背景:在过去的几年里,已有研究致力于探讨大脑不同区域在人类不同行为中功能相互作用的复杂性。其中,神经影像学研究提出,言语的实现需要大脑区域的协调来理解、规划和将听到的声音和口语生成结合起来。但是,这些研究在很大程度上局限于绘制单独语音元素的神经关联图,以及与语音控制不同成分相关的皮层或皮层下通路(即白质纤维连接)。目前,有关控制言语和语言的脑网络机制仍不清楚。
方法:对健康受试者的功能磁共振(fMRI)数据进行图论分析(即脑网络),通过构建从静止状态到无意义音节的运动输出,再到真实语音的复杂生成的层次递增的功能性脑网络,并与非语音相关的顺序手指敲击和纯音辨别网络进行比较,量化了大尺度言语(speech,从语言学角度看属于言语层面,可以直接理解为讲话)拓扑网络。
结论:研究人员在初级感觉运动区(primary sensorimotor)和顶叶区确定了一个高度连接的局部模块,其形成了一个共享的跨检测条件的核心枢纽网络,其中左侧脑区4p在言语网络组织中起着重要作用。这些感觉运动中枢表现出灵活枢纽的特点,它们能够跨不同网络,并参与到多个功能区域,并能够根据任务内容自适应地切换远程功能连接,从而促使每个被检查的网络具有不同的网络结构。具体而言,与其他任务相比,言语产生的特征是形成了6个不同的神经网络,它们对前额皮质、脑岛、壳核和丘脑进行了特定激活,共同形成了言语功能连接体。此外,该研究中观察到的初级感觉运动区对不同任务的处理能力挑战了以往研究中该区域单一性的既定概念。
注:文章开始前有一个语言学背景的知识需要大家了解,即言语和语言(对应文中的speech和language),语言学认为在人类的大脑中存在语言系统,这个系统由词库(即大脑词典)和句法生成系统组成,它是一个相对独立的系统,拥有你讲话所需要的语言功能。我们平时所说出来的话被称作言语,它是你根据环境、对象等等条件产出的特定的对象,并不是语言,因此言语产生的网络与语言网络是不同的,言语产生还需要协调口面部肌肉运动,胸腔、肺部等区域共同作用。
关键字:听觉辨别网络 ,fMRI,静息态网络,言语产出网络,音节产出网络
1.背景:
在过去的二十年里,大量的神经成像研究确立了这样一个观点:言语和语言需要在几个大脑区域之间进行协调,以便理解、规划和将听到的声音与口语结合起来。然而,对言语和语言的大脑控制网络的研究在很大程度上局限于对语言控制成分相关的不同皮层和皮层下通路的研究,这些研究关注的方面包括语言运动输出、语言流畅性、语音和语义处理、语言和音调工作记忆、语音监控和辨别、神经同步和整合等。但这些研究都局限在言语产生的子系统上,对于自然谈话状态下的言语网络我们仍不清楚。
