语音和音乐是人类对声音最复杂、最独特的认知方式。这两个领域在多大程度上依赖于可分离的神经机制?这种专业化的神经基础是什么?对于这两个问题,虽然已经有了部分认识,但是对具体细节仍旧知之甚少。一些研究已经提出,左半球的语音神经专门化和右半球的基于音高的音乐方面的专门化来自于对左右听觉皮层(ACs)对声学线索处理的差异。然而,domain-specific的研究表明,语音和音乐是由专门的神经网络处理的,但这种神经网络的偏侧化不能用低水平的听觉线索来解释。那么其专门网络的声学基础是什么呢?来自加拿大蒙特利尔实验室的研究者对这一问题进行了研究,成果发表在Science杂志上。本文通过有选择地过滤时间或频谱调制的歌唱语音刺激(语音刺激中的口语和旋律内容是交叉平衡的,是由无乐器旋律和句子语音合成的)。结果发现,语音感知只随着时间信息的调制而下降,而旋律感知只随着频谱信息的调制而下降。功能性磁共振成像数据显示,语音和旋律的神经解码分别依赖于左右听觉区域的活动模式。这种不对称性是由每个区域对频谱-时间调制速率的特定灵敏度所支持的。最后,信息减少对感知的影响与它们对神经分类的影响是平行的。本文研究结果表明,语言和音乐混合信号的声学特性与适应这一目的神经专门化之间存在匹配。
注释:在文中为了方便表述,句子一律为语音处理即语言的听觉处理,旋律一律为音乐处理。用材料特性来代表他们所代表的实质对象。
研究背景
尽管以往的经验性证据支持双侧听觉皮层对不同声学线索的处理,但是从当前研究的内容看,声学线索的复杂性被严重低估了:诸如spectrotemporal resolution、time integration window和振荡(oscillation)等信息虽然已经被用来解释半球特异性,但是却很难在一个可行的神经框架内直接测试这些概念,特别是使用自然的语音或音乐刺激(这里的“自然”指的是我们在寻常的生活中听到的语音或者音乐。实验刺激为了更好的分离神经响应和刺激之间的对应关系,需要对语音或者音乐进行声学特征上的分解,例如从频率上声学信息进行调制)。频谱-时间接受域(spectrotemporal receptive fields)的概念为听觉线索的神经分解提供了一个在计算上严谨且在神经生理学上合理的方法。