���е�Ԥ��ģ�ͳɹ������˾ƾ�ʹ���ϰ���AUD�����ߺͶ����顣Ȼ����ʶ��˭������AUD��Ԥ��ģ�ͺ�ָʾAUD���Ե����������Բ����������ŦԼ������ѧ����ѧϵ��Sivan Kinreich��Jacquelyn L.Meyers ������MolecularPsychiatry��־�Ϸ���������о���
Ŀ�ģ�
���û��ڷ�չǰ���ݵ�AUDԤ��ģ�ͽ��������о�������ȷ��˭���ƾ�ʹ���ϰ���AUD�����������Լ�Ѱ������������
������
���о���������N=656������ŷ�������ˣ�EA���ͷ�ŷ�������ˣ�AA��Ѫͳ�ĺ���ͷǺ�����ƾ��ж��Ŵ�ѧ�о�����COGA����ļ����12���δ��AUD��656�����ԣ������ʱ���Լ7�꣩����������������Ϊ��AUD(n = 328)��δ��AUD(n = 328)���鱻�ԡ�ʹ�û���ѧϰ������220��EEG����,149�����������̬��(snp)�����Լ���������ʷ������FH��,��ʹ������֧��������(SVM)����������Щ��������Ԥ�⣬ͬʱ�����䡢�Ա��Ѫͳ�����˷ֲ������
�����
�����������EAԤ��ģ����ȣ�AAԤ��ģ�;��������ĸ�ȷ�ʣ�������EA��AA����Ѫͳ�����У�Ů�Ե�ģ��ȷ�ʶ��������ԡ�EEG+SNP�����Ķ�ά��ģ����EA��AA������������������EEG�����������SNP�����ĵ�һģ�͡����ֶ�ά��ģ�͵�������AA������(12-15��16-19��20-30)��EA������(16-19)����÷����еõ�֤ʵ����������Ѫͳ�������У���������������������������ϴ�����������˸��ߵ�ȷ�����֡�ĸ��AUD�����ģ��������Ѫͳ�����е�ȷ�ԡ�����Ԥ��ģ��ͬʱʶ����˶����м��������EEG������SNPs(���������̬��)�����������ϵ͵ĺ�������gamma�����ϸߵ�������������(delta��theta��alpha)���ϸߵĶ�Ҷgamma���������ϸߵĶ�Ҷ��beta������ԣ��Լ�5��SNPs:rs4780836��rs2605140��rs11690265��rs692854��rs13380649��
���ۣ�
��ά����ģ�ͱȵ�ģ̬ģ��(EEG��SNPs)�����˸��õ�Ԥ�⣬��FH������ʷ���������������ӽ�һ�������Ԥ����������ǿ���˳����������ӵ���Ҫ�ԣ�����Ƿֲ�����Լ����㷺��ѡ�����������˸��õ�Ԥ���������ȷ�Ĺ�����AUD�ķ�չ��
���ԣ�
ȷ��˭���ƾ�ʹ���ϰ���AUD����ȷ�������������Լ�Ѱ���������������һ���ش���ս���о�������������ʱ�����Ʊ����������ӣ��Ŵ��ͻ������ػ�����ת��ΪAUD�ķ��ա�Ȼ����˭����չAUD����ȷ�����Բ������������о���������һά������ȣ��Ŵ�����������������Ϣ�Ķ�ά��ģ���ܸ��õط�ӳDZ�ڵIJ�������ѧ���ڹ�ȥ��ʮ���У�����ѧϰ(ML)�����������ھ�����Ѿ��ɹ���Ӧ���ڶ�ά���ݼ��ķ���������������Ŵ����ݣ�����������ϣ��������ھ���Ļع鷽����ML֧��������(SVM)�������ѳɹ�Ӧ���ڼ���Ԥ�⣬�ٴ���Ͻ�����Լ������ϰ��ȡ�������˵��AUD���������õ�������������EEG�������Ӻ�Ƶ���ʡ�EEG������������AUD����ʷ(FH)��������������Լ��Ŵ���Ϣ��ʵ����������ȷ�ԡ����ǣ�Ŀǰ��û�л��ڷ�չǰ���ݵ�AUDԤ��ģ�͵������о�������������ģ�Ϳ����ṩ���������־�����Ҫ��Ϣ�Լ���չAUD�������ԡ�
���о�ʹ������COGA(��������SNP��FH)�������ά���ݣ�����ŷ��������(EA)�ͷ�ŷ��������(AA)Ѫͳ�ĺ����COGA�ռ����ݣ�������AUD/��AUD���壬֮����ò��Ƚϻ�AUD֮ǰ��֮���״̬���о��ߵ����ļ����ǣ���ά����ģ�ͽ��ȵ�����ÿһ��ģʽ(EEG�����ͻ���������)�������õ�Ԥ�⣬��FH���������ӽ���һ������Ԥ��������ڸ��о��У��о��������һ���ල��ML����(SVM)�������б��Է�Ϊ��������ڱ����ΪAUD�ı��Ժ�δ�����ΪAUD�ı��ԡ��÷�����EEG��EEG���������Ŵ�ѧ��FH����Ϣ��һ����������ƾ����ѡ��ƾ������;ƾ����EEG���������������̬�ԣ�SNPs��������Ϊ������ʶ��һ�������ķ�������һ�����������ǿ��ƿ��ܵ���ģ�ʹ������Ļ���������Ӱ�죬�������䡢�Ա�����ȡ����䡢�Ա��Ѫͳ�ֲ��������Ϊÿһ�齨�������ġ�����ȷ��ģ�ͣ�ʹ�÷ֲ������ƻ��ӱ��������䡢�Ա��Ѫͳ�������������о���Ԥ��ģ����������Ե���������ǿ����Щ������AUD��չ�µ����⡣
������
���ԣ�
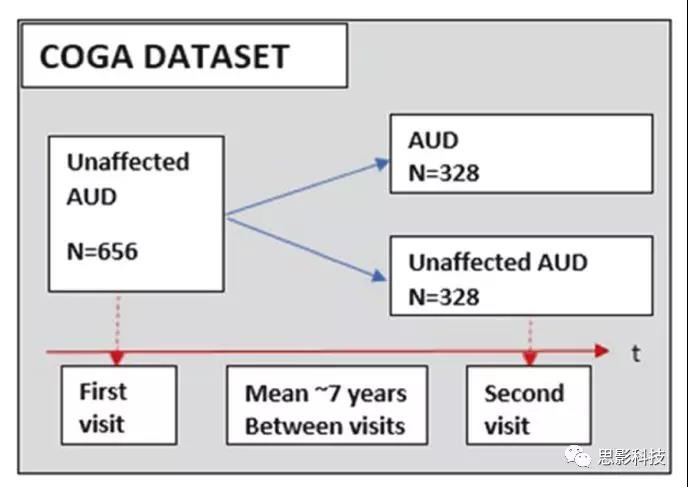
�����������Ծƾ��ж��Ŵ��ĺ����о���COGA����ļ��656������(376�����Ժ�280��Ů��)��������12-30��֮�䡣���о��ռ���6��վ������ݡ��о���ֻ����˵�һ�ξ���ʱδ��Ӱ��ı��ԣ����ڼ������������½�����������������ʱ�����Լ7�꣩��ͬʱ�����Ƿ�Ϊ����: AUD��Ͷ����顣��ͼ1��ʾ��
AUD�飺�״ξ���ʱδ�����ΪAUD�������ʱ���ڣ�ƽ���������=7.36��3.01 �������Ϊ����AUD�ı��ԡ� n= 328,��188�����ԣ�140��Ů�ԣ�,ƽ������:17.88��2.95�ꡣ
�����飺�״ξ�������ʱ���ڣ�ƽ���������= 6.64��3.35����û�б����ΪAUD�ı��ԡ�n = 328,��188����,140��Ů�ԣ���������������AUD����ƥ�䣨p=0.5��,ƽ������17.69��3.11���ں���������,����Ѫͳ(EA, AA)������(�ഺ������:12
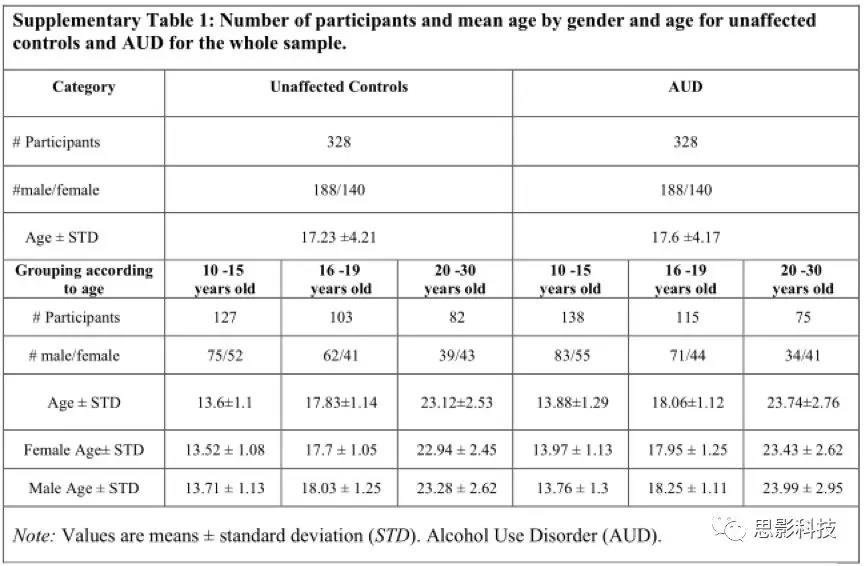
- 15��,�ഺ������:16 - 19�꣬����:20 - 30��)���Ա�(�С�Ů) �Ա��Խ�һ������������е��鶼�ǰ�����ƥ��ġ�Ѫͳ���Ա����������������һϵ�еķ���������ͬ�ı����Ӽ���ÿһ�����ϸ˵���������1�ͱ�2��
