
图文无关,主要与上一篇的84版笑傲江湖相辉映,如果你认为我只是个搞技术了,没有情怀,那就是big mistake。我觉得我是个艺术家。
上回书说道必须要根据你选择攻城还是突袭来选择合适的兵种。(啊,不好意思串台了,链接直接点这里大话脑影像之二十:Block 还是Event?上),是在实验设计阶段就根据后期的统计方法和分析目的来进行充分考虑从而设计出决胜千里的实验方案。那么我们先看一下任务态数据统计中需要面对的问题和常用的分析方法。
首先是任务态数据的统计建模。也就是我们常说的一阶建模,这里的建模原理同样请大家回去看我们的大话脑成像之19:GLM(链接直接点这里: 大话脑影像之十九:GLM(上),拿走拿走别客气,客气就点击分享朋友圈吧,我分享了,你随意)。我们主要说统计检验,这里以SPM的建模为例(别的脑影像统计工具包也一样,都是基于一般线性模型)。以下是图解:
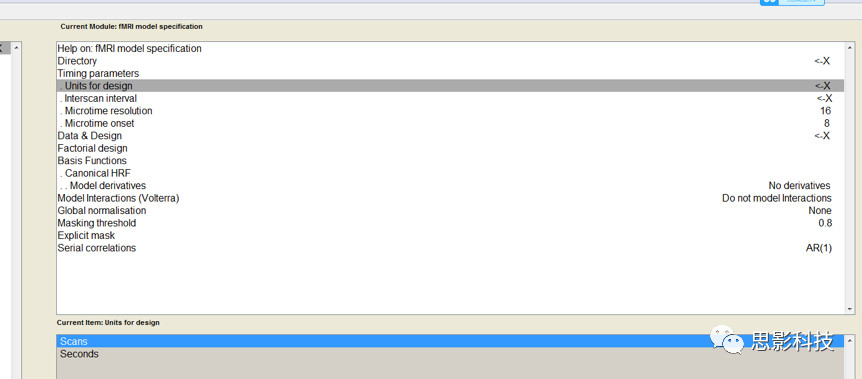
在SPM的first-level建模中,有一个体现SPM优势的地方。在Units for design这个选项下,有两个选择:Scans和Seconds。这里并不是用来选择你用的是Block设计还是Event设计实验的,而是让你选择使用何种单位来进行刺激序列的线性建模的,即我们常说的onset。
选择Scans则onset单位为扫描帧数,即你扫的第多少个全脑功能图像(其实就是多少个时间点),选择Seconds则onset单位为时间单位,即你的刺激呈现时具体的时间点。他们有什么不同呢?这里就和任务设计有关系了。因为扫描张数的单位的是整数,所以如果你的刺激出现在无法被TR整除的时间点上,你就无法使用Scans的处理方式了。
因此,在以前的江湖里流传着这样一个陈规,fMRI设计的任务时间点要能够被TR整除。这种方式在早期的Block设计中是比较容易做到的,但是Event实际中刺激间隔的随机化是很难适应这一点的。所以,如果你希望用scans为单位处理的方式来统计检验,那么Event设计可能就要离你而去了。那是big mistake!(分手,在你口中那么随意的吗?Event你个渣男!)
