
提笔写下浅谈影像组学几个字,我略微有点忐忑以及不安,史诗般的宏大题目,怕自己HOLD不住,但在这个满世界人工智能的时代,不做点严肃文学科普工作,不是我的风格,毕竟,我下楼吃碗面,老板都跟我说,根据他潜心研究搭建的“基于环境、气候、人群活动等指标的无监督多参数自我学习本店客流量预测模型”显示的结果,我今天会成为他第123个客户,我略带深沉的问他“那你的模型预测准确度有多少?”,老板谦虚的说道“我的模型一直在自我进化,目前大概徘徊在50.9%”,我说兄弟,是时代埋没了你,你应该去BAT做高级算法工程师或者去买彩票,面馆老板虽然嘴上没说,但我知道他心里一定一阵窃喜,因为今天他给我的牛肉面里多放了半块牛肉。
影像组学的概念最早由荷兰学者范尼斯特鲁伊(我瞎说的,荷兰人中我大概只认识他,因为我从小就喜欢看他打篮球,还有个伊布)在2012年提出,其强调的深层次含义是指从影像(CT、MRI、PET等)中高通量地提取大量影像信息,实现肿瘤分割、特征提取与模型建立,凭借对海量影像数据信息进行更深层次的挖掘、预测和分析来辅助医师做出最准确的诊断。
So,从概念可以知道最基本的信息:
1)影像组学的基础是影像数据;
2)影像组学是针对肿瘤的;
3)影像组学研究依靠大量潜在影像信息;
4)影像组学研究绝大部分包含统计方面的数据挖掘工作;
5)辅助临床医师进行诊断。
针对以上几个信息点,也就了解了影像组学研究的一个简单流程:
1) 影像数据获取―>2)肿瘤的标定、分割―>3)影像特征的提取―>4)数据挖掘分析[Radiomics: Images Are Morethan Pictures, They Are
Data]一文中,将组学研究流程总结为5步:

1 影像数据获取
影像数据包括CT、MRI、PET、超声影像等,实验讲究控制变量,因此在一个影像组学研究中,影像数据的客观采集方式是恒定的:同一机器、同一序列、同一参数,如果扫描技师也是同一个人(最好长得还比较帅的那种),并在扫描时保持同一种状态,就完美了。但想要完全控制变量,是不可能的。尤其是数据收集那么困难,而且还得排除好多不能入组病人,好多影像质量(比如机器抽风)不行的情况下。但有一点知道:CT、MRI、PET等数据没有混合分析的先例。(我感觉自己的机会来了,诺奖在向我招手,我准备下楼和面馆老板探讨下混合分析模型的可行性)
2 肿瘤分割
肿瘤分割是必须要做的,因为第三步提取的影像特征,不是病人整张影像的所有特征,而是影像中肿瘤所在位置的特征。(就像ikun们爱的是他的盛世颜值和肌肉怪兽,而不是爱他的篮球技术,虽然他护球像亨利,并且曾经教过欧文运球)
肿瘤分割算法很多,本文总结列举如下(未一一详尽,但各个方面皆有涵盖)。

参考文献:A Review of Image Segmentation Methodologies in Medical Image
分割形式有自动分割,半自动分割,和人工分割。其中,人工分割通常被用来作为为标准,衡量分割算法的优劣。实际操作中,各种分割算法,都有其自适应的场景、范围、条件,特别受制于客观条件。现在也没有哪种算法敢站出来,说自己适应力强,准确性高(我又一次看见诺奖向我微笑),所以,最可靠的,还是临床医生们自己手动勾画ROI(Region of Interest),实际科研中,临床用得最多的,还是纯手工(我们行业内称顶级智慧型生物智能勾画法)。 【https://zhuanlan.zhihu.com/p/70758906】(对,你没看错,是人均百万年薪,藤校毕业的知乎)里面从传统分割算法一直到深度学习分割算法都进行了较为细致的讲解。
3 影像特征的提取
关于特征提取,传统放射科医师仅通过肉眼阅片方式,依赖直观长久的临床经验对肿瘤进行诊断,从而为肿瘤的治疗决策提供方向建议。但是,病人在放射科扫描留下的MRI,CT等影像数据,包含大量的潜在影像信息,比如,肿瘤块的肿瘤图像的灰度值范围、强度、细胞内部变化的特征等。而这些潜在信息,仅凭影像医师的临床经验及其肉眼能力,无法准确获得。因此,传统的肿瘤治疗方案的决策,浪费了本该用起来的宝藏。