ͼ1����������ͼ
�����1�����Է�������
�����2����������ģ���µķ�������
���̣�
�Ե����ݲɼ���Ԥ����EEG�ɼ������б���������������û�����չ10-20ϵͳ��64ͨ���缫ñ��¼��4���ӵľ�ϢEEG���ο��缫λ�ڱǼ⣬�ӵص缫λ��ǰ��۵�ͼ���ۿ��ϴ�ֱ�缫���������ˮƽ�缫��¼������Ƶ�ʣ�500Hz��512Hz��Ƶ����Χ��0Hz~100Hz��
Ԥ������ʹ��MATLAB+EEGLAB���е�ͨ�˲�����Χ��0~60Hz,����60Hzʱ�������ְ����˲�ȥ�������������αӰ��
������ȡ
EEG��EEG��������ȡ������EEG��ʱƵ������ʱ��ֱ���Ϊ0.002s��Ƶ��0.3Hz�����������ÿ���缫�ľ���Ƶ�ʷ�Ϊ5��Ƶ��delta(1-4Hz),theta(4�C8 Hz), alpha(8�C12 Hz), beta(12�C30 Hz)��gamma(30�C60Hz)�����缫����Ϊ5������Ȥ����Ҷ(F3, F4, F7,F8), ��Ҷ(P3, P4, CP1,CP2), �Ҷ (T7, T8),�¶�Ҷ(P7, P8, CP5,CP6)����Ҷ(O1, O2)��
��ȡ�����µ�����������
1�������ף�40������������ÿ��ROI�ڵĵ缫��Ϊ�����������ƽ���������Ҷ˫�����ÿ���缫����/���ʱȡ�
2�����ֵ��90��������������ÿ��Ƶ���źŵ�����ԡ�
3�����ֵ��90��������������ÿ��Ƶ���źŵ�Ƥ��ѷ���ϵ����
����ʷ��FH��������ȡ����ĸ��AUD���ݣ�ĸ����AUD���ݣ���2����������
�Ŵ�����(SNPs)������ȡ��SNPs��149���������Ǹ�����������漰EA��AA��Ⱥ��ȫ����������о���GWAS����EEG�;ƾ���������������ѡ��ġ���������EEG����������DSM-IV�ƾ����������24Сʱ�������������
�����������������ʣ�98%��Υ��Hardy-Weinbergƽ��(P<10−6)��snp���ų��ڷ���֮�⡣ȥ��Mendelian���������ӣ�Ȼ��ʹ��SHAPEIT��IMPUTE2�����ݴ���1000�������顣����֮������0.90�ű���Ϊһ������͡���������ȡ�����У��ų�������С��λ����Ƶ��(MAF)
<0.03��snp���Լ�������Ϣ�÷�<0.30��snp��
����ѡ��ͷ���ģ����
ÿ�飨EEG��SNP��EEG+SNP�����ԣ�Ů�ԣ�AA,EA,��ͬ�����飩�ֱ��������ѡ��ģ���ƺ���֤��Ϊ�˿��Ʊ�������ϣ����������������ͳ��ģ�͵�Ԥ�⾫�ȺͿɽ����ԡ���������ѡ���о���ʹ��LASSO��LASSO��ϡ��ȣ�����������Ϊ0��ϵ������ֵ��ʹ�����ڼ��ٹ��Ʒ����ͬʱ�ṩ��һ�����߽����Ե�����ģ�ͣ���˶�������ѡ��������ơ����ڻ����������е�Ӧ�ñ�����ѡ���������д����Ե���������ʵ������ķ��ࡣ����ʹ��ʮ�۽�����֤��CV��ȷ����������ʹ�� AUD�Ͷ�����������ǩ��Ϊ��Ӧ���������з���ϵ���������������ں��������С�����������������ļ���������������Խ��з��࣬��Ҫô��AUD�飬Ҫô�Ƕ����顣