因此,我们对控制言语和语言的脑网络机制的复杂性的理解是非常有限的。其中一个特别重要的问题则涉及到言语网络中塑造口语生产的大脑区域的大尺度建构、交互和功能专门化。
针对以上问题,研究人员对健康成人在静息状态下、产生无意义的音节状态下(这是一项与说话有关的运动任务,但其语言意义很小)及生成语法正确、有意义的真实生活英语句子状态下(通过任务的提升以考察不断增长的层次结构的功能网络,并量化言语生成网络形成的中间步骤)的功能磁共振(fMRI)数据进行了图论分析。为了进一步阐述言语网络的特点和基于连接的体系结构,研究人员进行了一项跟踪研究,以调查所有检查条件下节点网络的形成,并与非语言任务(例如纯音的听觉辨别)执行过程中的功能网络的模块结构以及简单的非语言的运动任务(如手指连续轻敲)进行比较。
在实验一中,研究人员假设言语产生网络(SPN)与静止状态(RSN)和音节产生网络(SylPN)相比,会在以感觉运动皮层为中心的紧密相连的局部网络中表现出增强的功能分离,重要的是,这些感觉运动中枢在言语产生(SPN)过程中的功能专门化将确保对多模态整合皮层区域的独特激活,如对前额叶皮质和顶叶下部皮质的激活。
在实验二中,研究人员假设不同条件下的功能网络(即、静息状态、音节产生、言语产生、手指敲击和听觉辨别)将以一种独特的连接结构为特征,特异于处理连接的出现和细化的SPN的模块化体系结构的出现,其能反映言语产生网络配置的复杂性。
2. 被试和方法:
2.1 被试
研究人员招募了27名没有任何神经、精神或喉部疾病史的右利手英语单语者(女性18名,平均年龄52.2岁,SD=11.3)。其中,20名被试(13名女性,平均年龄55.2岁,SD=9.8)参与了初始的静息态数据扫描和言语产生任务数据扫描,后续的实验有14名被试参与(7名女性,平均年龄52.0岁,SD=13.1,其中有9名被试为新被试,未参与之前的静息态和言语产出任务扫描)。为了确保后续分析时,前后数据不会有组间差异(因为被试有所不同),研究人员对两组研究对象的原始和后续研究中所有节点区域的时间序列进行了比较,发现两组之间没有统计学上的显著差异(FWE矫正后,p > 0.07)。
2.2 方法
数据采集:
在一台3T的GE机器上进行采集,包括静息态数据、任务态数据和结构像数据。
静息态数据:
静息态数据采集在任务态实验开始之前,EPI序列,TR为2s,共采集了150张全脑静息态功能数据,翻转角度90度,TE30ms,层数为33层,平面分辨率为3.75*3.75。被试被要求在没有特定想法的情况下休息,在光线昏暗的环境中闭上眼睛。同时记录了被试的生理信息,包括呼吸和心率。
任务态数据:
任务态的数据采集为EPI加权序列,在不同的任务中使用了不同的TR。在音节产生和句子产生任务中使用了10.6s的长TR,其中8.6s为任务执行,2s为数据采集。在听觉辨别任务总使用了8.9s的长TR,其中6.9s为任务执行,2s为数据采集。TE 30ms,翻转角度90度,层数36层,平面分辨率为3.75*3.75。所有的样本刺激都以声学的方式呈现。在每个被试的5次扫描过程中,每项任务共进行了36次试验,并以24次静息注视作为基线,这些任务在扫描session和被试之间进行了伪随机。
音节产出任务:
被试被要求产出四个重复的音节/iʔi/,其中/i/的发音与‘green’和‘beer’中的元音发音一致,中间为一个声门闭/ʔ/音符,其后再跟一个与首音相同的/i/。选择这个音节的主要目的在于达到发声所必需的最大的声带内收,在产出这个音节时,对于英语单语者来说在很大程度上是没有任何意义的。
句子输出任务:
被试需要根据指示共输出十个意义不同的句子,例如“We are always away”、“Tom is in the army ”这样的句子,每次输出一个句子。不同的句子被用来发掘正常说话中存在的不同音系和词汇成分,同时以此在整个扫描过程中尽量减少重复一个句子后的工作记忆累积。音节产出任务中,被试需将大脑活动“集中”在与语音产生相关的简单声音运动控制上。而在句子产出中,音节变化和语义变化则是不受限的。这有利于使用音节产生来缩小语音运动输出,同时在不同句子的产生过程中达到扩展高阶处理的目标。
听觉辨别任务:
听觉辨别任务包括三对950赫兹和400毫秒的低纯音,它们要么同时出现,两个音调之间没有间隔,要么从第一个刺激开始,间隔时间为440毫秒,或者间隔时间较短,平均为39毫秒。所有的音调都是在14440 Hz采样频率下产生的,受试者每次听一组刺激,然后判断两组音调是否相同。
手指轻敲任务:
EPI采集序列,TR2s,TE30ms,翻转角度90度,36层,平面分辨率3.75*3.75.采用block设计,被试被一张手的图片直观地提示,按顺序敲击手指,使用右手敲击(被试都为右利手)。所有被试都进行了30秒的手指敲击,然后休息30秒,在此期间,被试盯着眼前屏幕上的一个十字。研究对象共进行了5组手指连续敲击和5组静止固定。
结构像采集:T1加权,层数128层,1.2mm层厚,TE30ms,翻转角度10
数据处理:数据预处理使用AFNI软件包。