影像组学方法,简单来说,其实就是大数据技术和医学影像辅助诊断的有机融合。概念中提到“高通量地提取大量影像信息”,所谓高通量(计算),指在用最少的资源、最快的速度、大量计算体系的各种性质,从而达到探究、预测物质性质的一种科学研究手法。影像组学运用高通量计算,在勾画好ROI的影像数据中,能够快速提取成百上千个影像特征。特征类别及其数量总结如下:
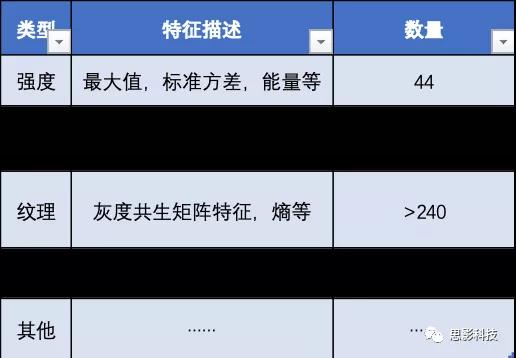
现在有很多平台可以实现影像特征提取的功能,比如Artificial
Intelligent Kit(A.K.)、3D Slicer等。
4 数据挖掘分析
4.1 特征筛选(降维,让我想到了刘慈欣老师三体中的二向箔降维打击)
特征筛选是影像组学必须做的一步:成百上千个影像学特征(自变量)【现在大部分组学分析还会加入临床特征、基因特征等】放到某个模型中进行训练,会累死计算机不说,模型效果通常还很差。
举个例子,实际生活中,把主要矛盾解决了(缺钱),大部分次要矛盾就随之消失了(可以买衣服了,可以吃火锅了),生活开始变得美好。特征选择是一样的道理,成千上百个特征,对因变量(Y,自己要研究的东西)有重要影响的,可能就几个几十个。做了特征选择,消除冗余信息,避免多重共线性,简化模型,使得模型更具有泛化能力(模型的通用性,说明模型不止是在训练数据上表现得好,随便拿一批数据来,该模型一样能正常发挥作用),这就是特征工程存在的意义!
特征选择方法有很多:
1)过滤式:卡方检验、信息增益、相关系数(初步使用,但通常会筛掉大部分特征);
2)包裹式:递归特征消除(反复的构建模型,然后选出最好的特征);
3)嵌入式:岭回归、lasso回归(使用频率很高,思影的机器学习课程用一天专门教这个);
4)机器学习模型:支持向量机(SVM,思影科技课程涵盖)、决策树(DT)、随机森林(RF)等(虽然这些机器学习模型自带了特征选择功能,能自动对特征的重要度进行排序,但实际操作中,不建议得到所有特征就用模型。通常会死的很惨烈,特异性、敏感度,想要的AUC值不会理想)。一般讲特征降维,都会说主成分分析(PCA,思影的机器学习课程也会有此内容),但在样本量小于特征量时,该方法是失效的【原因是参数与非参数的区别,在此不赘述,见下节】,因此以上没有列出。具体想学习的话,就直接点击以下链接,一旦拥有,别无所求:
第七届脑影像机器学习班(重庆)
4.2 模型建立:分类、预测
前面做了很多重复、耗时的工作,都是为了实现最终目标:建立一个优良模型,使得研究对象不管是分类也好,预测也罢,都有一个非常好看的ROC曲线,AUC值。
模型从参数角度考虑,可以分为参数模型和非参数模型。参数模型的条件较为苛刻,对数据分布和参数大小都有要求。早期统计学分析,由于数据量小,特征量少,所以一直是参数模型的天下。但大数据时代,传统的参数方法无法克服现存的维度灾难(样本量小于特征个数,再次想到三体),所以非参数方法,非参数模型应运而生。非参数模型对数据的分布条件不做限制,也不需要规定特征的维度,自己能够在训练过程中找到规律,形成自己的预测“函数”。(比如面馆老板的顾客预测模型,在他和我热烈的探讨中,略微透露了一点他的模型就是非参数模型)
现在,大部分机器学习都属于非参数方法,尤其是在影像组学的应用中。影像数据收集较慢样本量小,但影像特征却成百上千。经过特征选择,可能还会存在几十个上百个特征用于模型训练,用于分类,预测。
组学分析中常用的机器学习模型大多既可以做分类也可以做预测,如SVM,KNN,DT(RF,GBDT,XGBOOST:都是在DT基础上的集成算法),NB(朴素贝叶斯,有很强的前提条件),神经网络等。这些模型的算法都很优美,值得一推。实际操作中,SVM和RF(随机森林,我知道三体里的黑暗森林法则)两个模型表现都很稳定,其中,RF相较于SVM来说,由于参数稳定,不必特别调整且更方便。神经网络虽然特别火,但样本量小(不超过1000)时,不建议使用,样本量不足够大时,机器学习算法比神经网络表现更好【不然深度学习就不用等到大数据时代才出头了】。