ѵ��һ�����Ժ�֧����������ʮ�۽�����֤������������AUD��Ͷ����飬���������Ż�������ʮ�۽�����֤�����Ա������Ϊ10����ȵ��飬Ȼ����10���е�9����ѵ��һ��������������ʣ�µ�һ�����Ͻ��в��ԡ�ÿһ���۵����������ݼ������ң��Ա�֤����ԡ�����������ֶԷ�������Ӱ�죬�ظ��������ʮ�Σ�������������ƽ����Ϊ������ģ�����ܣ���¼������������TP,��ȷ�����AUD����������������TN����ȷ����Ķ����������÷֡����ྫ�ȼ���ΪTP��TN֮�ͳ������з������֮�͵ı�ֵ��ʹ�����������AUC��F-scores�Է���ģ�ͽ������ۡ�F���壺
F=(1+��2)������ȷ�����ٻ��ʣ�/���¡���ȷ��+�ٻ��ʣ�
����Ϊ��Ȩ���Ⱥ�����ֵ�ĵ���ƽ��ֵ����ȷ�ʣ������Ե��������������Ե��������ϼ����Ե�����, �ٻ��ʣ������Ե��������������Ե��������ϼ����Ե�������������Ϊ1��
ͳ�Ʒ�����
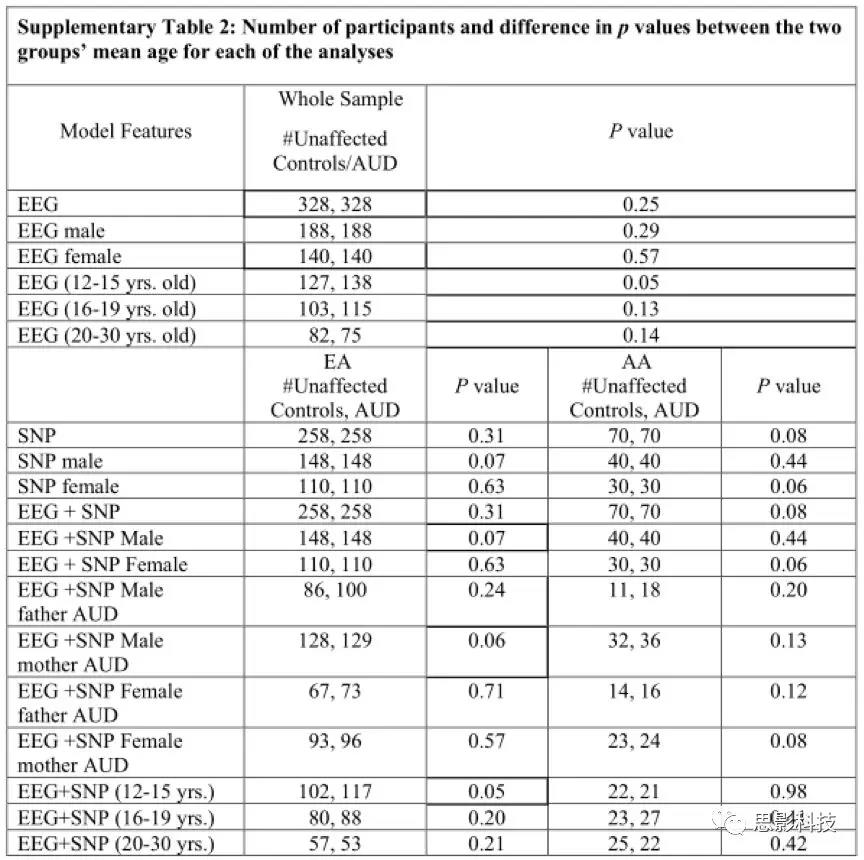
����˫βt�����Ƚ����ַ���ģ��ȷ��(�Ƚ�100������ֵ��10x10 ������֤)��Ϊ��ȷ��һ���ȶ�����������������Ҫ������(Ȩ������)���о��߶�10��ģ���ظ�������ƽ������Ȩ�ء����������������˻���EEG�ķ��࣬���κ��漰�Ŵ���Ϣ�ķ������ֱ��EA��AA�������С������Ա��������ֱ����ģ�͡�
�����
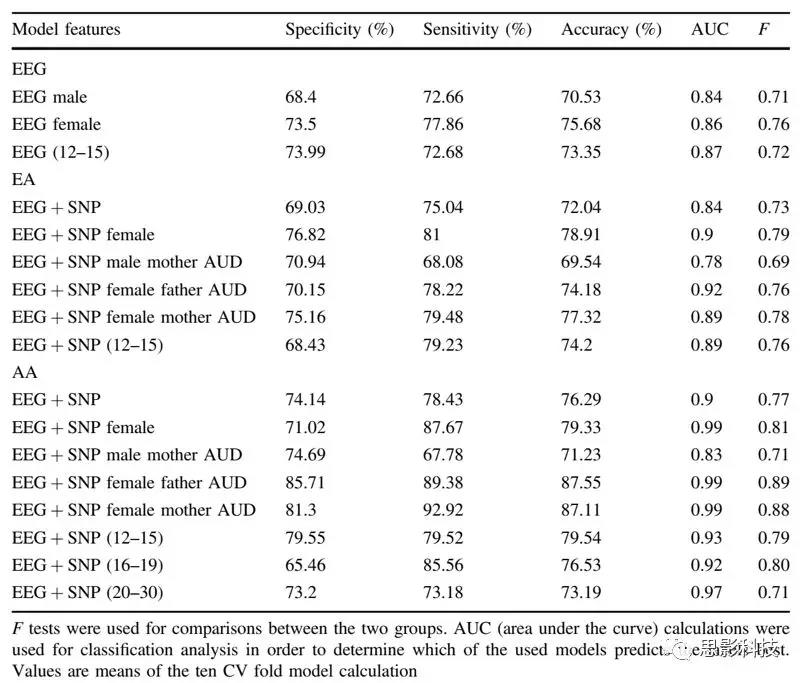
Ԥ��ģ�Ͳ��þ����ص������IJ�ͬSVMԤ��ģ�ͺ���Ѫͳ��������ԱֵIJ�ͬ�������Ӽ������һ��ʾ���ܽ���������Ԥ��ģ����Ѫͳ���Ա�����䷽��ĵ÷ֽ��������ģ�������������ԡ������ԡ�ȷ�ԡ�AUCֵ��F��������1����ͬģ���¸���Ѫͳ�����䡢�Ա��AUD�Ͷ��������Ľ��
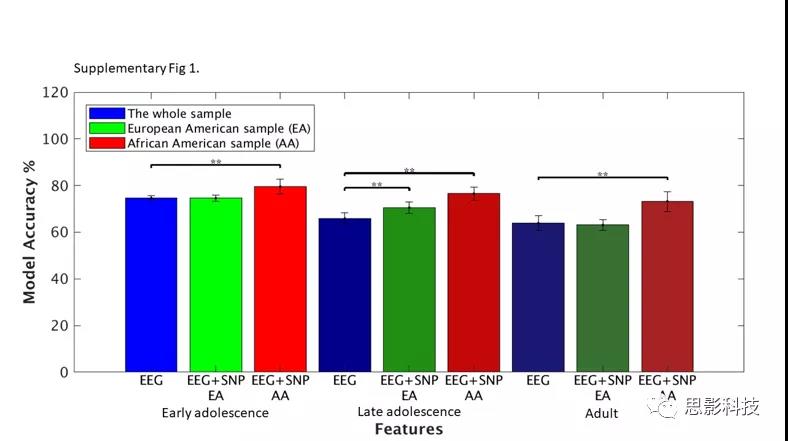
����ͼ1�����������Ѫͳȷ��ģ�͵�ȷ�ԡ�ͨ��������EEG������EEG+SNP���������Ը�������з��ࣺ���������ڣ�12-15�꣩�����������ڣ�16-19�꣩�ͳ��ˣ�20-30�꣩�������������AA������EA������2���������У�����ģ�Ͷ����ڵ�ģʽEEG����ģ�͡�
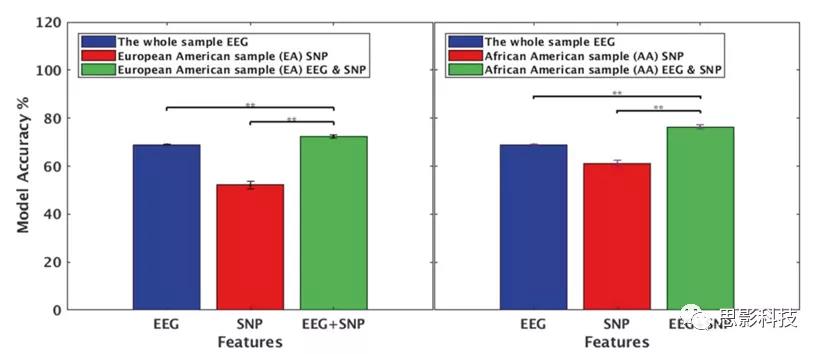
ͼ2.����Ѫͳȷ��ģ��ȷ�ԡ�����EA��AA��������ʾ�˸���EEG������SNP������EEG+SNP�����µķ��������������:����ģ�ͱȵ�һ����ģ�;��и��ߵľ��ȡ�
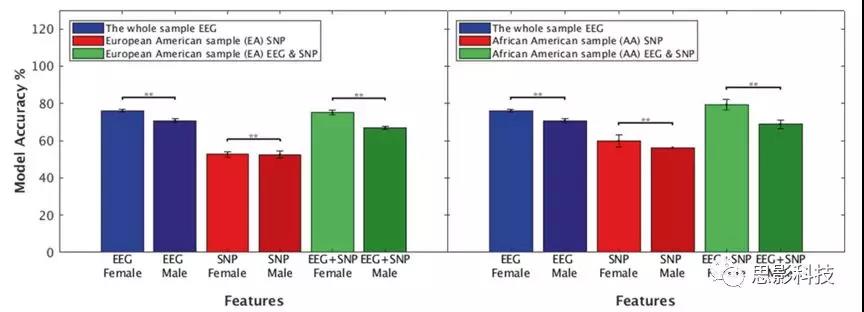