该模型基于动物的单细胞记录和人类的神经成像,提出了听觉神经元作为频谱-时间调制(STM)的速率过滤器的作用。STM可能为解释ACs的偏侧性提供了一种机制基础,但声学STM特征、大脑半球的不对称性和处理复杂信号(如语音和音乐)时的行为表现之间的直接关系尚未得到研究。为此,本文的作者创造了一个刺激组,其中10个原始的句子与10个原始的旋律相交叉,产生了100首自然主义的无伴奏合成歌曲。这种跨刺激的语音和旋律域的正交化使得语音特异性(或旋律特异性)与非特异性的声学特征分离,从而便于控制任何潜在的声学偏差。作者创建了两个独立的刺激组,一个是法语组,另一个是英语组,以保证再现性和测试在语音间的通用性。然后,使用STM框架对声音信号进行了处理,并在时域和频域对各刺激进行了参数化处理。研究方法首先在一个行为实验中调查了STM rate对句子或旋律识别分数的重要性。以法语为母语的人(n = 27)和以英语为母语的人(n = 22)被出示成对的刺激物,并被要求辨别讲话内容或旋律内容。因此,两项任务设置的刺激是相同的,只有被试受到的任务说明的差异(即使用相同的声音材料,但判断不同的任务)。如图1所示,为了能够达到对材料在时域和频谱上的degradation,作者对由10句话和10句歌词混合成的100首自然歌曲分别在时域上做了5次高通滤波(分别是3.5H、2.5Hz、2Hz、1.5Hz和1Hz),在频谱密度进行了5次截止值分别为3、2、1.8、1.5和0.6cyc/kHz的滤波。通过这样的方法,一共产生了1000个刺激材料。
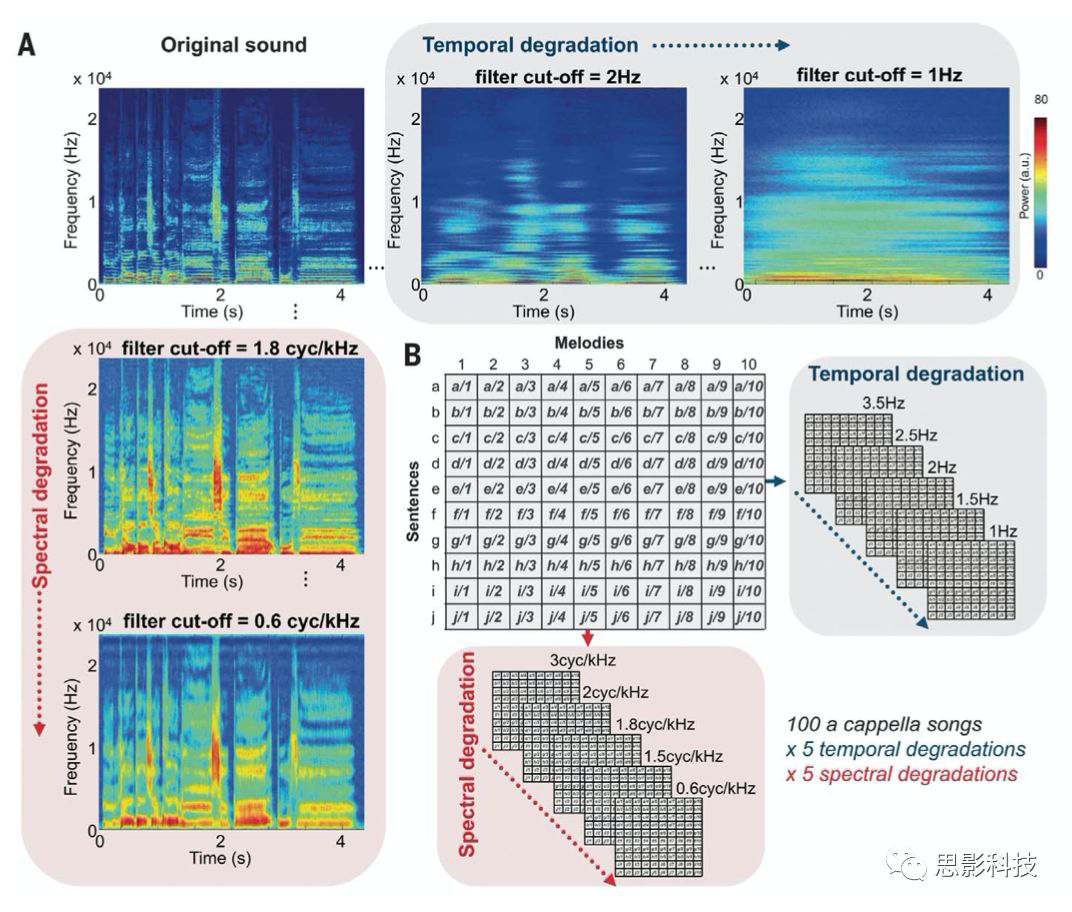
图1 刺激材料的制作流程
作者为了验证上述的实验材料的操作对被试的行为表现是有显著影响的,因此先进行了行为学实验。从图2A中可以看出,被试需要对相同的实验测量进行判断,这些材料分为两类,要么是被进行了时域上的处理,要么是被进行了频谱上的处理。被试在听完材料后,需要判断听到的两个句子的语音内容或者旋律内容是否匹配,并进行按键反应。