静息态数据预处理前,先删除每个被试的前四张图像,进行时间矫正后,将功能数据与被试自己的高清结构数据对齐。基于解剖相关校正(ANATICOR)模型对时间序列中硬件相关噪声进行回归;采用回顾性图像校正(RETROICOR)模型对生理噪声进行回归。为了避免伪负相关值和负相关网络的产生,对rs-fMRI数据不进行全局信号的回归。将在灰质内的残差时间序列用6mm高斯核进行空间平滑,并配准到Talairach-Tournoux的标准AFNI空间。
任务态数据预处理前先删除前两张图像,然后将所有的EPI数据使用AFNI中的heptic多项式插值(heptic polynomial
interpolation)的方法配准到扫描时最接近高解剖分辨率的图像上,然后进行了平滑核为6mm的高斯平滑。将其归一化为信号变化百分比,然后配准至Talairach-Tournoux的标准AFNI空间。用多元线性回归分析与任务相关的反应模型,每个任务与一个典型的血流动力学响应函数卷积,每个回归函数有一个单一的回归因子。
网络构建:
研究人员基于细胞结构最大概率图(the cytoarchitec
tonicmaximum probability maps)和macrolabel atlas ,共确定了212个ROI(感兴趣区)。包括142个皮质区、36个皮质下区和34个小脑区(见图一)。
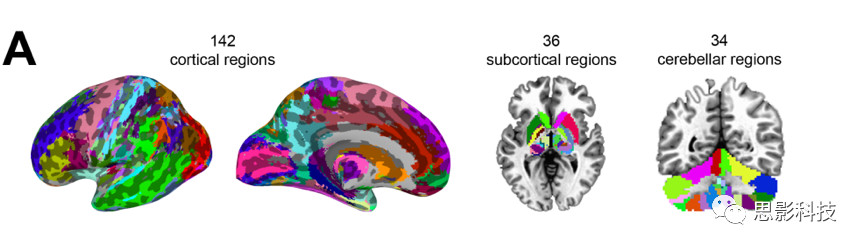
图1 脑网络构建的种子点图
对于每个ROI,计算了rs-fMRI和任务fMRI的体素平均时间序列。然后根据pearson相关得到每个人的212*212的连接矩阵。在图像检查过程中,有6名被试静息态数据异常被排除。同时为了减少数据不一致带来的影响,他们的任务态数据也被相应的删除了,这样每个条件下的被试为14人。每个网络的密度(即我们平时所说的稀疏度)计算为实际连接数除以图中可能的最大连接数,其中RSN的平均密度为88%± 4%(平均值±SD), SPN为92% ± 6%(平均值±SD),SylPN为92% ±5%(平均值±SD)。由于密度> 50%的网络往往表现出随机网络特性,研究人员通过去除权重小于网络中最大权重的给定百分比的边来降低网络的密度,直到网络的密度为50%。因为该研究的主要目标是通过比较RSN、SylPN与SPN的差异来研究SPN。因此,作者者首先将这种阈值化应用于SPN,然后相应地调整RSN和SylPN,使所有的网络图具有相同数量的节点和边,以便用于网络间的比较。
在应用了14个SPN的节点消除策略后,62个区域从最初的脑网络分析中移除,留下150个脑区域供进一步分析。重新计算矩阵并对其进行阈值处理,得到一个共同的密度范围为77% -86%(共取了10个值,1%的增量)。在此范围内,计算了组平均网络的密度范围为60%-78%(10个值,增加2%)。在接下来的听觉辨别任务的网络构建中,作者使用了相同的方法,来保证数据分析的一致性。