ͼ3.����Ѫͳ���Ա�ȷ��ģ��ȷ�ԡ���ʾ�˶��ڲ�ͬ�Ա��EEG������SNP������EEG+SNP�����µķ��������������������������ģ�͵�EA��AA�����У�Ů�Ե�ȷ�Ե÷־��������ԡ�
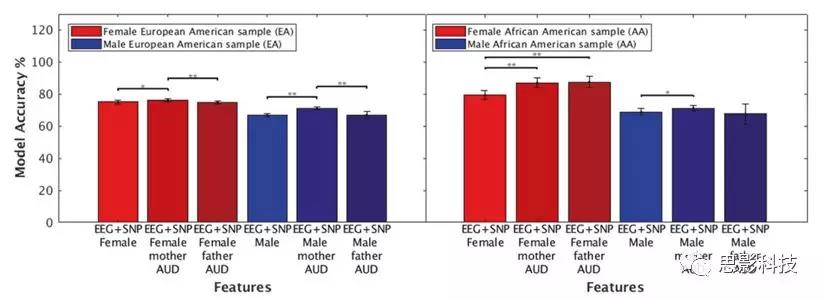
ͼ4������Ѫͳ���Ա�ͼ���ʷȷ��ģ��ȷ�ԡ����Ա�Ļ������ټ���FH�����������������AA��EA�����Ժ�Ů�������У�ĸ��AUD���������ģ�͵�ȷ�ԡ�����AUD���������AAŮ���������ģ�͵�ȷ�ԡ�
��1�ܽ�����Ҫ��Ԥ��ģ����Ѫͳ���Ա����������µĽ�����������������AA�����Ľ��������EA�������ߣ�P<0.001������AA��EA�����У�Ů�Ե÷־��������ԣ��������������÷ָ����������������顣�ӱ�1��ͼ2���Կ���������AA��EA������EEG��SNP����ģ�Ͷ���EEG����SNP��һģ�;�ȷ�ȸ���(EA;
p (EEG vsEEG+SNP) <0.001, p (SNP vs EEG+SNP <0.001)(AA; p (EEG vs
EEG+SNP)<0.001, p (SNP vs EEG+SNP) <0.001)�������EA��AA����÷����еõ�֤ʵ(AA: p (�ഺ������ EEG vsEEG+SNP) <0.001,p (�ഺ������ EEG
vs EEG+SNP) <0.001, p (������ EEG vs EEG+SNP)
<0.001)��EA����������ģ�����ഺ�ڵ����ں����ڴﵽ����ˮƽ����û�г�������EEG��ģ��ȷ�ԣ���1������ͼ1����
�Ա�ֲ������ʾ��AAŮ����������������������ԣ�EEG��SNPs��EEG+SNP����ģ��)��ģ�;�ȷ�ȸ���(������:(����EEG vsŮ��EEG)<0.001,AA��p (SNP���� vs SNPŮ��)= 0.008,p(EEG + SNP���� vs EEG+ SNPŮ��)< 0.001),EA: p (EEG + SNP���� vs EEG+
SNPŮ��)< 0.001)��ͼ3��ʾ����
�ܶ���֮������EEG+SNP�����������̬�ԣ��������ģ���£�AA��EAŮ����ľ�ȷ�ȷֱ�ﵽ��79.33%��������=71.02%��������=87.67%,AUC =0.99, F = 0.81) �� 78.91%��������=76.82%��������=81%,AUC =0.9, F = 0.79),��AA��EA�����ഺ�����䷶Χ�ھ�ȷ�ȷֱ�ﵽ��79.54%(������Ϊ79.55%,������= 79.52%,AUC =0.93, F = 0.79)��74.2%(������=68.43%,������=
79.23%,AUC =0.89, F = 0.76)��
��ĸ��AUD����AUD��FH������EEG+SNP����ģ����Ƚϣ��������������졣��AA��EA�����Ժ�Ů�������У�ĸ��AUD����������ģ�;��ȣ�����AUD������������AAŮ����������ģ�͵�ȷ�ԣ���AAŮ�������У������˸���AUD��������ĸ��AUD������EEG+SNP����ģ�ͷֱ�ﵽ��87.55%������ AUD��������=85.71%, ������=89.38%,AUC=0.99, F=0.89) ��87.11% (ĸ��AUD��������=81.3%, ������=92.92%,AUC=0.99, F=0.88)���ĸ߾�ȷ�ȣ�����1��ͼ4����������Ա����漰�����Ե����ݴ���������ѧϰ���ݸ���Ȥ����ֱ�ӵ�����ģ���лת����֧�֣�
������Ե����ݴ������Ű�
��ʮ�߽��Ե����ݴ�����
�������Ե��ź����ݴ�����߰�
�ڰ˽���Ӱ�����ѧϰ��
�����7��EEG����
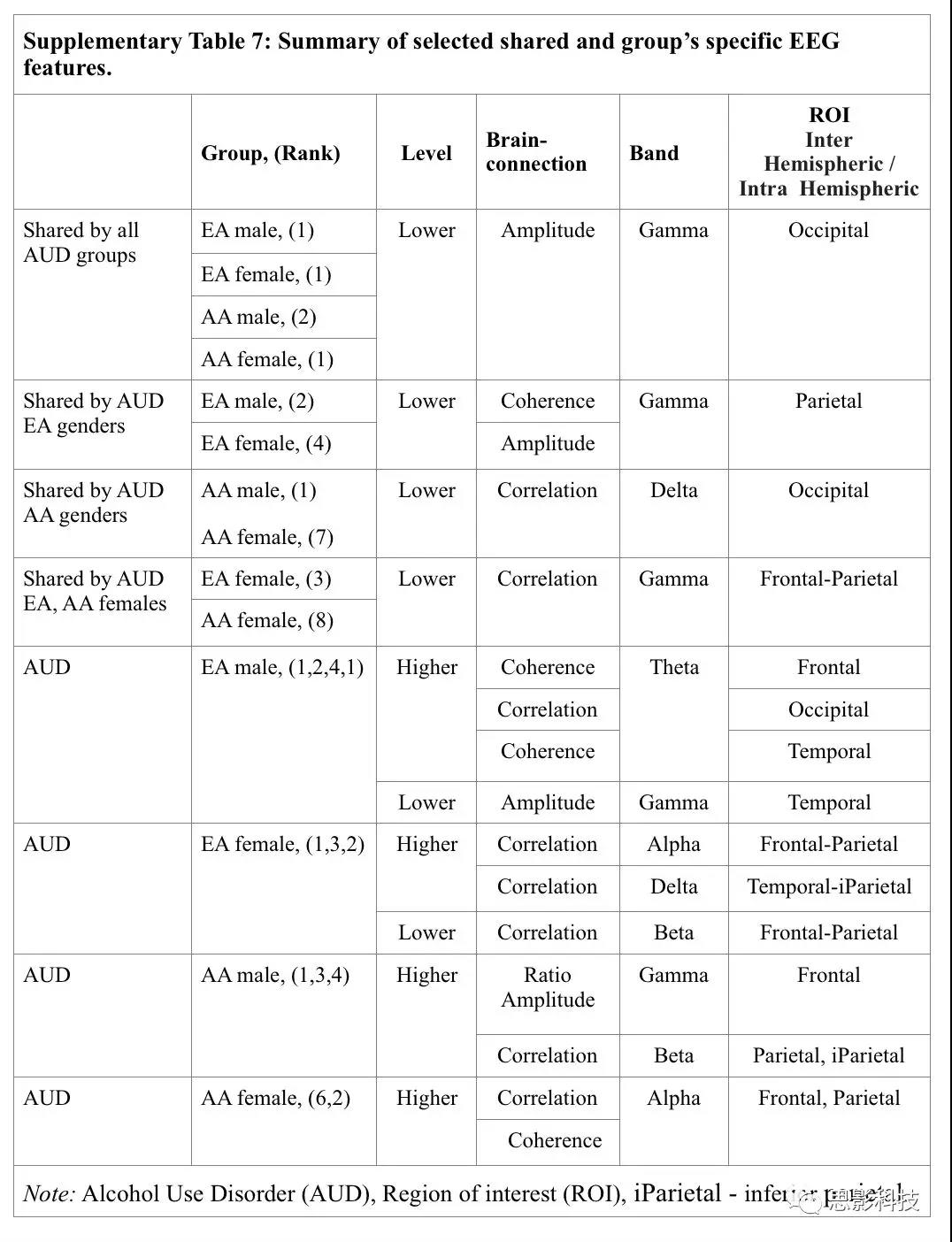
EEG������
�����7�ܽ���EEG+SNP��άģ���а�Ѫͳ���Ա�ֲ���ض��Ĺ��е�������������������AUD����һ�µ�EEGԤ����EEG+SNPģ��Ϊ�������Ӷ��������ı������ֿ����������ͺ�������gamma(��������������ӡ����)���ڶ������Ȥ����������߹�������(delta, theta,alpha)�����������ȣ�����AUD�������gamma������ϵ�(Ȩ������1-4)��EA-AUD�Ա�����нϵ͵Ķ�Ҷgamma����书������(����)�����(Ů��)(Ȩ������2��4)��AA- AUD�Ա�����нϵ͵���Ҷdelta����������(Ȩ������1��7)��EA��AAŮ�����������нϵ͵ĶҶgamma�����(Ȩ������2��8)����һ���棬EA-AUD�����Ե���Ҷ����Ҷ���Ҷ�İ���书��������ʾ��theta����(Ȩ������1��4��5),������Ů�Զ��ڶҶ(EA��AA�飬Ȩ����������2, 8)��Ҷ(EA�飬Ȩ�صȼ�4)����ʾ�ϸߵ���������������(delta��alpha)������IJ�֮ͬ������:��Ҷ����(AA����)���нϸߵĶ�Ҷ��/����ʺͽϸߵ����ϵ��(Ȩ��������2)������Ҷ����(EAŮ��)���нϵ͵����������ϵ��(Ȩ��������5)��
�����12��SNP����
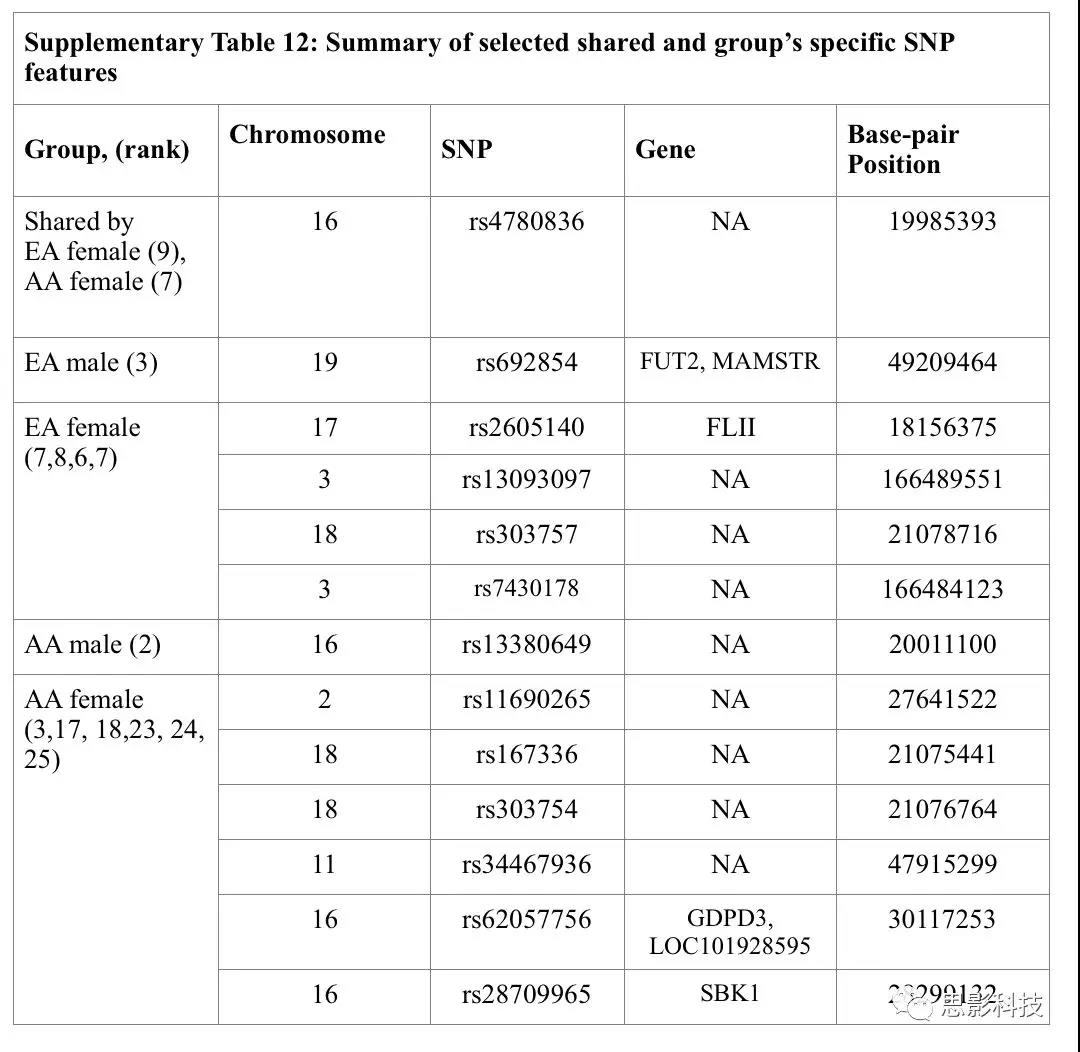
SNPs�����������̬�ԣ�������
�����12�ܽ������ȶ��ĵ�SNPԤ������Ԥ��AUD�����ԡ���16��Ⱦɫ����(rs4780836��Ȩ������9,7)���� EA��AA-AUDŮ�Թ���һ��SNP����17��Ⱦɫ��Ļ���FLII��RS2605140,��������7����18��Ⱦɫ�壨rs303757��Ȩ������18����3��Ⱦɫ���ϵ�2��λ�㣨rs7430178��Ȩ������3���Ϸ������Ա��Ŵ�������λ�㡣
AAŮ�������У�������2��Ⱦɫ������1��λ��(rs11690265��Ȩ������2)��18��Ⱦɫ������2��λ��(rs167336��rs303754��Ȩ������18)��11��Ⱦɫ������2��λ��(rs34467936��Ȩ������11)��16��Ⱦɫ������2��λ��(rs62057756��rs28709965��Ȩ������18)��
��EA-AUD����������19��Ⱦɫ��FUT2������ (rs692854��Ȩ������19)��AA-AUD����������16��Ⱦɫ����(rs13380649��Ȩ������16)�ֱ���һ��λ�㡣
������ԣ�Ů�Ա����Ծ��и����SNP����(#SNP (AAŮ��)= 8��#SNP