Scans的方式如此契合于Block,因此其统计结果相对来说也更具有detection power。虽然一些人固执地认为这是由于scans的统计方式带来的,但其实这两种对onset进行单位规定的方法并没有后续的统计模型上的差异,相反seconds作为单位更加准确,同时假如你的任务是需要区别正确错误反应的,block和scans的契合反而让你将正确反应的效应和错误反应的效应混合了起来。因此,越来越多的人投入了seconds的怀抱。所以,从这个角度讲,如果你就是要用scans的单位来统计检验,建议你用Block设计。
其次,是二阶分析。我们知道二阶分析是组层面的,在组层面的分析我们面临着使用T检验还是F检验的问题。这就要谈到实验设计时的变量控制方式了。你是因素设计还是参数设计,变量有几个,同一个变量有几个水平等等。这些内容其实并不直接影响实验范式的选择,即你是选择Block还是Event。所以这个步骤大可放心。
好了,现在个体建模建好了,组分析也得到结果了,万事大吉了吗?当然没有,年轻人毕竟还是土洋!你老师嫌弃结果解释太粗放,没有进一步的分析结果。这个时候你就面临着更加复杂的分析方法。在任务态fMRI数据处理中,我们经常用到的是PPI(心理生理交互模型)还有有向脑网络连接的DCM(动态因果模型)。
一图不扫何以得天下。下面的这张PPI建模图,我看你骨骼惊奇,是万里无一的脑功能数据处理奇才,你如果帮我转发这篇奇文,我就免费送你了,就当交个朋友,我们看到的第一行就是心理生理交互效应。
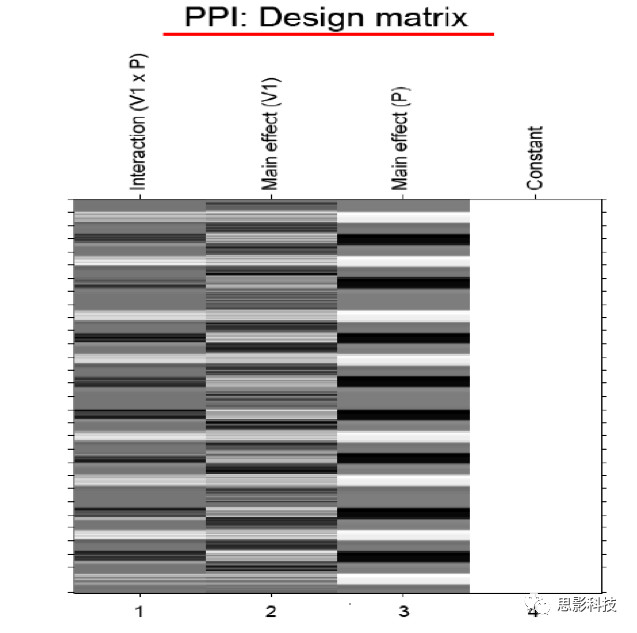
PPI分析的目的有两种,第一种是分析某个特定脑区对另一脑区的影响(通过时间序列相关来计算)是如何通过实验条件或者任务来改变的;第二种是一个特定脑区对一个实验环境的反馈是如何靠来自另一脑区的输入来进行调节的(下面的图生动形象,请忽略数学公式和英语)。它处于FC分析和有向网络的中间地带,往往受到任务态数据分析的青睐(如果你不懂PPI,请直接辍文末,来,少年点这个链接:更新通知:第四届任务态fMRI专题班,任务态数据处理哪家强,中国南京找老杨)。
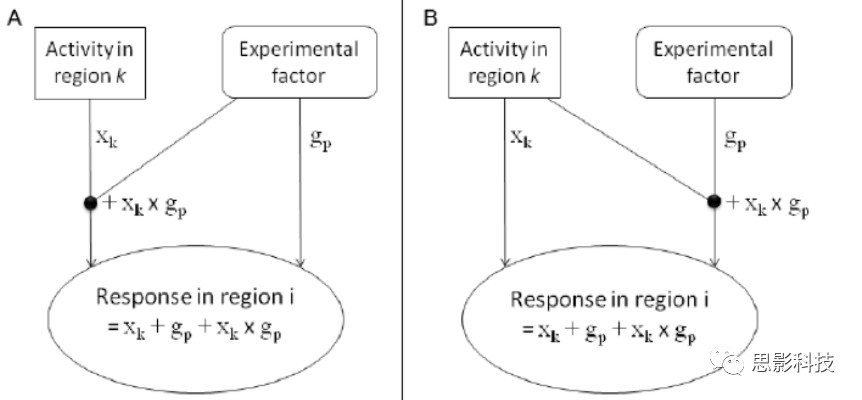
这里我们主要考虑PPI分析对任务设计的要求。在PPI分析中,要求对一个脑区的时间序列进行提取,而提取的这个时间序列中需要包含类型刺激的连续序列信息。我们往往受到被试做任务的影响,会把总刺激量分不同的session(或者run)呈现给被试,这就导致了我们收集到的任务态fMRI的数据并不是连续的。我们往往在一阶建模的时候通过session的设置来完成这一步骤。
但是,PPI的建模需要我们尽可能的将所有刺激连续,这样能够取得我们关注的区域在所有刺激下连续的时间序列变化。因此,这样的实验操作手段就带来了后续处理中要不要把所有图像放在一起进行建模,时间onset计算、头动文件连续等等后续问题。这个问题在SPM的mannual中被同样的提到了。那么能不能有效地避免这种问题呢?这就是实验范式的选择问题了。
将同质性的任务放在一个session(或者run)中呈现给被试能够有效解决PPI分析中面对的这个问题。虽然后续通过把图片放在一起可以处理上面提到的问题,但我相信你的老师肯定告诉过你,多加几块海绵(俗称物理降噪)比你用头动参数回归来控制人为噪声影响要有效的多。在这里也是同样的道理,将同质性的任务放在一个session就可以有效的提取一个任务在某一特定脑区的时间序列。那么如何做到呢?我们仔细思考一下就会发现,Block设计更容易做到这一点。一般我们的一段任务时长在6-10分钟(10分钟都太久了,得心疼被试啊,不然鸽你一次,你的机时费就打水漂了),因此在时间总量一定的情况下,刺激种类越少,呈现的刺激数量就越大。从统计效力讲,我们必须保证有效刺激数量,因此,减少刺激种类就成为了我们的选择。刺激种类少,你想到了什么呢?对,这回你没想错,就是Block设计范式。