对行为学实验中被试对在时域上不同滤波值的声学材料的分辨得分和不同的滤波截止值进行线性回归发现高通滤波的截止值和被试标准后的句子分辨得分显著正相关(图2b中左上淡蓝色),对行为学实验中被试对在频谱上不同截止滤波的声学材料的判断得分和不同的截止值进行线性回归分析发现,对旋律的分辨得分和频谱滤波截止值显著正相关。在进行了2*2的ANOVA分析后发现,正如线性回归结果所示,对频谱滤波的操作显著影响对旋律的分辨得分,但不影响对句子的分辨得分。而对时域的操作则显著影响对句子的分辨得分,对旋律的影响不显著。图2b和图2c分别是法语被试和英语被试对各自语音相同条件的实验操作的反应,可以看出跨语音背景得到的结果是一致的。这说明,在时间-频谱上的不同调制方法对语音和旋律的影响可能是特定的。并且不受到语音差异的影响。
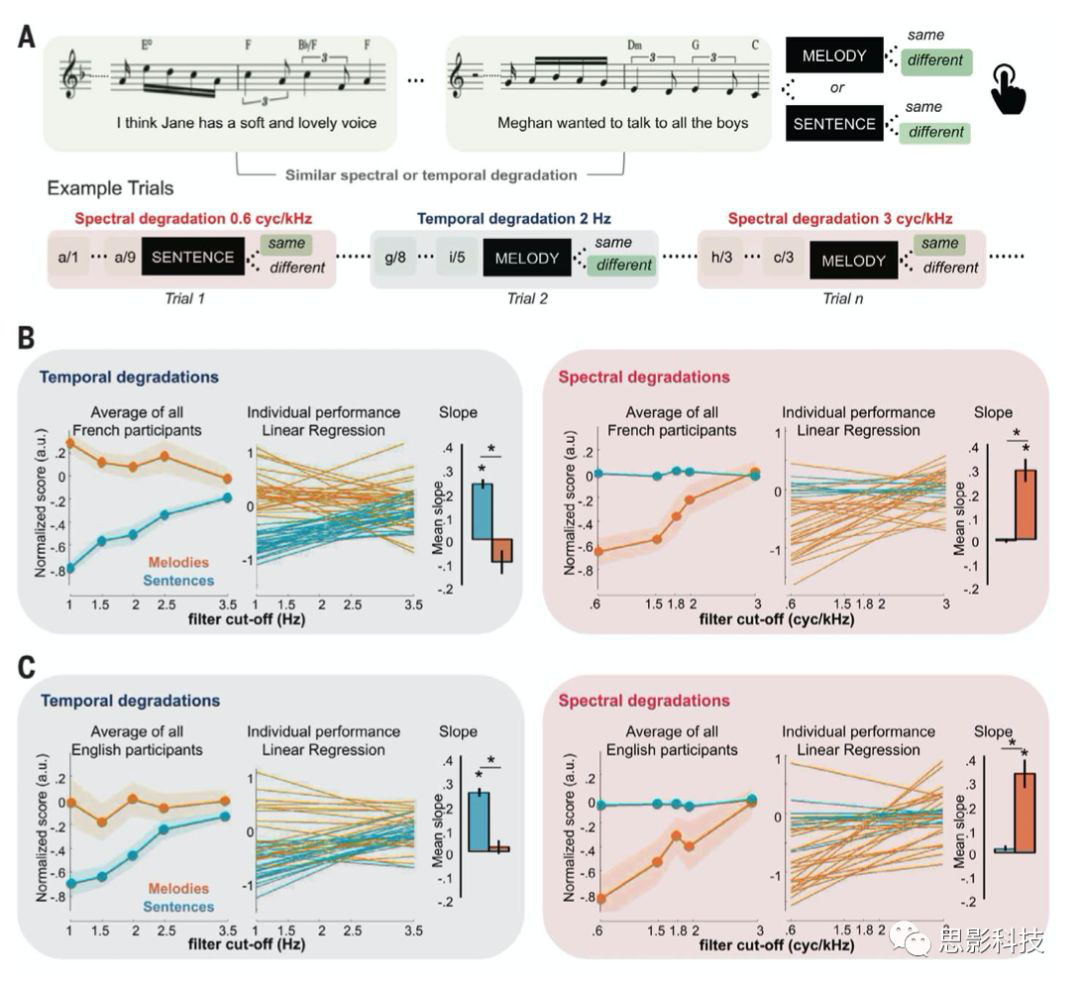
图2 英语和法语被试的行为学实验结果
接着,作者要验证这种在行为学中表现明显的STM rate 调制带来的影响是如何在大脑中表征的。作者进行记录了15名法国人参与过行为实验的法国人的血氧水平依赖(BOLD)活动,实验为Block设计,每个Block 包含5个句子歌曲(Block里要么是受到频谱调制,要么是受到时域调制,两种类型不会出现在同一个block,共110个Block,分为两个run进行,每个run55个Block),这些歌曲要么在时域上受到调制要么在频谱上受到调制。实验过程如图3A所示,为了能够让被试在实验过程中集中注意力,在Block中有两个1-back任务,作者需要对特定trail进行判断,这个歌曲受到的调制影响在之前的句子中是否出现过(对时域调制来说是3.5Hz,对频谱调制来说是3.5cyc/kHz)。
MRI采集参数和处理T1采集参数:
192 层,矢状位采集;TR = 2300 ms; TE = 2.98 ms; flip angle = 9°; matrix size = 256× 256; field of view = 256 × 256 mm2; voxel size = 1 × 1 × 1 mm3。
EPI采集参数:
48层,轴位采集,multiband 采集,factor为6,TR 570ms,2.5mm层厚,matrix size, 84 x84, FOV 210 x 210mm2; voxel size, 2.5 x 2.5 x 2.5 mm3。预处理使用SPM12,时间层校正,头动校正,然后使用两步配准法配入MNI标准空间。最后进行5mm空间平滑。
