆,与入门相邻)
第二届眼动数据处理班(重庆,与脑电相邻)
第十三届脑电数据处理班(南京,与脑电提高相邻)
更新通知:第五届近红外脑功能数据处理班 (南京)
第二届脑磁图(MEG)数据处理学习班
第十四届功能磁共振数据处理基础班(南京)
第十五届功能磁共振数据处理基础班(南京)
第七届磁共振弥散张量成像数据处理班(南京)
第五届磁共振脑影像结构班(南京)
第四届磁共振ASL(动脉自旋标记)数据处理班(南京)
第九届磁共振脑网络数据处理班
更新通知:第三届脑影像机器学习班(南京)
第四届脑影像机器学习班
第四届动物磁共振脑影像数据处理班(南京)
第十六届功能磁共振数据处理基础班(重庆)
更新通知:第二届脑影像机器学习班 (重庆)
更新通知:第三届脑功能提高班暨任务态fMRI专题班
第六届磁共振脑影像结构班(重庆)
思影数据处理业务一:功能磁共振(fMRI)
思影数据处理业务二:结构磁共振成像(sMRI)与DTI
思影数据处理业务三:ASL数据处理
思影数据处理业务四:EEG/ERP数据处理
招聘:脑影像数据处理工程师