(AA����)=1��#SNP (EA��)=5��#SNP (EA����)=1)��
���ۣ�
����ѧϰ��Ӧ��Ϊ���������������ݵĴ��¼���Ԥ��ģ�ʹ�����ϣ�������о�ʹ����COGA�ḻ��EEG���Ŵ���FH���ݼ�����Щ���������ڷ���AUD֮ǰ��12��֮ǰ�ĸ��壬����������ã����������Ҫô�����ΪAUD��Ҫôδ��Ӱ�졣���ǵ�һ���о��ƶ���Ԥ��ģ�ͣ�Ϊ��Щ˭�����ڷ�չAUDʹ��ML��ά������ͬʱ�����Ա�����ȡ��о��߷����˸��ߵ�ȷ�ԣ�AAģ�͵�Ԥ���ʸ���EAģ�͡�AA��EA�����н��EEG��SNP�����Ķ�ģ̬ģ�ͱ�ֻ����EEG�������̬�������ĵ�ģ̬ģ�͵õ����ߵ�ȷ�Է�������Щ�о������AA�����IJ�ͬ������(�ഺ������,�ഺ�ں���,�ͳ���)��EA�����ഺ��������ĺ�������(��ͬ�����ݼ�)�еõ�֤ʵ���Ա������ʾ�����ߵ�ģ�;������ƣ������������(EEG��SNPs��EEG+SNP����ģ��)ģ����EA��AA����Ů��������������顣�о��߽�һ�����֣����Ա�ͬ��ģ�������Ӹ�ĸ��AUD������EA��AA��������ʾĸ��AUD��ʷ��Ϊ���������������˻���EEG + SNP����ģ�͵�ȷ�ԡ�����AUD��ʷ����AAŮ�Ի����бȻ���EEG+SNP������ģ�������ģ�͵�ȷ�ԡ��������������У����������Ƚ��곤�������˸��ߵ�ȷ�����֡�ÿ��ģ�͵�EEG��SNP��������������ʾ���Ա��Ѫͳ�����Գ�ΪAUD���Ա���
ȷ��Ԥ��ģ�������ڸ���Ⱥ����������������Ӽ�����ǰ�о��и��������������õ�Ԥ����AUDŮ�Ա����Զ࣬AA-AUD��EA-AUD�࣬����ζ����Ҫ����Ѱ����ÿ��Ⱥ����صľ�����Ҫ�Ի���ǿ�������ض�Ⱥ����������磬��������Ⱥ��ĵ�Ԥ�����������ģ�������Ŵ��������й�(�������е�����ģ����ֻ�漰һ��SNP������Ů��ģ�����漰4-5��SNP)�����о����֣����Ա��Ѫͳ�У���AUD���ƾ�ʹ���ϰ����еĸ���(����������Ҷ)��gamma���Խϵ͡���Щ��������������ྫ��(������֢��˫������ϰ�������֢��AUD)��������ѧ������������һ�£��ڸ��־����ϰ������У�����Ҫ�ı仯ģʽ�ǹ�����Ƶ�ʵ����߶����͡�
һ���棬�о�����EA�з����˽ϵ͵Ķ�Ҷgamma(�����������)����EA��AA�з����˽ϵ͵ĶҶgamma�������ӣ���˵���ϵ͵ĺ�gamma������һ�ּ����������ǣ�����һ�ּ�������AUD���Ե����ء�gamma��ѱ�������Դٽ�ǰ���������¶���������Ϣ�����ӽϵ͵Ĵ������ϸߵ�Ƥ������ظ����gammaƵ�����ʺ������ӵĽ��Ϳ����Ǻ�Ƥ�����¶��Ͻ������жϣ����¸о���ִ�й����ϰ�������ܷ�ӳƤ�����ϸı䡣
��һ���棬�о��߷���EA���������Ժ�Ů��֮���������(delta��theta��alpha)�Ĺ������Ӷ�������ǿ����Щ��������������Ӷȵľƾ��и������������ע��������������ʡ��ע������
δ���о�����
1��SNP����Ϊ��Ԥ��AUD���Ե�����������
2�����о����֤����Ѫͳ���Ա��������Ԥ��AUD��չ��ģ���е���Ҫ�ԡ�
�ܽ
�ܵ���˵���о��߷��ֹ㷺�Ķ�ά���������˸��ߵ�ģ�;��ȣ�ȷ������ص��ض��������������õ�Ԥ��ģ���������Ŵ����ݺ�EEG�������ϵ�MLģ�ͱȵ���ʹ���κ�һ�ַ������ܻ�ø��õķ��ྫ�ȡ���Щ���������������ģʽ���ܷ�ӳ��AUD���ƾ�ʹ���ϰ�������ѧ�IJ�ͬ���棬�������������治��������ʹ�ö��ά�ȶԼ������з����MLģ�;���һ�������ơ���Щ���Ϊ�����Ի��ļ���Ԥ�ⷽ�����˴��š����ڲ�ͬģʽ��ģ�Ϳ�������ʱ��仯������(���ԵĽṹ����)�Լ��˵���������(��Ϊ������)ʹ�ù�ע�ض���Ⱥ��(�簴���䡢�Ա�Ѫͳ��FH���Ļ�����Ϊ���з���)�Ӷ���������������ֵ�ĸ��Ի�Ԥ��ģ�����ƽ����߸��Ի�������
ԭ�ģ�
Predicting risk for Alcohol Use Disorder using
longitudinal data with multimodal biomarkers and family history: a machine
learning study
S Kinreich, JL Meyers, A Maron-Katz�� -
Molecular ��, 2019 - nature.com
����ԭ�ļ������������ţ�siyingyxf ��ȡ,���˼Ӱ�γ̸���ȤҲ�ɼӴ��ź���ѯ��

��ɨ����߳���ѡ��ʶ���ע˼Ӱ
��лת��֧�����Ƽ�
��ӭ���˼Ӱ�����ݴ����γ��Լ����ݴ���ҵ����ܡ�����ֱ�ӵ���������ּ����������ӭ��������ѯ����
������Ե����ݴ������Ű�(�Ͼ���
��ʮ�˽��Ե����ݴ����м������Ͼ���
�������Ե��ź����ݴ�����߰�
�������Ե����ݴ������Ű�
�������۶����ݴ��������Ͼ���
��ʮ�߽��Ե����ݴ����ࣨ���죩
���߽�������Թ������ݴ�����(�Ϻ���
�ڶ�ʮ���Ź�����Ӱ����������Ͼ���
��ʮ����Ź������������ݴ�����(�Ͼ���
�ڰ˽���Ӱ�����ѧϰ��(�Ͼ���
���������̬fMRIר��ࣨ�Ͼ���
�ڰ˽�Ź�����Ӱ���ṹ�����Ͼ���
��ʮ��Ź�����ɢ�����������ݴ�����
��һ����ɢ�Ź���������ݴ�����߰����Ͼ���
�ڶ�ʮ����Ź�����Ӱ������������죩
������Ź���ASL������������ǣ����ݴ�����
�����С����Ź�����Ӱ�����ݴ����ࣨ���죩
�ڶ�ʮ�Ľ�Ź�����Ӱ������ࣨ���죩
�ھŽ���Ӱ�����ѧϰ�ࣨ���죩
˼Ӱ���ݴ���ҵ��һ�����ܴŹ���fMRI��
˼Ӱ���ݴ���ҵ������ṹ�Ź������(sMRI)��DTI
˼Ӱ���ݴ���ҵ������ASL���ݴ���
˼Ӱ���ݴ���ҵ���ģ�EEG/ERP���ݴ���
˼Ӱ���ݴ��������壺�������Թ������ݴ���
˼Ӱ���ݴ������������Դ�ͼ��MEG�����ݴ���
��Ƹ����Ӱ�����ݴ�������ʦ������&�Ͼ���