然后作者进行了全脑的单变量分析,一阶建模建立了时域调制和频谱调制两个contrast,在voxel-wise进行FWE校正。然后是多体素模式识别分析。作者使用了多种方法来进行分类的机器学习。作者首先是建立了对每个句子和每种旋律的一阶GLM,提取取每个句子和旋律的Beta图。然后将其用于机器学习的分类分析,作者使用了the Decoding Toolbox和LibSVM两个工具包进行了基于线性核的分类模型的分析(之所以使用较为简单的线性核,是因为作者认为过于复杂的非线性核或者卷积神经网络可能会导致特征值和非线性驱动的交互影响导致过拟合的出现)。对于每个被试,作者都使用的是个体空间的Beta map进行的分类模型的训练和验证。这是因为配准和空间平滑会带来更多的噪声,可能导致全脑信号的anti-correlation。作者的模型训练是多分类模型,使用每个个体空间所有条件下的Beta map,利用searchlight的方法,以4mm小球在全脑进行分类训练,分类对象是10个旋律或者是10个句子。每次训练都会给这个小球中心的voxel赋值这次预测的准确性,通过searchlight的方法就可以将全脑所有的voxel都进行预测准确性的赋值,使用留一交叉验证进行模型验证。然后每个被试就可以得到针对旋律或者句子进行分类的准确性的map,然后再对这些map进行配准,配准到标准空间中。最后进行group wise的统计检验。通过单样本t检验对两类map进行组水平阈值化(补充图1)。
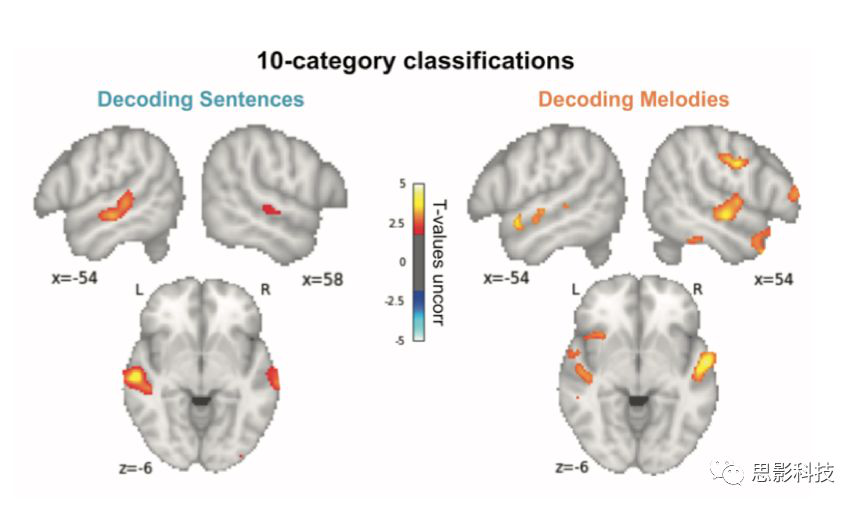
补充图1 能够显著分类10个句子/旋律的团块结果
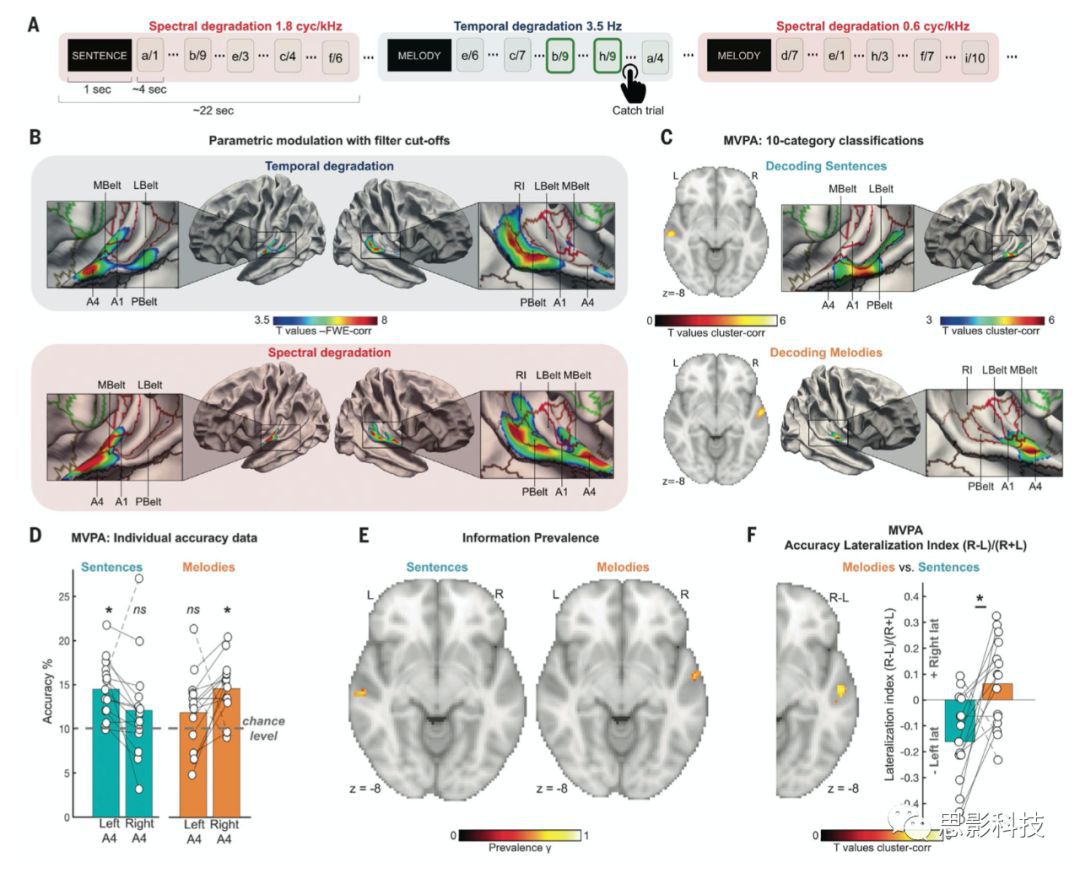
图3 核磁单变量分析结构和多体素模式的分类模型
研究结果