接着是更高级的有向网络连接――DCM(动态因果模型)。在任务态fMRI中,我们使用的基本是确定性DCM模型,即在较为明晰的先验假设下,假设几个脑区在受不同任务输入或者调节时会表现出不同的连接模式或者特性。研究者往往要先根据先验假设来选择种子点(或者说感兴趣区即ROI),然后定义一组备选的连接模型。再通过贝叶斯方法(高大上)来进行模型选择,这些内容是不是让你有些吃不消了?那我们直接插入正题,假如想做后续的DCM分析,实验设计要注意什么呢?
这张DCM模型的结果图也免费送了,你想做吗?还是思影科技找老杨
其实这是和你的理论能力直接相关的,为了能够更好的进行模型的建立,需要你对想要关注的问题有较为明确的脑区响应和能够确切引起响应的任务类型设计。为了能够提升模型的准确性,目标脑区的功能越明晰越好,这样才可以更好的以特定的任务来引起该脑区的任务响应。而这样的描述你是不是想起来什么?没错,那就是从理论上来说,Block设计往往用来进行功能定位。
为了能够更好的研究不同脑区之间的网络关系,DCM建模中不同种子点之间的功能差异越大、种子点内部的功能一致性越高,建模结果就越准确。同时也更好判断任务输入脑区或者位于任务在网络调节关系中的位置。需要实验设计中任务类型差异较为明显,能够更好的引起相应脑区的响应。这些要求在Block设计中更容易得到实现,Event设计和混合设计则在统计效力上在一定程度上受到范式局限性的影响。但是这并不代表不能,我们讨论的是如何更好的问题!
现在是不是看到经典的力量了呢,所以说老东西还是好用的。Block这种最早出现的fMRI设计范式在今天仍旧拥有着很强的生命力是有它的独到之处的!好了,今天就到这里啦,什么,你说还有脑网络呢?任务态数据驱动的脑网络构建不同学者有不同的看法,争议较大,就像你问我,我和吴彦祖谁比较帅这个问题,报纸和杂志上目前争议很大,没有定论,所以这个问题我们也不知道啥时候能讲,你关注思影科技,说不定哪天我们就讲了,这年头求关注好费心啊。还是直接发广告吧:(直接点击下文文字,啥都有):
更新通知:第四届任务态fMRI专题班(南京)
第十九届功能磁共振数据处理基础班(入门必备)
第十届磁共振脑网络数据处理班(高手必备)
第六届脑影像机器学习班(高大上)
第五届磁共振ASL(动脉自旋标记)数据处理班(新序列)
第七届磁共振脑影像结构班(硬功夫)
第八届磁共振弥散张量成像数据处理班(tra起来!)
第十八届功能磁共振数据处理基础班(重庆)
第二十届功能磁共振数据处理基础班
第三届脑电数据处理入门班(重庆,与15届脑电相邻)
第十五届脑电数据处理班(重庆)
第四届脑电数据处理入门班(南京)
第二届脑电数据处理入门班(南京)
第十四届脑电数据处理班(与第二届脑电入门相邻)
第五届脑电信号数据处理提高班(南京)
第二届脑磁图(MEG)数据处理学习班(南京)
第六届近红外脑功能数据处理班(上海)
更新通知:第三届眼动数据处理班(南京)
第四届眼动数据处理(南京)
思影数据处理业务一:功能磁共振(fMRI)
思影数据处理业务二:结构磁共振成像(sMRI)与DTI
思影数据处理业务三:ASL数据处理
思影数据处理业务四:EEG/ERP数据处理
思影数据处理服务五:近红外脑功能数据处理
招聘:脑影像数据处理工程师(重庆)

文末公众号二维码的小logo一贴,完美!