非参数模型有三好(索8,k5,迈锐宝):
1)可变性:可以拟合许多不同的函数形式;
2)表现良好:对于预测表现可以非常好;
3)模型强大:对于目标函数不作假设或者作微小的假设。
同时,局限性一样存在:
1)需要更多数据:对于拟合目标函数需要更多的训练数据;
2)过拟合:有更高的风险发生过拟合,对于预测也比较难以解释;
3)速度慢:因为需要训练更多的参数,训练过程通常比较慢。
如果特征选择工作做的到位,参数模型可以用起来的话,自然更好,因为他也有三好:
1)简洁:理论容易理解和解释结果;
2)快速:参数模型学习和训练的速度都很快;
3)数据更少:通常不需要大量的数据,在对数据的拟合不很好时表现也不错。
Tips:
1)训练模型时,注意训练集和测试集的划分,通常情况是7:3,也可以自定义。但不要只留几个样本来做测试。样本量只有小几十个的时候,不建议X-folds cross validation
2)保持数据的平衡,如果研究目标有100个样本值,但90个都是阴性表现,这个指标就没什么分类、预测的价值了。因为从一开始,你的模型就是错的。举个例子:面馆老板的店,第一天开张的时候,前122个客人都说要加香菜,久而久之老板的预测模型就形成了客人吃面都要加香菜的模型,但第123个客人(也就是我)不仅不吃香菜,并且感到很愤怒,把面馆老板毒打了一顿,那他的客户模型就是错的。敏感度为0。
5 辅助诊断
影像组学的终极目标是复诊临床医生进行诊断工作,其分析结果可以从两个维度进行呈现:
1)横向角度:影像特征集合基因特征,临床特征进行数据挖掘分析,实现肿瘤的筛查,诊断,分级及分期的预测。也可进行肿瘤的分子生物学特征分析,为其靶向治疗方案提供科学依据。
2)纵向角度:结合随访信息,影像组学通过治疗前后的图像分析,可以做治疗效果预测,患者生存期预测,治疗有效性预测等,为临床制定个体化、精准化的治疗方案提供帮助。
今天就先聊到这里,本篇文章完全是我用顶级智慧型生物人工智能完成,什么叫真正的国际顶级代码高手?(战术后仰),我去找Tony老师做人工智能量子烫了,他的模型也预测了我今天会去,并且会选择他们店里最雍容华贵的造型,我们下期再会。

文末不做点广告,怎么对得起观众呢,挨个点开学习,转发,报名,它能不香吗?觉得本文不错,给个转,你懂我:
第二十六届磁共振脑影像基础班(重庆,欲练神功,必先打基础)
第七届脑影像机器学习班(一起走进人工智能新时代)
第六届磁共振ASL数据处理班(不打药的灌注,NON-BOLD fMRI)
第五届小动物脑影像数据处理班(首先你得有7t)
第二十四届磁共振脑影像基础班(同26届,寒假期间)
第九届脑影像机器学习班(是的,你没看错,12月还有)
第二十五届磁共振脑影像基础班(南京)
第十二届磁共振脑网络数据处理班(南京,需基础班打底)
第八届磁共振脑影像结构班(南京,freesurfer!)
第八届脑影像机器学习班(南京,11月,人工智能就是火)
第十届磁共振弥散张量成像数据处理班(DTI,DKI,能不香吗?)
第一届弥散磁共振成像数据处理提高班(南京,NODDI,HARDI)
第五届任务态fMRI专题班(南京,古典回归,强假设)
第五届脑电信号数据处理提高班(南京,需要非常强的基础)
第十八届脑电数据处理中级班(南京,需要一定的基础,带着知识过年)
第六届脑电信号数据处理提高班(难度高,以武会友)
第五届脑电数据处理入门班(南京,零基础即可)
第十七届脑电数据处理班(重庆,11月,需一定基础)
第五届眼动数据处理班(重庆,本月开班,R唱主角,错过可惜)
第六届近红外脑功能数据处理班(上海)
思影数据处理业务一:功能磁共振(fMRI)
思影数据处理业务二:结构磁共振成像(sMRI)与DTI
思影数据处理业务三:ASL数据处理
思影数据处理业务四:EEG/ERP数据处理
思影数据处理服务五:近红外脑功能数据处理
思影数据处理服务六:脑磁图(MEG)数据处理
招聘:脑影像数据处理工程师(少年,我看你骨骼惊奇)