单变量分析发现,处理句子信息或者旋律信息的这些区域位于初级ACs(左右听觉皮层)的外侧,与信息处理的腹侧听觉流相对应,包括Pbelt区和外侧前颞上回(图3B),但两个维度的大脑半球反应均无显著差异(全脑双样本配对t检验;所有p > 0.05)。这说明,单变量分析没有足够的敏感性探测到听觉区域对这两种不同加工对象的反应。多体素模式识别的分类分析发现,句子的神经编码在很大程度上依赖于左A4的神经活动模式,而旋律的神经编码在很大程度上依赖于右侧A4区域的神经活动。从图3D中可以看出,左侧A4和右侧A4区域对句子和旋律的分类的准确性均显著高于机会概率10%,但是对于句子分类而言,左侧A4区域的分类正确率显著高于右侧,而对于旋律的分类,右侧A4显著高左侧A4区域。
同时,为了进一步分析这种分类性是不是在所有被试中都是显著存在的,作者基于颞叶mask进行了information prevalence analysis。对于句子的解码,在左A4中观察到高达70%的概率值(p = 0.02,校正后,这说明在70%以上的被试中可以由左侧A4区域对句子分类的预测达到组水平的预测精度),而在右A4中观察到高达69%的概率值对旋律的解码(p=0.03,校正后,这说明在69%以上的被试中可以有右侧A4区域对旋律分类的预测达到组水平的预测精度,图3E)。最后,作者使用计算偏侧化的方法计算了最后,右半球A4和左半球A4对句子或旋律的分类准确率是否更好。作者计算了准确性评分的偏侧指数[(R- L)/(R + L)](具体操作就是把每一个被试的分类正确率map进行flip,然后对flip后和没flip的图进行相减或者相加,这样得到右侧减去左侧的图和左侧加上右侧的图,然后再对这两张图相除)。
结果发现在A4区域对句子和旋律的分类正确率在相反的方向上存在显著的不对称性(图3F,p < 0.05,全脑水平校正)。可以看出,句子分类正确率的偏侧化指数明显是左侧,而旋律分类正确率的偏侧化指数明显是右侧。这说明,不同分析方法不影响结果的一致性。然后作者测试了左右脑的语音和旋律内容的神经专门化与这两个区域的行为处理之间的关系。通过计算从神经数据分类中提取的混淆矩阵(对于每个被试的全脑,利用上述分析中由searchlight获得的对每个刺激的预测准确率和其本来的标签所构建起来的混淆矩阵,混淆矩阵又称为可能性表格或是错误矩阵。它是一种特定的矩阵用来呈现算法性能的可视化效果,通常是有监督学习用来表征模型效能的方法。其每一列代表预测值,每一行代表的是实际的类别。