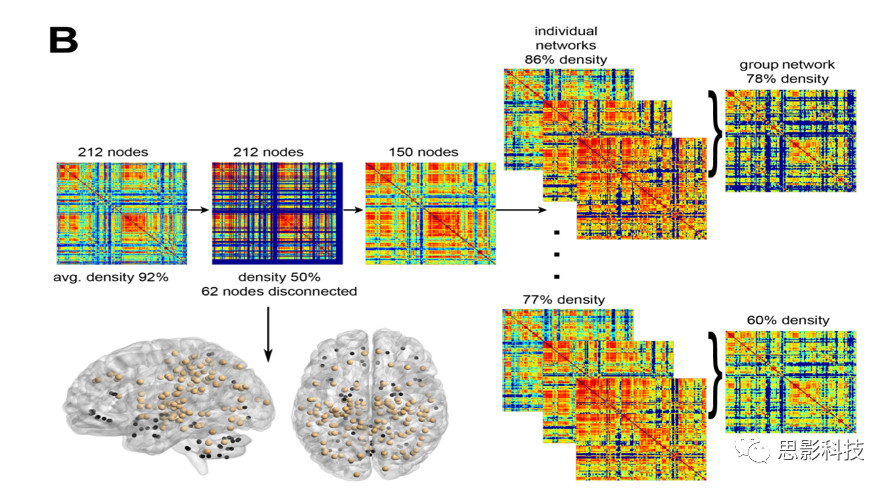
图2 网络构建流程图
图论分析:
研究人员使用the Brain Connectivity Toolbox一共对四种图论指标进行了分析,分别是度值、强度、聚类系数和效率。测试SPN和RSN之间的不同图论指标的统计意义,以检查网络拓扑结构从静止状态到言语产生的变化,以及SPN和SylPN之间的变化。这样的做法可以将说话作为一种复杂的行为和音节产生作为说话的一个孤立的运动元素进行量化。研究人员使用了两样本配对的非参检验的方法(permutation test)进行了网络间的比较,并对结果进行了FWE矫正(p=0.05)。为了测量单个节点vi的功能影响,作者计算节点度ki(即连接到节点vi的边数)及加权网络的节点强度si(即连接到节点vi的链路权值之和)。度和强度均归一化到[0 1]范围。
已知局部分离网络包含用于特定任务处理的不同单元,因此尝试通过局部分离网络的分析来量化某一网络对专门处理的偏好。作为用来估计RSN、SPN和SylPN分离的第一个近似值,研究人员计算了节点v的局部聚类系数ci,然后将局部聚类系数与100个随机拓扑的零假设网络进行比较。然后第二步,研究人员分析了网络中枢纽节点(hub)的形成。枢纽节点的定义为如果某个节点的ki至少比前面计算出的平均节点度大一个标准差,则为枢纽。同样的逻辑,研究人员还根据节点强度计算了枢纽节点的形成。
作者还计算了网络的全局效率Eglob ,并利用随机网络的100个对应值对全局效率进行归一化。同时还计算了网络的小世界属性,得到小世界属性值σ。
同时,为了评估跨条件网络重构的程度,作者将ADN(听觉辨别任务)和FTN(手指轻敲任务)作为控制任务估计了RSN、SPN和SylPN的最优模块分解。利用前文所述的方法,将ADN网络和FTN网络的节点降为150个。最优模块分解通过最大化组内边的数量,同时最小化组间链接的数量,将网络划分为多个连接群。
结果:
1.所有的脑网络都表现出小世界属性,它们各自的小世界指数都大于已知连接密度、60% - 78%范围内的一个。SPN(所有 σ> 1.5)和SylPN(所有 σ> 1.7)的小世界属性比RSN(所有σ> 1.01)高。
2.与随机网络相比,所有真实网络均具有较高的聚类系数(SPN 0.50;SylPN 0.56;RSN为0.33,随机网络为0.32)和全局效率(归一化的Eglob = 0.9998 SPN,
0.9899SylPN, 0.9992 RSN)。见图s1。