这个名字来源于它可以非常容易的表明多个类别是否有混淆(也就是一个class是否被预测成另一个class)和从离线记录的行为数据使用相同的分类器对所有trail的行为学数据进行分类所得到的混淆矩阵来进行分析,从而估计由神经数据和行为学数据所得到的对10个句子(要么是10个句子,要么是10个旋律,和任务态分析里是对应的)的分类准确性的不同混淆矩阵之间的线性和非线性统计相关性。
作者使用了NMI来衡量这两组混淆矩阵之间的关系,(NMI衡量的是对一幅图像的了解在多大程度上减少了对另一幅图像的不确定性,这种方法常用于分析聚类结果和真实的社团划分之间的差异,值在0-1之间,这种方法用在这里可以评估行为学构建的一组混淆矩阵数据与神经影像数据所构建的混淆矩阵之间的关系,值越大就说明这两种矩阵间的距离越近)。作者通过searchlight结合上述方法,就可以在全脑每个体素上进行NMI值的赋值,这样的情况下,体素的NMI的值越大,就越代表了由这些体素所构建的预测模型而得到的混淆矩阵和行为学构建的混淆矩阵越相似。作者同样是利用前面所提到的偏侧化方法来处理得到的NMI值的全脑图,对全脑图进行flip,相减和相加,然后相除。这样得到一张偏侧化的图,进行单样本T检验,然后团块水平的校正。结果发现,如图4B所示,由句子刺激建立的NMI图像表现出明显的左侧化,区域为左侧A4听觉区。而由旋律刺激建立的NMI图像表现出明显的右侧化,区域为右侧A4区域。这说明,左侧A4听觉区所表现出的对句子分类正确率的神经响应和行为数据中表现出的分辨能力是显著相关的。而右侧A4听觉区则对行为学中对旋律分辨分数负责。
最后,作者研究了语音和旋律内容的半球化是否与左、右ACs对STMs的声学敏感性差异直接相关。为了研究这个问题,作者首先使用所有trail作为神经影像数据对于句子和旋律的分类准确率进行预测建立模型,通过和上文在分析中所述的相同方法提取出全脑的分类准确率map,然后使用特定频谱变化或者时域的特定频率变化的trail(也就是进行了反应的那些trail,那些trail都是特定的)作为分类对象,使用神经影像数据进行模型预测,得到全脑的分类准确率map。然后对每个被试得到的map进行两样本配对t。
统计结果发现,双侧ACs存在显著的分类正确率差异(左侧和右侧A4区;p < 0.05,cluster wise校正;图4C)。对于句子分类,与频谱调制相比,仅在时域的频率调制上发现左A4区域出现显著的准确性损失(p < 0.001, Tukey校正;所有其他的,p > 0.16,即对特定频率刺激的预测的正确率高于所有trail用于分类的准确率,这里的准确性损伤是所有trail的预测模型相对于特定trail的预测模型而言的),而相反的模式只观察到旋律在右A4区域表现出来,即相对于时域的频率改变,频谱调制带来的正确率损失显著 (p = 0.003, Tukey纠正;其他的,p > 0.5)。在图4c中,在左侧可以看到在淡蓝色的句子分类模型中,左侧A4区域在时域的频率变化中相比于频谱调制出现了显著的正确率下降,而旋律则无显著差异。在右侧的柱状图中可以看出,右侧A4区域对旋律的分类预测在频谱调制下相比于时域的频率调制出现了显著的正确率下降,而句子则未表现出明显差异。这说明,语音和旋律内容的半球化与左、右ACs对STMs的声学敏感性差异直接相关。特定的时域频率的调制和特定的频谱调制在左右ACs尤其是A4区域的神经编码是存在显著差异的。
除此以外,作者还在所有trail的基础上研究了时域频率和频谱的degradation和左右偏侧化的关系。使用了和我们上文中描述的一样的NMI方法,构建出了行为数据对不同类型(句子和旋律)degradation的混淆矩阵和神经影像数据的混淆矩阵,然后计算了NMI,并使用相同的偏侧化计算方法,计算了degradation对行为数据和神经影像数据之间的相关关系的影响。发现,对于句子,NMI在频谱degradation时是偏侧的(t(14) = 2.32, p = 0.03),而在时域degradation时,NMI的偏侧性消失了(t(14) = 0.44, p = 0.66)。相比而言,对于旋律,NMI在时域degradation时表现为右侧化(t(14) = 3.46, p = 0.004),而对于频谱degradation表现为右侧化(t(14) = 0.24, p = 0.80,图4D)。这说明,听觉半球对于spectrotemporal的加工是有不同的编码机制的,并且这种机制特定于时间线索和频谱线索。