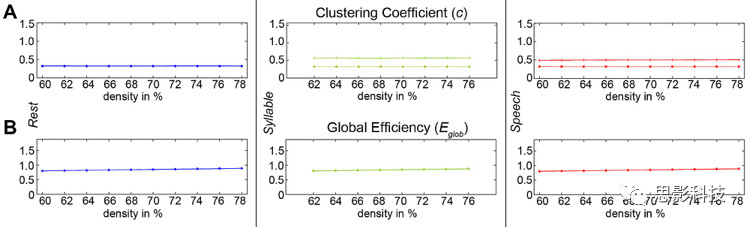
图 s1 不同脑网络的拓扑稳定性
3.通过计算RSN、SyIPN和SPN的节点度和节点强度(图3、图4、图5),发现这些网络具有较强的拓扑稳定性。
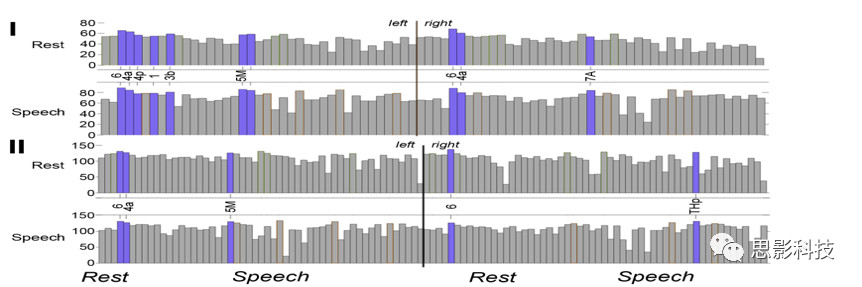
图3 RSN和SPN网络前30%共享节点的节点强度和节点度值图
注:图中I为节点强度,紫色标出的节点在两个网络中都是节点强度的枢纽节点(strength hubs )。图中II为节点度,紫色标出的节点在两个网络中都是节点度的枢纽节点(degree hubs )。图中的X轴上的数字和字母表示是作者定义的网络节点名称,有对应的label表可以查到是哪个脑区。
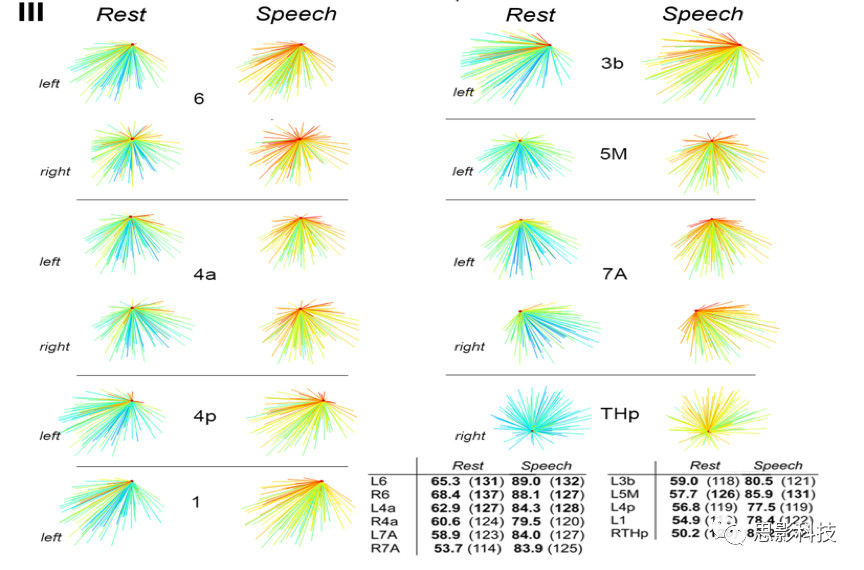
图4 节点强度枢纽节点和节点度枢纽节点不同网络中具体表现图
注释:图4中通过颜色变化来反映节点强度,通过线条数量来表示节点度,可以直接看图中右下角的表。可以看出,SPN网络相比于RSN网络在节点强度上有较大变化,但在节点度上则表现相对稳定。这说明了两个网络具有相对稳定的拓扑结构。
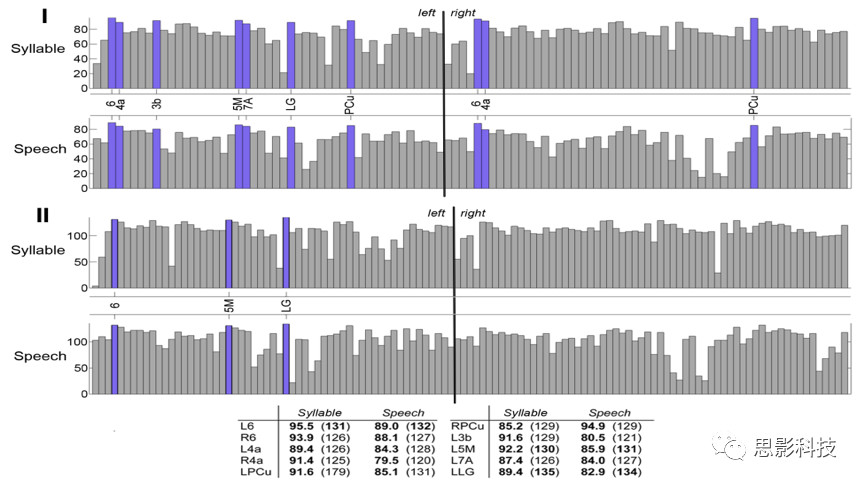
图5 SPN网络和SylPN 网络节点强度及节点度前30%节点数据图
注:与图三中一致,I代表节点强度,II代表节点度,紫色柱代表各自的枢纽节点。从下面的表格中,可以看出,两个网络在共享节点上的节点强度和节点度差异不大。
4.SPN和RSN两个网络共享10个高强度中枢节点和5个度中枢节点,包括运动前皮层(双侧6区)、初级运动皮层(双侧4a区和左侧4p区)、初级躯体感觉皮层(左侧3b区和1区)和顶叶皮层(双侧7A区和左侧5M区)。这些枢纽节点中除了双边4a区,其余节点在SPN的节点强度都显著强于RSN(p<0.049,矫正后)。
5.SylPN和SPN共享10个高强度中枢节点和3个度中枢节点。分别位于运动前区(双侧第6区)、初级运动区(双侧第4a区)、初级躯体感觉区(左侧第3b区)和顶叶皮质(左侧第5M区和7A区)、左侧舌回和双侧楔前叶。
6. SPN和RSN和SyIPN相比,有独特节点。图6与图7直观的展示了SPN与RSN和SyIPN网络相比后,共享节点和各自独特节点的情况。
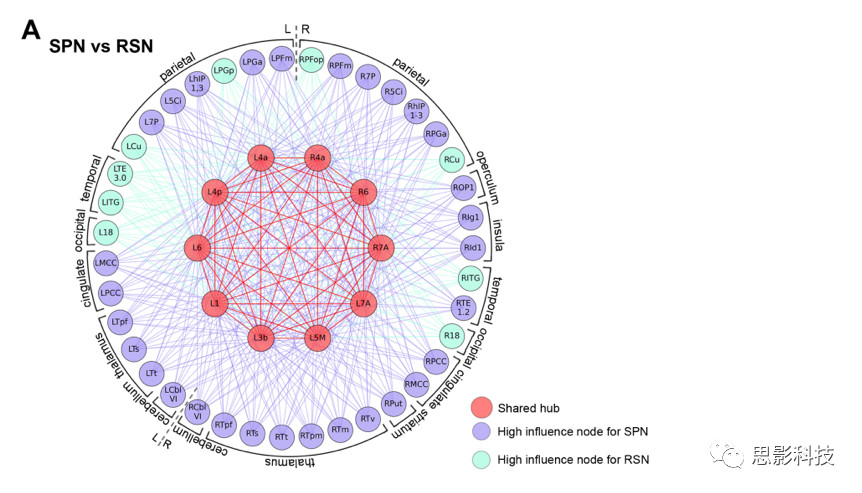
图6 SPN与RSN共享节点及独特节点
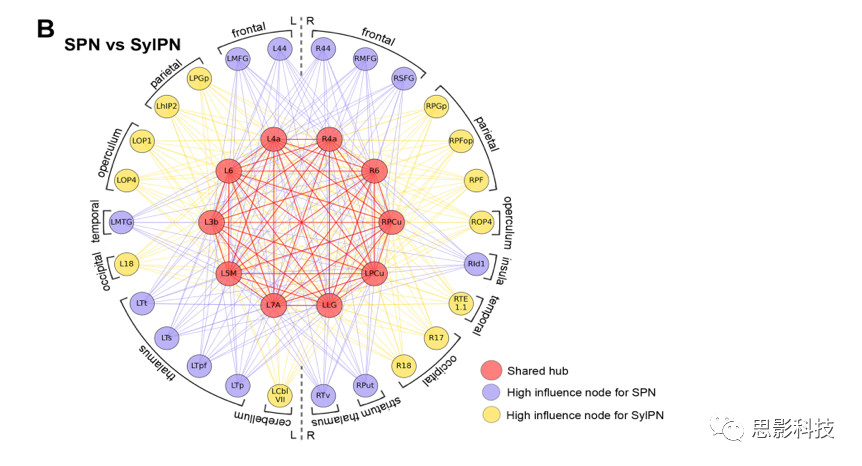
图7 SPN和SyIPN共享节点及独特节点