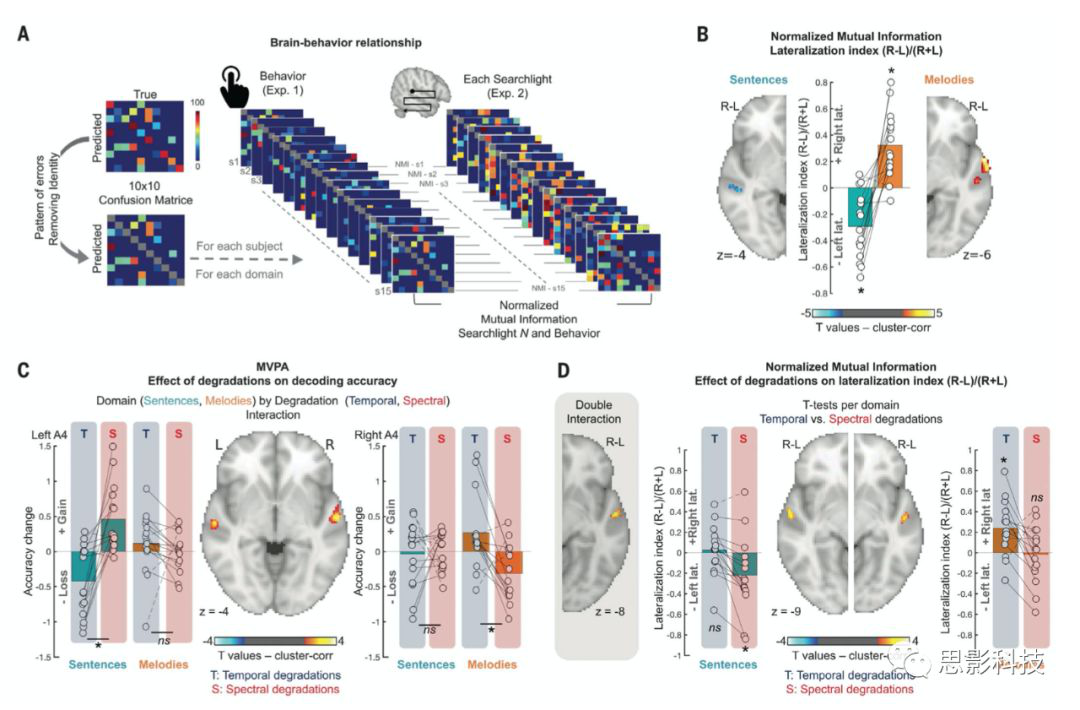
图4 NMI分析结果
总结:
本研究表明,音乐加工和语音加工这两个领域利用了频谱-时间连续体的两个不同方面,在具有偏侧化的两个平行的神经系统中,左右半球的听觉加工对声学线索中频谱-时间信息出现了不同的编码方式,在听觉互补的过程中出现了特异的编码方法,最大限度地提高了各自声学特征的编码效率。
原文:Distinct sensitivity to spectrotemporal modulation supports brain asymmetry for speech and melody
如需原文及补充材料请加微信:siyingyxf 或者19962074063获取,如对思影课程感兴趣也可加此微信号咨询。

欢迎浏览思影的数据处理课程以及数据处理业务介绍。(请直接点击下文文字即可浏览思影科技其他课程,欢迎添加微信号siyingyxf或19962074063进行咨询,仍接受报名,受疫情影响部分课程时间或有调整,报名后我们会第一时间联系):
第六届任务态fMRI专题班(重庆4.8-13)
第二十八届磁共振脑影像基础班(重庆2.24-29)
第十四届磁共振脑网络数据处理班(重庆3.18-23)
第二十届脑电数据处理中级班(重庆3.7-12)
第二十九届磁共振脑影像基础班(南京3.15-20)
第十五届磁共振脑网络数据处理班(南京4.13-18)
第十届脑影像机器学习班(南京3.3-8)
第六届小动物磁共振脑影像数据处理班(3.27-4.1)
第十二届磁共振弥散张量成像数据处理班(南京3.21-26)
第九届磁共振脑影像结构班(南京2.26-3.2)
第八届脑电数据处理入门班(南京3.9-14)
第七届眼动数据处理班(南京4.9-13)
第七届近红外脑功能数据处理班(上海4.2-7)
思影数据处理业务一:功能磁共振(fMRI)
思影数据处理业务二:结构磁共振成像(sMRI)与DTI
思影数据处理业务三:ASL数据处理
思影数据处理业务四:EEG/ERP数据处理
思影数据处理服务五:近红外脑功能数据处理
思影数据处理服务六:脑磁图(MEG)数据处理
招聘:脑影像数据处理工程师(重庆&南京)