7.以模块结构为基础的功能网络分析结果表明,不同任务显著的改变了RSN网络的模块配置(图8)。
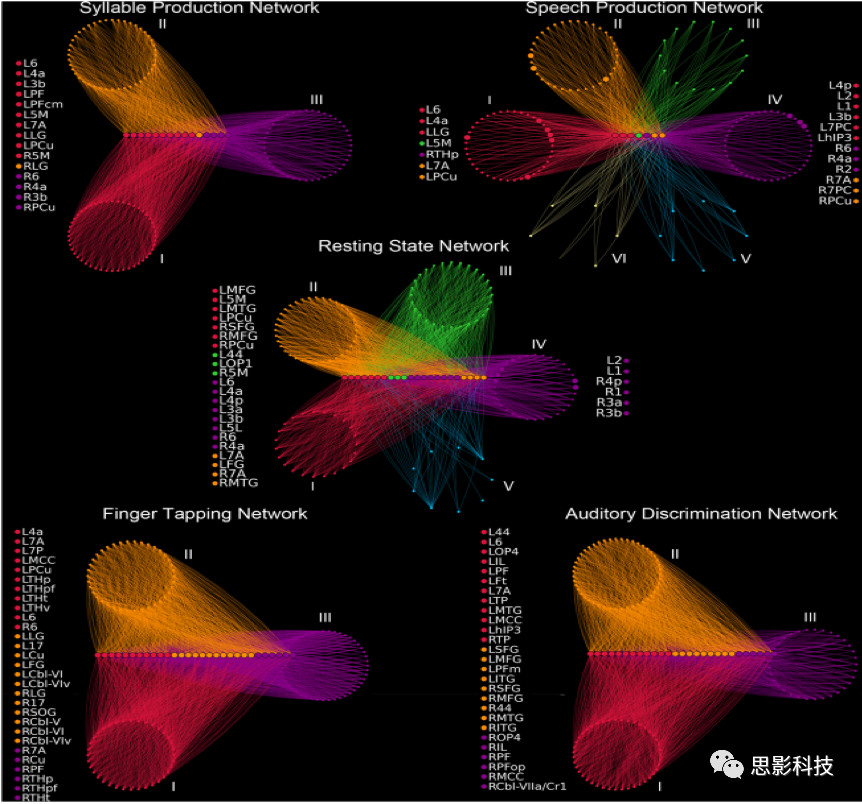
图8 不同任务下功能网络的模块特性
8.结合网络模块层面的功能交互分析和对单个节点的评估,本次研究提供了详细的定量证据,表明言语生成需要围绕以感觉运动皮层为中心的核心模块进行专门的网络组织。在言语控制网络中,初级运动皮层的4p区是一个非常重要的中枢,同时感觉运动皮层在不同网络中表现出的高度功能性表明,这一区域在不同网络中进行了不同的功能专门化。
9.语言的产生依赖于一个大尺度脑网络的协调,这个网络由前额皮质、脑岛、壳核和丘脑的特殊皮质和皮质下节点组成,而这些节点对其他网络(包括音节产生网络)则没那么重要。
一句话总结:
感觉运动区域组成的特殊网络,在所有条件下形成一个共同的处理核心,而言语控制网络还需要特异模块的协调工作,它们由前额皮质、脑岛、壳核和丘脑等区域共同组成六个不同的模块来构成言语功能连接结构。
原文:
The functional
connectome of speech control
S Fuertinger, B Horwitz, K Simonyan -
PLoS biology, 2015 - journals.plos.org
如需原文及补充材料,请关注思影科技公众号后直接发信息给我们

欢迎微信扫码关注思影科技
您的支持与转发是思影前进的动力之源
欢迎浏览思影的其他课程以及数据处理业务介绍。(请直接点击下文文字即可浏览,欢迎报名与咨询):
第九届磁共振脑网络数据处理班(南京)
第十届磁共振脑网络数据处理班(南京)
第五届脑影像机器学习班(重庆)
第十八届功能磁共振数据处理基础班(重庆)
第八届磁共振弥散张量成像数据处理班(重庆)
第十七届功能磁共振数据处理基础班(南京)
第四届任务态fMRI专题班(南京)
第六届脑影像机器学习班(南京)
第十九届功能磁共振数据处理基础班
第七届磁共振脑影像结构班
第五届磁共振ASL(动脉自旋标记)数据处理班
第四届动物磁共振脑影像数据处理班(南京)
第二届脑电数据处理入门班(南京)
第十四届脑电数据处理班(与入门相邻)
第三届脑电数据处理入门班(重庆)
更新通知:第三届眼动数据处理班
第二届脑磁图(MEG)数据处理学习班(南京)
第六届近红外脑功能数据处理班(上海)
思影数据处理业务一:功能磁共振(fMRI)
思影数据处理业务二:结构磁共振成像(sMRI)与DTI
思影数据处理业务三:ASL数据处理
思影数据处理业务四:EEG/ERP数据处理
思影数据处理服务五:近红外脑功能数据处理
招聘:脑影像数据处理工程师(重庆)